









参考文档:http://wenku.baidu.com/view/341e42bd02d276a200292e6c.html
这个计算器源码我上传到csdn上来,共享出来供有兴趣的同学参考 http://download.csdn.net/detail/chunyexiyu/7847539
之前大学的时候,编译原理课程有一个做计算器的任务,当时没有做,只顾做一个漂亮计算器界面。
想来当时是买椟还珠了,有点小遗憾,觉得编译原理没有实践,没有理解透彻。
趁这周末有空,就把编译器重新做一做,下面是做出来的效果:
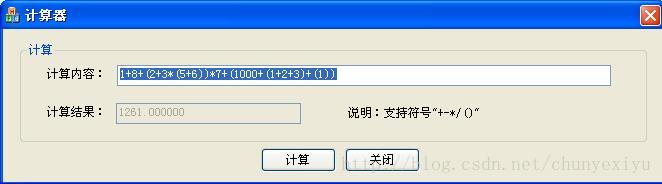
参照百度文库中的文章,实现词法分析器,和语法分析器
1. 界定实现范围
考虑主要是简单实践,所以只实现 正整数与浮点数的 + - * / ()
2. 实现词法分析器
分析出这几种词语,其他情况,认为是异常
enum EnumTokenType
{
enumTokenType_none= -1, // 未定义
enumTokenType_integer = 0, // 数字
enumTokenType_float= 1,// 浮点数
enumTokenType_add= 2,// 加号
enumTokenType_sub= 3,// 减号
enumTokenType_mul= 4,// 乘号
enumTokenType_div = 5,// 除号
enumTokenType_lbt = 6,// 左括号
enumTokenType_rbt = 7,// 右括号
};
struct CalcToken
{
EnumTokenType type;
TokenData data;
};
union TokenData
{
TCHAR cChar;
int nInteger;
double fFloat;// 数字 double: 精度52Bit - 十进制15-16位精度
};
3. 实现语法分析器
思路: 使用分块思路把内容按优先级分块,先使用'(' 和 ')'分块,然后使用'*' 和 '/'号分块,分块结束;计算时从左往右计算就可以了。
匹配内容:
exp -> term
exp -> term + exp +-从左到右依此执行
exp -> term - exp
term -> factor
term -> factor * term */次优先,内部先左后右
term -> factor / term
factor -> number
factor -> (exp) ()最优先
// 思路: 使用分块思路把内容按优先级分块,先使用()分块,然后使用*/号分块,分块结束;计算时从左往右计算就可以了。
enum EnumProcType
{
enumProcType_content= 0,// 未分解内容
};
struct ProcSubNode;
struct ProcNode
{
EnumProcType procType;
std::list<ProcSubNode>tokenlist;
};
enum EnumProcSubNodeType
{
enumProcSubNodeType_token = 0,
enumProcSubNodeType_node = 1,
};
struct ProcSubNode
{
EnumProcSubNodeType type;
ProcNode node;
CalcToken token;
};
class CSyntaxNodeAnalysis
{
public:
bool Analysis(IN const std::vector<CalcToken>& tokenArray, OUT double& fResult);
bool ProcBracket(ProcNode& node); // 使用括号分块
bool ProcMulAndDiv(ProcNode& node); // 使用*/号分块
bool CalcTerm(const ProcNode& node, double& result);
public:
// 测试函数
bool ShowNode(const ProcNode& node);
};
这个计算器源码我上传到csdn上来,共享出来供有兴趣的同学参考。
http://download.csdn.net/detail/chunyexiyu/7847539
Owed by: 春夜喜雨 http://blog.csdn.net/chunyexiyu 转载请标明来源
















 1468
1468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











