






1、vector的作用,实现原理是什么?
我们通常碰到的问题是vector和ArrayList 的区别是什么,那么为了我们更详细的了解vector我们先来了解下Arraylsit;
(1)首先ArrayList是做什么的?
以我的理解ArrayList就是解决数组不能动态扩容问题,或者说简便化程序员对数组的操作;
(2)ArrayList是如何实现这个功能的?
看下他的源码就知道了;创建ArrayList对象的源码:
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
transient Object[] elementData;
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
从上面来创建一个ArrayList其实就是创建了一个对象数组而已,那么同理他的添加删除方法肯定也是对应数组的操作;
添加方法源码:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
由上代码比较多不不一一贴出来了,具体大家可以看下源码,由添加方法大概可以看出来,实现动态数组的原理就是把原来数组里的内容复制到新创建的数组里面去;
(3)我们已经了解了 ArrayList的功能,那么我们再来看看vector是怎么实现的,和ArrayList又有什么关系?同样咱们还是从源码上了解
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
从源码上我们可以看到vector还是通过创建数组实现其功能的,那么既然vector与ArrayList功能一样,那岂不是多次一举呢,肯定有不同的地方,那么我们再看vector的其他方法,终于我们发现其根本了:
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
public synchronized boolean removeElement(Object obj) {
modCount++;
int i = indexOf(obj);
if (i >= 0) {
removeElementAt(i);
return true;
}
return false;
}
原来在vector所有元素操作的方法上都加了一个关键字synchronize;
(4)Synchronize:可修饰变量和方法,修饰的变量和方法都是线程安全的,此关键字是通过锁定一块区域,外界的线程需要访问此区域时必须获得该区域的锁才能执行该区域的代码;
(5)结论:vector就是为了解决ArrayList的线程安全问题,通过源码我们能看到AraayList和vector的区别不过世一个关键字的sychronize的区别,那么他们之间的区别也就在加不加sychronize关键字定义变量和方法的区别;
一:vector是线程安全的(他使用了sychronize),ArrayList不是线程安全的;
二:vector相对于ArraList的性能肯定要低,sychronize只能一个执行后下一个获得锁才能执行,而Arraylist是多个线程同时执行的;
2、HashTable的作用,实现原理是什么?
通常我们会拿HashTable和HashMap做比较;
(1)HashMap 的实现原理?
HashMap是由数组和链表结合来实现数据存储的;
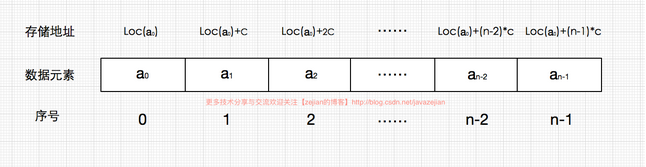
数组特点:的存储区间是连续性的,寻址是通过下标来进行数据查找,正因为每个数据都有了坐标,那么数组带来的好处就是寻址非常方便,但是添加、删除数据困难,因为一旦删除添加一个坐标的数据整个数组的坐标都会发生变化;
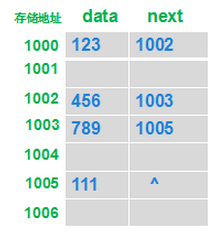
链表的特点:链表在内存里面是无序进行存储的,数据是通过线性关联进行查找的,数据A只记录A本身的数据和B数据的位置,数据查找只能通过对链表的每个数据进行遍历匹配,由于每个数据只要记录本身数据和下一个数据关联性的特性,使得链表添加删除数据格外的方便,因为添加或删除数据不会影响到链表的其他数据,只需要对其数据和关联的位置进行改变即可;
而HashMap是结合了数组和链表的特点,实现的一种数据存储方式使得,数据在查找和删除、添加时都有优势;
HashMap通过自己的算法key.hashcode 得到一个数组下表,把对应的值通过自己封装成(Entry 属性有kye,value,nex)存储到对应下表的数组中,重复的下标数据通过链表来进行存储,最后put进来的存到数组中,然后改数据会记录上一个数据的位置;
比如:上图中的数据26、126都是存储在下表为10的数组中,126这个数据其实是比26要先存储进来,当26存储进来之前,获取数据下标为10的数据结果是126 ,当26存储进来后,取数据下标为10的数据结果就成了26,但26数据的nex属性会指向126数据的位置;
(2)HashTable和HashMap的不同之处?
通过HashTable和HashMap的源码可以观测到他们的不同之处也就至于对应方法上加了synchronize关键字,也就是说HashTable是线程同步的;
Synchronize:可修饰变量和方法,修饰的变量和方法都是线程安全的,此关键字是通过锁定一块区域,外界的线程需要访问此区域时必须获得该区域的锁才能执行该区域的代码;
(3)结论:
一:HashTable是线程安全的(他使用了sychronize),HashMap不是线程安全的;
二:HashTable相对于HashMap的性能肯定要低,sychronize只能一个执行后下一个获得锁才能执行,而HashMap是多个线程同时执行的;
三:HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行;
(4)让HashMap也变成线程安全的方法
HashMap可以通过下面的语句进行同步:
Map m = Collections.synchronizeMap(hashMap);















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









