






好程序员大数据学习路线分享Scala分支和循环
3.3. 条件表达式
表达式:一个具有执行结果的代码块。结果是具体的值或者()
表达式的思考方式:以表达式为中心的编程思想
1.表达式和语句的区别:表达式有返回值,语句被执行。表达式一般是一个语句块,执行后,返回一个值
2.不使用return语句,最后一个表达式即返回值
if/else表达式有值,这个值就是跟在if或者else之后的表达式的值
object ConditionDemo {
def main(args: Array[String]){
var x = 1
//将if/else表达式值赋给变量y
val y = if (x > 0 ) 1 else -1
println(y)
//支持混合型表达式
//返回类型是Any
val z = if(x>0) "success" else -1
println(z)
//如果缺失else,相当于if(x>2) 1 else ()
//返回类型是AnyVal
//如果进行类型判断和转换,可以使用:
//var b = if(m.isInstanceOf[Int]) m.asInstanceOf[Int] else 0
val m = if(x>2) 1
println(m)
//在scala中,每个表达式都有值,scala中有个unit类,写作(),相当于Java中的 void
val n = if(x>2) 1 else ()
println(n)
//if 嵌套
val k= if(x<0) 0 else if (x>=1) 1 else -1
println(k)
}
执行结果:

Scala的的条件表达式比较简洁,例如:
注意:1,每个表达式都有一个类型
2,条件表达式有值
3,混合型表达式,结果是Any或者AnyVal
4,scala没有switch语句
3.4. 块表达式
object BlockExpressionDemo {
def main(args: Array[String]){
var x = 0
//在scala中,{}中可以包含一系列表达式,块中最后一个表达式的值就是块的值
val res = {
if (x < 0) {
-1
} else if (x >= 1) {
1
} else {
"error"
}
}
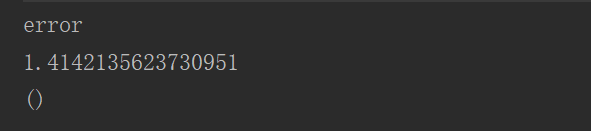
println(res)
val x0 = 1
val y0 = 1
val x1 = 2
val y1 = 2
val distance = {
val dx = x1 - x0
val dy = y1 - y0
Math.sqrt(dx*dx+dy*dy)
}
println(distance)
//块语句,最后一句是赋值语句,值是unit类型的
var res2 = {
val dx = x1 - x0
val dy = y1 - y0
val res = Math.sqrt(dx*dx+dy*dy)
}
println(res2)
}
}
执行结果:
注意:
1,块表达式的值是最后一个表达式的值
2,赋值语句的值是unit类型的,
3.5. 循环
在scala中有for循环和while循环,用for循环比较多
for循环语法结构:for (i <- 表达式/数组/集合)
while (条件语句){表达式}
do{ 表达式}while()
object ForDemo
def main(args: Array[String]){
//每次循环将区间的一个值赋给i
for( i <- 1 to 10)
println(i)
//for i <-数组
val arr = Array("a", "b", "c")
for( i <- arr)
println(i)
val s = "hello"
for(i <- 0 until s.length){
println(s(i))
}
// 或者
// for(c <- s)println(c)
// 或者
// for(i <- 0 until s.length){
// println(s.charAt(i))
//使用了隐式转换,把字符串变成一个ArrayCharSequence
// }
//高级for循环
for(i <- 1 to 3 ; j<- 1 to 3 if i != j)
print((10*i + j) + "")
println()
//for推导式,如果for循环的循环体以yeild开始,则该循环会构建出一个集合或者数组,每次迭代生成其中的一个值。
val v= for ( i <- 1 to 10 )yield i*10
println (v)
//也可以借助函数由初始数组生成一个新的数组
val arr1 = Array(1,2,3,4,5,6,7,8,9)
val arr2 = arr.map(_*10)
val arr3 = arr.filter(_%2==0)
}
}















 920
920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









