






1. 前言
我们都知道Java8的流式操作用起来真的是肥肠爽的,极大的减少代码量,但是其背后的效率如何呢,可能大部分开发人员并没有关心过,但是作为一个具有强烈好奇的程序员,这个事真的很有意思,今天就来一探究竟。
2. 测试
- 本机性能:4核8线程

- 测试代码:
public class ParallelStremAndStream {
private final static long PERSON_NUMBER=500;//分别测试500,50000,5000000
public static void main(String[] args) {
List<Person> persons = init();
testCommonsCollection(persons);
testStream(persons);
testParallelStream(persons);
}
//测试普通集合操作效率
public static void testCommonsCollection(List<Person> persons) {
long start = System.currentTimeMillis();
long ageSum=0;
for (Person person : persons) {
ageSum+=person.getAge();
}
long end = System.currentTimeMillis();
System.out.println("总的年龄为"+ageSum);
System.out.println(PERSON_NUMBER+"个对象集合使用普通集合操作一共花费时间:"+(end-start));
}
//测试stream效率
public static void testStream(List<Person> persons) {
long start = System.currentTimeMillis();
Optional<Long> sumAge = persons.stream().map(Person::getAge).reduce((age1,age2)->age1+age2);
if (sumAge.isPresent()) {
System.out.println("总的年龄为"+sumAge.get());
}
long end = System.currentTimeMillis();
System.out.println(PERSON_NUMBER+"个对象集合使用stream一共花费时间:"+(end-start));
}
//测试parallel stream效率
public static void testParallelStream(List<Person> persons) {
long start = System.currentTimeMillis();
Optional<Long> sumAge = persons.parallelStream().map(Person::getAge).reduce((age1,age2)->age1+age2);
if (sumAge.isPresent()) {
System.out.println("总的年龄为"+sumAge.get());
}
long end = System.currentTimeMillis();
System.out.println(PERSON_NUMBER+"个对象集合使用ParallelStream一共花费时间:"+(end-start));
}
public static List<Person> init(){
List<Person> persons=new LinkedList<Person>();
for(int i=1;i<=PERSON_NUMBER;i++) {
Person person = new Person();
person.setId(String.valueOf(i));
person.setAge(i);
persons.add(person);
}
return persons;
}
}代码结构简单,注释明了,就不具体解说了。
- 测试结果:
(1)数据量为500:
总的年龄为125250 500个对象集合使用普通集合操作一共花费时间:0ms 总的年龄为125250 500个对象集合使用stream一共花费时间:72ms 总的年龄为125250 500个对象集合使用parallel stream一共花费时间:5ms
小数据量的时候,普通集合操作与parallel stream操作性能都很高,而stream操作达到了72ms。此时的数量大小,采用普通集合操作与parallel stream操作都是可以的。
(2)数据量为50000:
总的年龄为1250025000 50000个对象集合使用普通集合操作一共花费时间:3ms 总的年龄为1250025000 50000个对象集合使用stream一共花费时间:74ms 总的年龄为1250025000 50000个对象集合使用parallel stream一共花费时间:9ms
当数据量达到5万时候,三种方式操作时间都相应延长,但是并不明显。
(3)数据量为5000000:
总的年龄为12500002500000 5000000个对象集合使用普通集合操作一共花费时间:118ms 总的年龄为12500002500000 5000000个对象集合使用stream一共花费时间:3840ms 总的年龄为12500002500000 5000000个对象集合使用parallel stream一共花费时间:234ms
