







 本文详细介绍了垃圾回收中的标记-压缩算法,包括其基本思想、实现步骤和测试过程。通过计算活动对象的移动地址、更新引用以及移动对象,实现了内存的高效压缩。测试结果显示,算法成功地保留了对象间的引用关系,并有效清理了垃圾对象。
本文详细介绍了垃圾回收中的标记-压缩算法,包括其基本思想、实现步骤和测试过程。通过计算活动对象的移动地址、更新引用以及移动对象,实现了内存的高效压缩。测试结果显示,算法成功地保留了对象间的引用关系,并有效清理了垃圾对象。
本文将实现垃圾回收算法中的标记-压缩算法。
1.标记-压缩算法简介
标记-压缩算法的基本思路:
标记阶段。该阶段与标记-清除算法中的标记算法一样。
遍历根对象及其引用的对象。假设每个对象都有个标记位
flag,对根对象集合中的每个根对象,从根对象出发,对可以访问到的每个对象的标记位flag设为1(活动对象)。压缩阶段。该阶段分3步,依次是:
计算当前活动堆中活动对象移动后的地址。该步骤需要从堆的开始遍历堆,对每个标记为活动的对象,计算其移动后的地址并记住。仍然可以把堆当做一个链表来遍历。
更新到活动对象的引用。该步骤是从根对象出发,遍历根对象所引用到的每个对象,更新根对象到它的引用。即:如果根对象的某个字段引用了一个活动对象,那么要把该字段的值更新为它所引用的活动对象移动后的地址。
若对象
obj有字段b,该字段当前引用的对象的地址为为B,B移动后的地址为newB,那么需要执行如下操作:
obj->b = newB移动活动对象。该步骤需要遍历堆,从堆的开始寻找活动对象,然后往堆的开始地址方向移动,让活动对象都挨在一起存放在堆一侧,空闲空间集中在堆的另一侧,以达到压缩的目的。
标记-压缩算法的优点是垃圾回收在当前活动堆中进行,不需要借助另外的堆,充分利用了内存空间。缺点是压缩阶段需要2次遍历堆,1次遍历根对象及其引用的对象,比较耗时。
压缩阶段的前两个步骤涉及到对象移动后的地址,我们需要记住每个活动对象移动前后地址的对应关系。可以借用一张表来解决,如:
| 移动前的地址 | 移动后的地址 |
|---|---|
| 0x00250FF8 | 0x00250FE4 |
| 0x00251010 | 0x00250FFC |
| 0x00251040 | 0x00251018 |
表格的创建是在第一步完成的,第二步需要根据移动前的地址从表格中查找移动后的地址。该方法的缺点是需要多次搜索表格,效率低。
可以把移动后的地址作为对象的一个字段,这样就可以直接获取活动对象移动后的地址。即把对象的结构改为如下:
typedef struct _Object {
char flag;
ushort length;
char* new_addr; // 移动后的地址
char* fields;
}Object;缺点就是每个对象多占用了4个字节的空间(对于32位机器)。本文中采用该方法来查找移动后的地址。
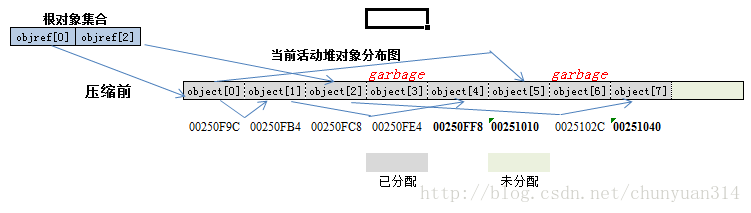
以下是该算法操作前后,当前活动堆中的对象分布示意图

2.算法实现
标记算法此处省略,参考上篇文章。标记步骤中会把活动对象的flag字段设为1。
2.1 计算堆中活动对象移动后的地址
参考如下代码:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1572
1572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









