






1:令人惊讶的CLI
刚部署好spark1.1就迫不及待地先测试CLI(bin/spark-sql),对于习惯了sql命令行的本人,失去了shark后,对于sparkSQL1.0一度很是抵触(其实对于开发调试人员来说,spark-shell才是利器,可以很方便地使用各个spark生态中的组件)。急切中,没有关闭hive metastore服务,然后一个bin/spark-sql就进入了命令行,然后通过hive metastore就可以直接对hive进行查询了:
spark-sql> use saledata;
//所有订单中每年的销售单数、销售总额
spark-sql> select c.theyear,count(distinct a.ordernumber),sum(b.amount) from tblStock a join tblStockDetail b on a.ordernumber=b.ordernumber join tbldate c on a.dateid=c.dateid group by c.theyear order by c.theyear;
运行结果:
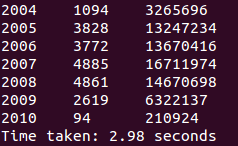
1.1 CLI配置

这时就可以使用HQL语句对hive数据进行查询,另外,可以使用COMMAND,如使用set进行设置参数:默认情况下,sparkSQL shuffle的时候是200个partition,可以使用如下命令修改这个参数:
基本上,在CLI可以使用绝大多数的hive特性。

注意不要将hive.server2.thrift.bind.host配置能localhost,不然远程客户端不能连接。

然后,对tblstock进行下面操作:

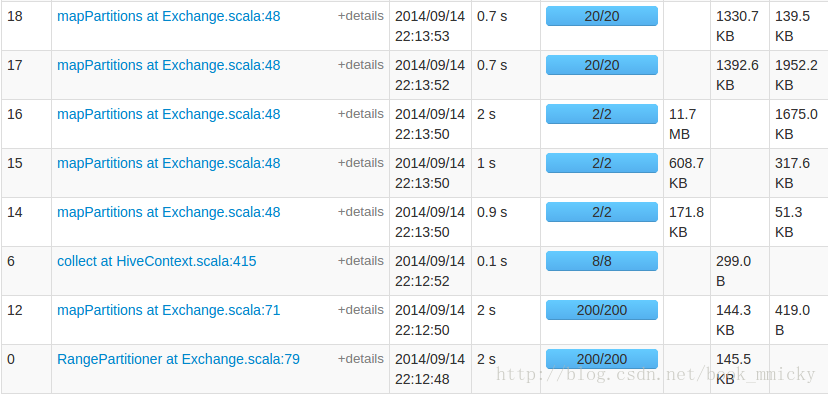
因为首次操作,所以统计花了11.725秒,查看webUI,tblStock已经缓存:

然后启动另外一个远程连接,切换到hadoop1,
启动bin/beeline,用!connect jdbc:hive2://hadoop2:10000
连接ThriftServer,然后直接运行对tblstock计数(注意没有进行数据库的切换):

用时
0.664秒,再查看webUI中的stage:

