






昨晚在网易云课堂上看到了这个爬虫教程,是个基础入门教程,看了几节课,按照示例也去爬了一下新闻标题。
一、课程截图:
- anaconda里面集成了很多关于python科学计算的第三方库,主要是安装方便,而python是一个编译器,如果不使用anaconda,那么安装起来会比较痛苦,各个库之间的依赖性就很难连接的很好(百度知道)
- infolite可以方便的找到css的定位,只不过我并没有在chrome商店里找到。
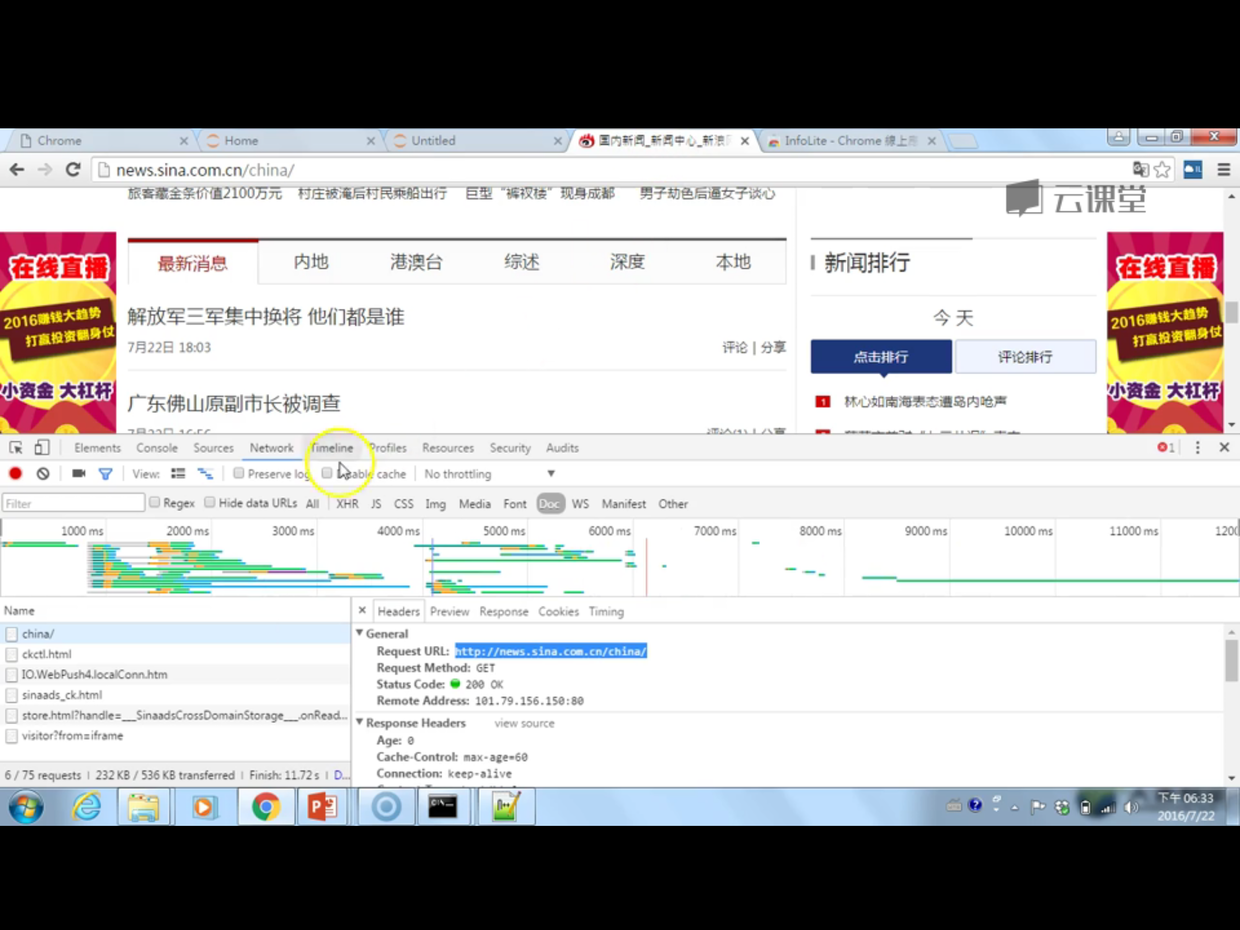
- chrome监视器,network——>doc的使用:
- 老师给的demo:
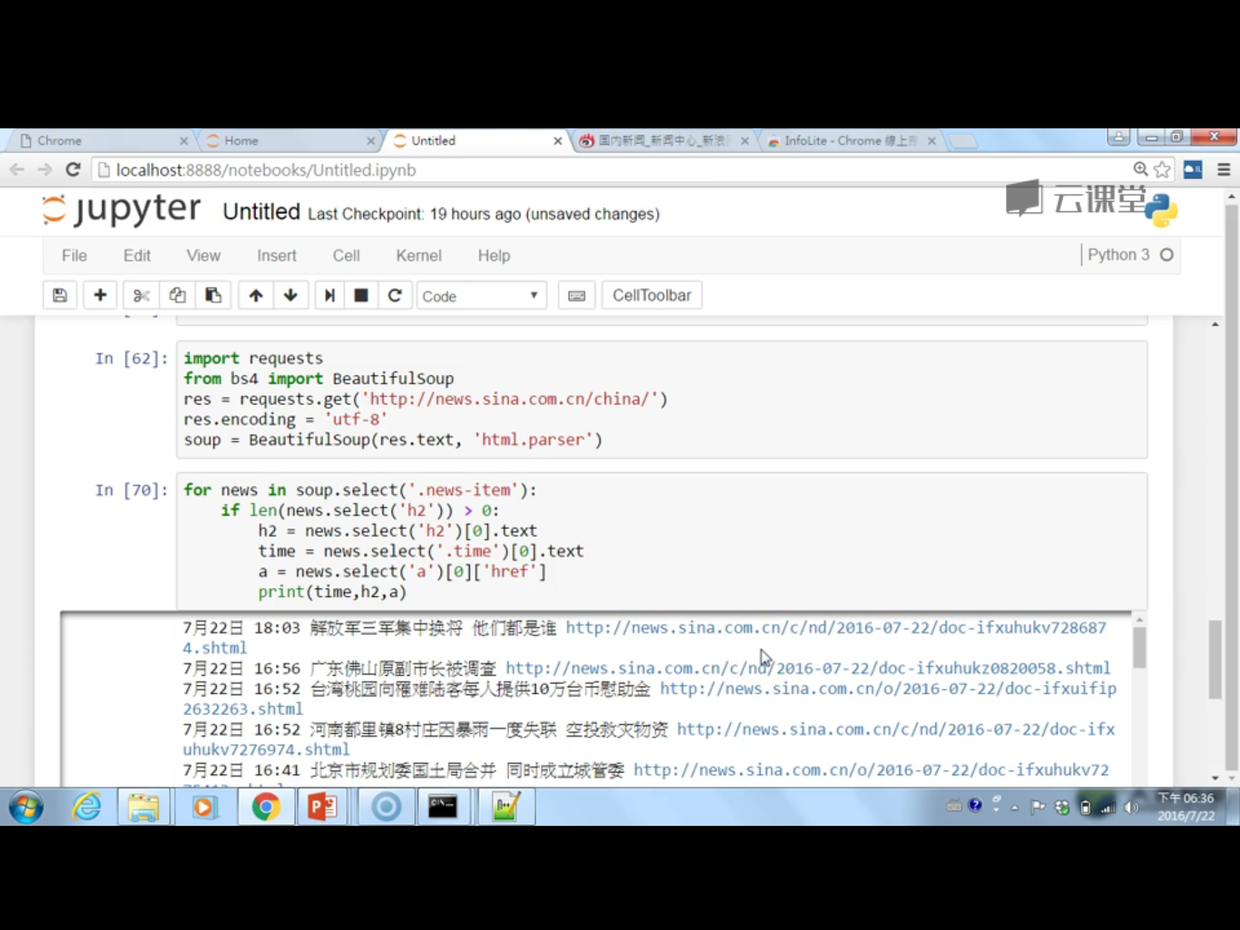
二、我自己按照示例写第一个爬虫:
上代码:
- #2016-12-31 16:34:05
- import requests
- from bs4 import BeautifulSoup
- res = requests.get('http://news.sina.com.cn/china')
- res.encoding = 'utf-8'
- soup = BeautifulSoup(res.text,'html.parser')
- part = soup.select('.news-item ')
- for i in part:
- if len(i.select('h2'))>0:
- news_h2 = i.select('h2')[0].text
- news_time = i.select('.time')[0].text
- news_a = i.select('a')[0]['href']
- print (news_h2)
- print (news_a)
- print (news_time)
- print ('-----------------------------------')