当数据量达到500万时候,普通集合操作操作时间较之前的时间增大40倍,stream操作时间较之前的时间增大约52倍,parallel stream操作增大26倍,其增长倍数是最小的。这到底是为什么???更加直观的感受见下图。
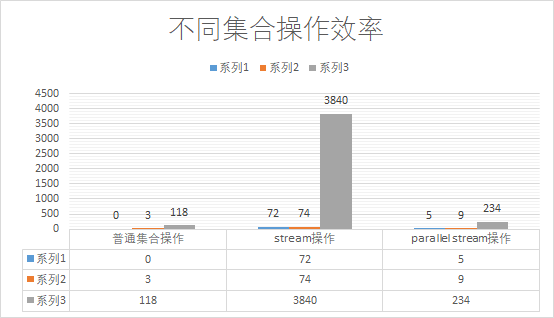
系列1对应的是集合大小为500;
系列2对应的是集合大小为50000;
系列3对应的是集合大小为5000000;
很明显的结论:在4核8线程的环境下,使用普通的集合操作始终都是效率最好的(没有之一),最不应该使用的就是stream操作,而在大数据计算的时候,使用parallel stream操作能够显著提高效率,parallel stream操作在初始化的时候消耗了大量时间,但是其真正计算的时间很少。
具体理论分析:
3. 批量操作
但是,结果真正的是这样么???上述情况确实是真实的,如果我们有很多数据要批量处理,即我们对 stream及parallel stream循环调用,结果又是另外一番情况了:
下面针对parallel stream 做5万,500万数据量做测试:
public static void main(String[] args) {
List<Person> persons = init();
for(int i=1;i<=5;i++) {
//testCommonsCollection(persons);
//testStream(persons);
System.out.println("-----第"+i+"次循环-------");
testParallelStream(persons);//测试parallel stream
}
}集合大小50000的结果:
-----第1次循环------- 总的年龄为1250025000 50000个对象集合使用parallel stream一共花费时间:75ms -----第2次循环------- 总的年龄为1250025000 50000个对象集合使用parallel stream一共花费时间:2ms -----第3次循环------- 总的年龄为1250025000 50000个对象集合使用parallel stream一共花费时间:2ms -----第4次循环------- 总的年龄为1250025000 50000个对象集合使用parallel stream一共花费时间:2ms -----第5次循环------- 总的年龄为1250025000 50000个对象集合使用parallel stream一共花费时间:2ms
结果表明:第一次时间为75ms,以后都稳定在2ms左右。
集合大小5000000的结果:
-----第1次循环------- 总的年龄为12500002500000 5000000个对象集合使用parallel stream一共花费时间:4054ms -----第2次循环------- 总的年龄为12500002500000 5000000个对象集合使用parallel stream一共花费时间:221ms -----第3次循环------- 总的年龄为12500002500000 5000000个对象集合使用parallel stream一共花费时间:217ms -----第4次循环------- 总的年龄为12500002500000 5000000个对象集合使用parallel stream一共花费时间:225ms -----第5次循环------- 总的年龄为12500002500000 5000000个对象集合使用parallel stream一共花费时间:218ms
结果表明:第一次时间为4054ms,以后都稳定在220ms左右。
实际运行表明:
parallel stream 批量操作与stream流批量操作都符合上述规律,即第一次运行较慢,后面的批量操作时间会大幅下降;
在数据量为50000时,stream批量操作与parallel stream 批量操作耗费的时间一致,约2ms,并且与普通的迭代器集合操作的时间也是一致的;
在数据量为5000000时,stream批量操作的稳定时间约170ms,parallel stream 批量操作稳定时间约220ms。
4. 最重要的结论来了:在本测试环境下8线程
不论数据量如何(<500万),一次运行的情况下,效率比较:迭代器>parallel stream>stream
中等数据量约50000时,且批量运行时,效率比较:迭代器=parallel stream=stream(2ms)
大数据量时,约5000000,且批量运行时,效率比较:迭代器(147ms)>stream(170ms)>parallel stream(227ms)
在上述情景下,迭代器操作集合效率似乎都是更胜一筹,那为什么还会有parallel stream,stream的出现呢,其实是他们的使用场景不同,parallel stream,stream更加适合集群、并发场景下使用,且代码简洁;而迭代器适合单机单线程下使用。从Java的版本迭代其实也可以看出,Java已经为大数据,云计算做好了准畚,至于实际开发中还需要结合业务场景选择适合的集合操作方式,盲目追求新异也是不可取的。并不是所有的问题都适合使用并发程序来求解,比如当数据量不大时,顺序执行往往比并行执行更快。毕竟,准备线程池和其它相关资源也是需要时间的。但是,当任务涉及到I/O操作并且任务之间不互相依赖时,那么并行化就是一个不错的选择。通常而言,将这类程序并行化之后,执行速度会提升好几个等级。















 4406
4406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