Locality Level是PROCESS,显然是使用了缓存表。
如需更详细的信息,请参照:
HiveServer2 Clients。
在使用CLI前,要先启动hive metastore;而CLI的配置非常简单,在conf/hive-site.xml中之需要指定hive metastore的uris就可以使用了。现在要在客户端wyy上使用spark-sql,配置conf/hive-site.xml如下:
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop3:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
</configuration>
1.2 CLI命令参数
通过
bin/spark-sql --help可以查看CLI命令参数:
[hadoop@hadoop3 spark110]$ bin/spark-sql --help
Usage: ./bin/spark-sql [options] [cli option]
CLI options:
-d,--define <key=value> Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B
--database <databasename> Specify the database to use
-e <quoted-query-string> SQL from command line
-f <filename> SQL from files
-h <hostname> connecting to Hive Server on remote host
--hiveconf <property=value> Use value for given property
--hivevar <key=value> Variable subsitution to apply to hive
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file
-p <port> connecting to Hive Server on port number
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the
console)
其中[options] 是CLI启动一个SparkSQL应用程序的参数,如果不设置--master的话,将在启动spark-sql的机器以local方式运行,只能通过http://机器名:4040进行监控;这部分参数,可以参照
Spark1.0.0 应用程序部署工具spark-submit 的参数。
[cli option]是CLI的参数,通过这些参数,CLI可以直接运行SQL文件、进入命令行运行SQL命令等等,类似以前的shark的用法。需要注意的是CLI不是使用JDBC连接,所以不能连接到ThriftServer;但可以配置conf/hive-site.xml连接到hive的metastore,然后对hive数据进行查询。
1.3 CLI使用
启动spark-sql:
bin/spark-sql --master spark://hadoop1:7077 --executor-memory 3g
在集群监控页面可以看到启动了SparkSQL应用程序:
SET spark.sql.shuffle.partitions=20;
2:ThriftServer
ThriftServer是一个JDBC/ODBC接口,用户可以通过JDBC/ODBC连接ThriftServer来访问SparkSQL的数据。ThriftServer在启动的时候,会启动了一个sparkSQL的应用程序,而通过JDBC/ODBC连接进来的客户端共同分享这个sparkSQL应用程序的资源,也就是说不同的用户之间可以共享数据;ThriftServer启动时还开启一个侦听器,等待JDBC客户端的连接和提交查询。所以,在配置ThriftServer的时候,至少要配置ThriftServer的主机名和端口,如果要使用hive数据的话,还要提供hive metastore的uris。
2.1 ThriftServer配置
通常,ThriftServer可以在conf/hive-site.xml中定义以下几项配置,也可以使用环境变量的方式进行配置(环境变量的优先级高于hive-site.xml)。
下面是在实验集群中hadoop2上启动ThriftServer的hive-site.xml配置:
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop3:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
<property>
<name>hive.server2.thrift.min.worker.threads</name>
<value>5</value>
<description>Minimum number of Thrift worker threads</description>
</property>
<property>
<name>hive.server2.thrift.max.worker.threads</name>
<value>500</value>
<description>Maximum number of Thrift worker threads</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
<description>Port number of HiveServer2 Thrift interface. Can be overridden by setting $HIVE_SERVER2_THRIFT_PORT</description>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop2</value>
<description>Bind host on which to run the HiveServer2 Thrift interface.Can be overridden by setting$HIVE_SERVER2_THRIFT_BIND_HOST</description>
</property>
</configuration>
2.2 ThriftServer命令参数
使用
sbin/start-thriftserver.sh --help可以查看ThriftServer的命令参数:
[hadoop@hadoop3 spark110]$ sbin/start-thriftserver.sh --help
Usage: ./sbin/start-thriftserver [options] [thrift server options]
Thrift server options:
Use value for given property
其中[options] 是ThriftServer启动一个SparkSQL应用程序的参数,如果不设置--master的话,将在启动ThriftServer的机器以local方式运行,只能通过http://机器名:4040进行监控;这部分参数,可以参照
Spark1.0.0 应用程序部署工具spark-submit 的参数。在集群中提供ThriftServer的话,一定要配置master、executor-memory等参数。
[thrift server options]是ThriftServer的参数,可以使用-d
property=value的格式来定义;在实际应用上,因为参数比较多,通常使用conf/hive-site.xml配置。
2.3 ThriftServer使用
2.3.1 启动ThriftServer
启动ThriftServer,使之运行在spark集群中:
sbin/start-thriftserver.sh --master spark://hadoop1:7077 --executor-memory 3g
在集群监控页面可以看到启动了SparkSQL应用程序:
2.3.2 远程客户端连接
切换到客户端wyy,启动bin/beeline,用!connect jdbc:hive2://hadoop2:10000
连接ThriftServer,因为没有采用权限管理,所以用户名用运行bin/beeline的用户,密码为空:
- 切换数据库saledata;
- cache table tblstock;
- 对tblstock计数;
从上可以看出,ThriftServer可以连接多个JDBC/ODBC客户端,并相互之间可以共享数据。顺便提一句,ThriftServer启动后处于监听状态,用户可以使用ctrl+c退出ThriftServer;而beeline的退出使用!q命令。
2.3.3 代码示例
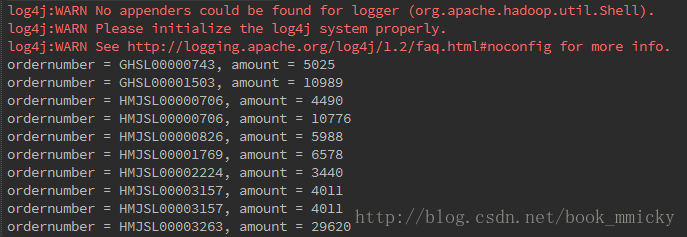
有了ThriftServer,开发人员可以非常方便的使用JDBC/ODBC来访问sparkSQL。下面是一个scala代码,查询表tblStockDetail ,返回amount>3000的单据号和交易金额:
package doc
import java.sql.DriverManager
object SQLJDBC {
def main(args: Array[String]) {
Class.forName("org.apache.hive.jdbc.HiveDriver")
val conn = DriverManager.getConnection("jdbc:hive2://hadoop2:10000", "hadoop", "")
try {
val statement = conn.createStatement
val rs = statement.executeQuery("select ordernumber,amount from tblStockDetail where amount>3000")
while (rs.next) {
val ordernumber = rs.getString("ordernumber")
val amount = rs.getString("amount")
println("ordernumber = %s, amount = %s".format(ordernumber, amount))
}
} catch {
case e: Exception => e.printStackTrace
}
conn.close
}
}
3:小结
总的来说,ThriftServer和CLI的引入,使得sparkSQL可以更方便的使用hive数据,使得sparkSQL可以更接近使用者,而非开发者。















 918
918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