- # res1 = requests.get('http://jw.dhu.edu.cn')
- # res1.encoding = 'utf-8'
- #
- # soup1 = BeautifulSoup(res1.text,'html.parser')
- #
- # for i in soup1.select('.fields pr_fields'):
- # if len(i.select('a')) > 0:
- # print ('11')
- # news_number = i.select('.Article_Index').text
- # news_h = i.select('a')[0].text
- # news_href = i.select('href')[0]['href']
- # print (news_number)
- # print (news_h)
- # print (news_href)
说明:没有注释的地方都是没有问题的,但是下面再想爬取教务处主页的时候,出了点小问题,学艺不精,也没能解决掉。
跑一下代码:不同时间运行出来的结果自然不一样
- D:\Python27\python.exe F:/网站/爬虫/test.py
- 全国铁路预计元旦假期首日发送旅客1008万人次
- 12月31日 15:23
- -----------------------------------
- 深圳休闲娱乐场所将禁止吸烟
- 12月31日 14:19
- -----------------------------------
- 大量内地客户赴香港买保险 业务员:累得想睡觉
- 12月31日 14:12
- -----------------------------------
- 海口火山口现神秘土坡 如旧书堆叠有青花瓷碎片
- 12月31日 13:55
- -----------------------------------
- 大陆封杀55名台湾艺人?台媒:文化部否认
- 12月31日 13:44
- -----------------------------------
- 南非官员赴台北:发言人叫嚣试行“平行外交”
- 12月31日 13:19
- -----------------------------------
- 许勤任深圳市委书记 曾被称最具高科技知识市长
- 12月31日 12:15
- -----------------------------------
- 我国明日将对外发布南沙三大岛礁海洋环境预报
- 12月31日 11:47
- -----------------------------------
- 江苏元旦假期晴暖如春 多地遭“跨年雾霾”
- 12月31日 10:58
- -----------------------------------
- 下月将上演四大天象 金星月亮低空相约肉眼可见
- 12月31日 15:36
- (其实这个地方还有很多呢,先略去了)
- Process finished with exit code 0
三、还有问题:
- 这个地方一改就出问题了,这个应该是python的语法问题吧?其实我还没搞懂python的语法呢。。。
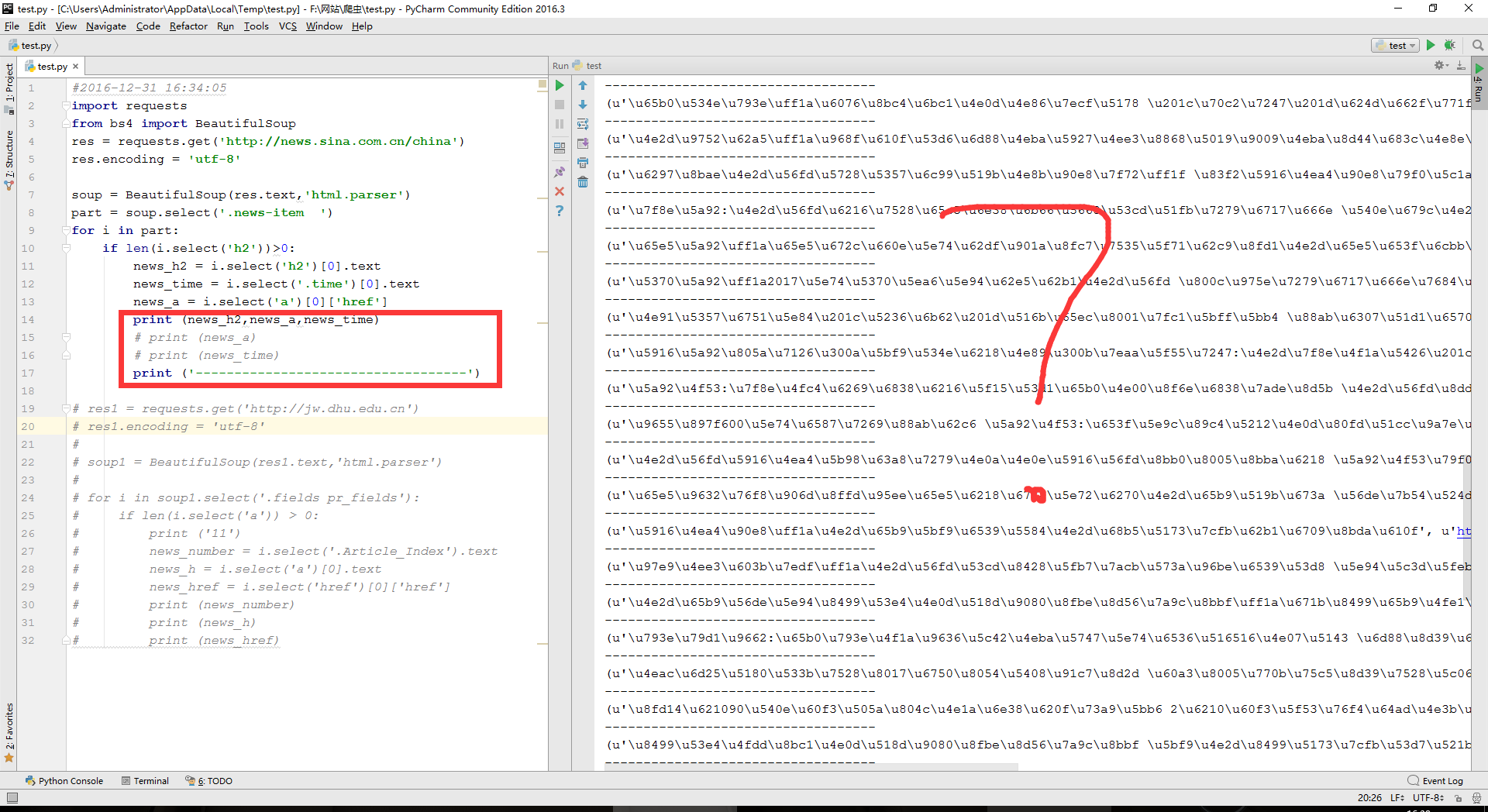
- 第二个自然就是为什么爬取另外一个网站时总是报错,在之后练习爬虫的时候还是要注意这个问题。
所以总结一下一句话:第一次爬虫成功了很有成就感,但是爬虫之博大精深又不是一下子就能搞完的,BeautifulSoup4下次我们再见。
@firstmiki 2016年12月31日16:44:29














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









