






接着上篇博客《用Scrapy抓取豆瓣小组数据(三)》,http://my.oschina.net/chengye/blog/124162
处理抓取的数据
我抓取了豆瓣一千多个小组的首页,获取的内容包括名称,成员数目,小组链接以及相关友情小组和推荐小组。Scrapy导出的数据格式可以是json/xml/csv等,我这边用了json格式,每个小组数据的格式如下:
{
"groupName": "\u5e2e\u52a9\u5927\u5c71\u91cc\u7684\u5b69\u5b50",
"groupURL": "http://www.douban.com/group/16533/",
"RelativeGroups": [
"http://www.douban.com/group/henisiben/",
"http://www.douban.com/group/HOWPROJECT/",
"http://www.douban.com/group/225202/",
"http://www.douban.com/group/334177/",
"http://www.douban.com/group/gesanghua/",
"http://www.douban.com/group/J/",
"http://www.douban.com/group/17551/",
"http://www.douban.com/group/wutaishan/",
"http://www.douban.com/group/72790/",
"http://www.douban.com/group/ChindiaIndia/",
"http://www.douban.com/group/74982/",
"http://www.douban.com/group/119384/"
],
"totalNumber": "5833"
}由于是要进行网络分析,假设每个小组就是一个节点(vertex),如果任意两个小组是相关小组(通过RelativeGroups来判断),则两个节点相连接(edge)。所以处理脚本要做的事情,第一生成节点的列表,第二生成节点间的连接。要注意的是对抓取的的重复数据进行清理,并且保证每个连接两端的节点都是有效的。
偷懒用javascript处理了下,然后打印出一个gml格式的文件,用于下一步分析。 GML格式的非常简单,就是一个node列表加上edge列表。定义node时其实只有id是必填项,其他属性都可以自定义的。
graph
[
comment "Douban group graph"
directed 0
node
[
id 1
label "帮助大山里的孩子"
size 5833
url "http://www.douban.com/group/16533/"
]
node
[
id 2
label "加入这个组你就会变聪明"
size 3689
url "http://www.douban.com/group/congming/"
]
.....
edge
[
source 1
target 2
]
]在Gephi中可视化处理网络
Gephi是一款很流行复杂网络可视化软件,我就用它打开前面生成的GML文件,然后可以对节点进行配色,分类以及布局。具体就不讲了,最后得到的网络图是这个模样的。 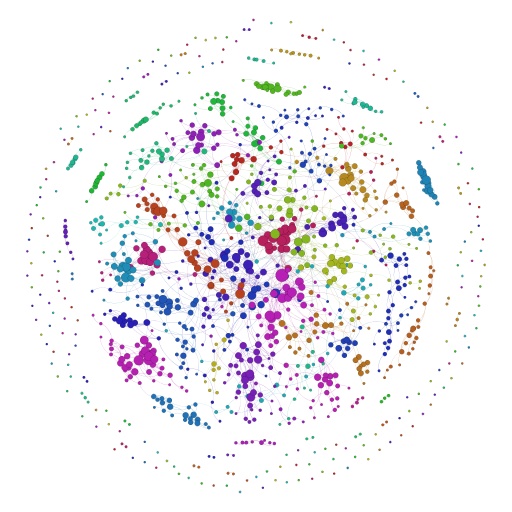
节点越大说明小组的连接个数越多,颜色代表着不同的小组类型(用Gephi的自带算法分类的)。下面这张图这种我划出了4个不同的区域,代表着不同类型的小组,有人能猜到分别是什么类型的小组吗?可以告诉你是哪四种:蕾丝小组,Gay小组,手工小组,美容小组。
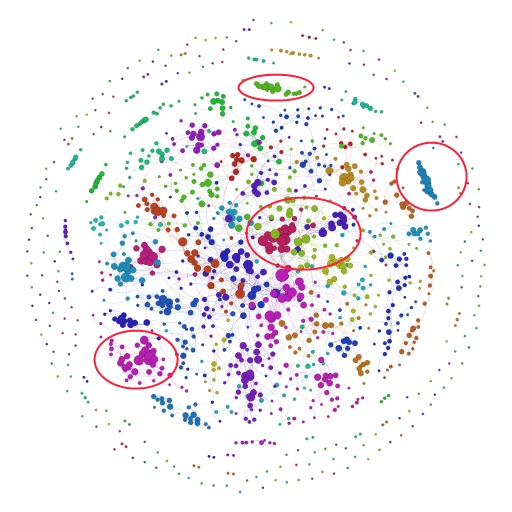
Have Fun~















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









