






前提:
1.我使用的hadoop是hadoop-2.3.0-cdh5.1.0.tar
2.以下是我的hadoop核心配置文件的配置:
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/yinkaipeng/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
</configuration>hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/data/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>在hadoop2.0 中如果不配置zookeeper,只需将你将你的datanode加入slaves文件中即可。
hadoop集群配置好后,然后就是使用eclipse进行连接啦!
好的,我使用的是:hadoop-eclipse-plugin-2.2.0,从网上下载的。
下面开始我们开始工作。
启动hadoop集群
将hadoop-eclipse-plugin-2.2.0拷贝到eclipse的plugins 目录下,启动eclipse。

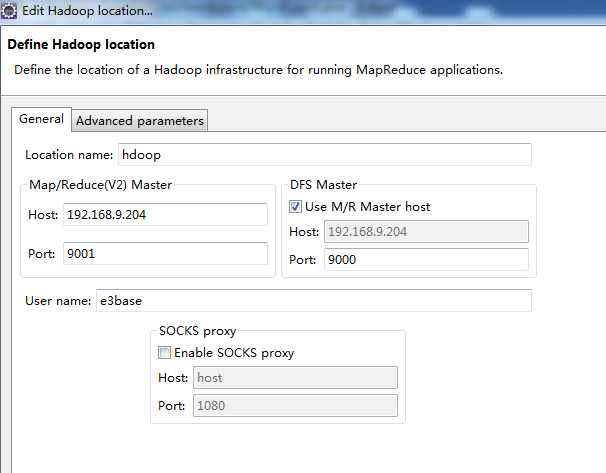
如现在就进行连接的话不会成功的。因为我们用的是Windows所以还需要进行以下步骤:
将电脑当前用户名改为hadoop的启动用户名
eclipse连接hadoop源码目录,将hadoop-common-2.2.0-bin-master的bin目录考到eclipse的workspace



注:上面hadoop目录为我从Linux系统上下载的解压后的hadoop。
到这里操作hdfs就没问题了,如果要运行mapreduce还会报错,进行以下两步:
1.将hadoop源码中的org.apache.hadoop.io.nativeio加到项目中,并进行以下修改:

2.在我们的mapreduce的main函数中注入hadoop本地目录地址环境变量。

ok!这下就可以在Windows上进行hadoop集群的mapreduce在线调试了!
如果有问题可以留言交流哦!共同学习共同进步!















 4965
4965











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









