







安装及使用
配置hive-site.xml(baiyun.server.com主机进行)
在Spark-SQL的安装及使用的基础上,继续对hive-site.xml进行配置,如下<?xml version="1.0" encoding="UTF-8"?> <!--Autogenerated by Cloudera Manager--> <configuration> <property> <name>hive.metastore.uris</name> <value>thrift://Hive-Metastore-Server:9083</value> </property> <property> <name>hive.server2.thrift.port</name> <value>10001</value> <description>Port number of HiveServer2 Thrift interface. Can be overridden by setting $HIVE_SERVER2_THRIFT_PORT</description> </property> <property> <name>hive.server2.thrift.bind.host</name> <value>baiyun.server.com</value> <description>Bind host on which to run the HiveServer2 Thrift interface. Can be overridden by setting $HIVE_SERVER2_THRIFT_BIND_HOST</description> </property> </configuration>hive.metastore.uris指定了连接的Hive数据源,hive.server2.thrift.bind.host指定要启动thrift server的主机,hive.server2.thrift.port指定要打开的端口号。使用端口10001是为了避免与Hive自己的hive.server2.thrift.port—10000产生冲突。- 开启thrift server(baiyun.server.com主机进行)
输出Hadoop配置路径:export HADOOP_CONF_DIR=/etc/hadoop/conf.
使用命令sbin/start-thriftserver.sh --master yarn启动thrift server。可以在http://baiyun.server.com:4040/jobs/查看所有作业情况。
通过netstat -lanp | grep 10001判断端口是否在监听。 客户端连接启动的thrift server(baiyun.client.com主机进行)
在客户端baiyun.client.com的Spark安装目录下,运行bin/beelinehdfs@baiyun.client.com:~/spark-1.6.1-bin-hadoop2.6$ bin/beeline Beeline version 1.6.1 by Apache Hive之后输入
!connect jdbc:hive2://baiyun.server.com:10001连接到thrift server,用户名可以随意输入,beeline> !connect jdbc:hive2://baiyun.server.com:10001 Connecting to jdbc:hive2://baiyun.server.com:10001 Enter username for jdbc:hive2://baiyun.server.com:10001: lilei Enter password for jdbc:hive2://baiyun.server.com:10001: log4j:WARN No appenders could be found for logger (org.apache.hive.jdbc.Utils). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. Connected to: Spark SQL (version 1.6.1) Driver: Spark Project Core (version 1.6.1) Transaction isolation: TRANSACTION_REPEATABLE_READ输入sql语句进行测试,
0: jdbc:hive2://baiyun.client.com:10001> show databases; +----------+--+ | result | +----------+--+ | default | | lykdata | +----------+--+ 2 rows selected (0.203 seconds)- 在作业界面查看客户端的所有操作
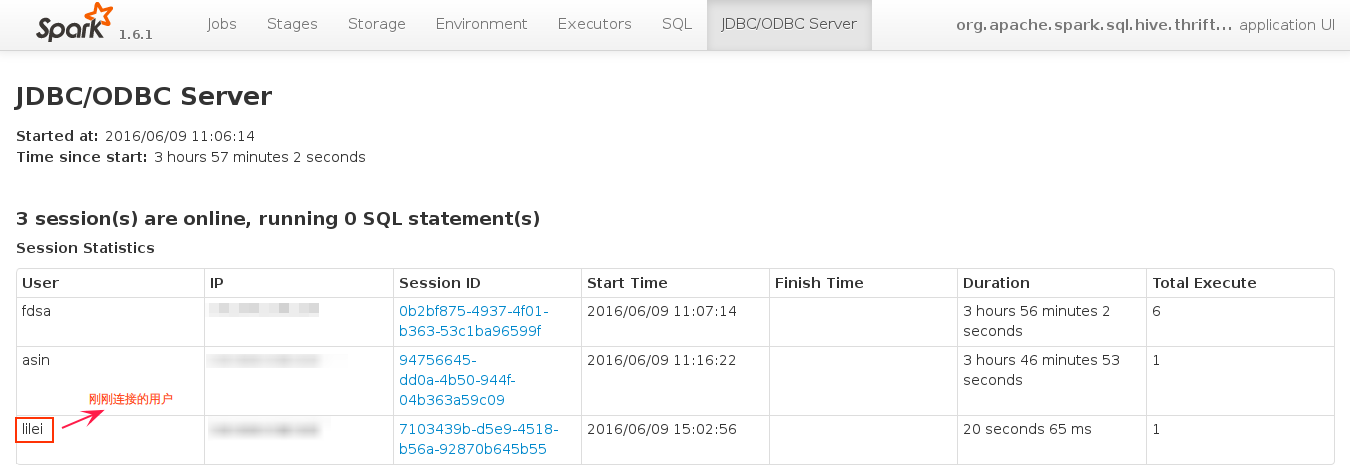
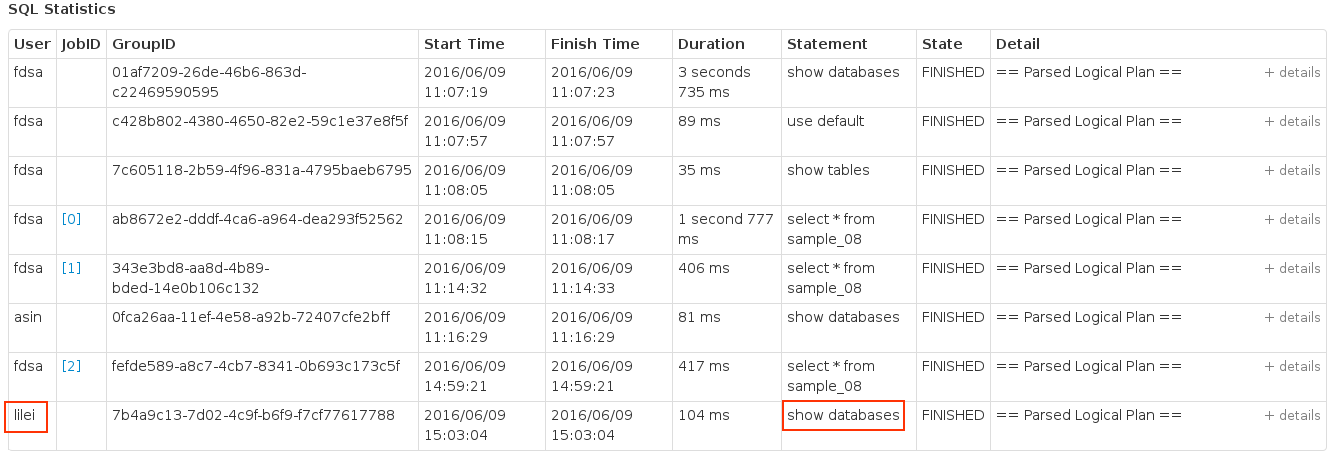
后记
上述连接的是自建的Thrift Server,客户端进行的所有操作都在Spark的作业界面可以看到,并且每个sql语句对应一个job。
实际上也可以通过命令!connect jdbc:hive2://hive-thrift-server:10000连接Hive自带的Thrift Server,与上述不同的是每个sql语句都对应一个MR作业。















 394
394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









