






菜鸟nginx源码剖析数据结构篇(六) 哈希表 ngx_hash_t(上)
Author:Echo Chen(陈斌)
Email:chenb19870707@gmail.com
Blog:Blog.csdn.net/chen19870707
Date:October 31h, 2014
1.哈希表ngx_hash_t的优势和特点
哈希表是一种典型的以空间换取时间的数据结构,在没有冲突的情况下,对任意元素的插入、索引、删除的时间复杂度都是O(1)。这样优秀的时间复杂度是通过将元素的key值以hash方法f映射到哈希表中的某一个位置来访问记录来实现的,即键值为key的元素必定存储在哈希表中的f(key)的位置。当然,不同的元素的hash值可能相同,这就是hash冲突,有两种解决方法(分离链表发和开放地址发),ngx采用的是开放地址法.
分离链表法是通过将冲突的元素链接在一个哈希表外的一个链表中,这样,找到hash表中的位置后,就可以通过遍历这个单链表来找到这个元素。
开放地址法是插入的时候发现 自己的位置f(key)已经被占了,就向后遍历,查看f(key)+1的位置是否被占用,如果没被占用,就占用它,否则继续相后,查询的时候,同样也如果f(key)不是需要的值,也依次向后遍历,一直找到需要的元素。
2.源代码位置
头文件:http://trac.nginx.org/nginx/browser/nginx/src/core/ngx_hash.h
源文件:http://trac.nginx.org/nginx/browser/nginx/src/core/ngx_hash.c
3.数据结构定义
ngx_hash的内存布局如下图,它采用了三级管理结构,只要由以下几个结构足证:
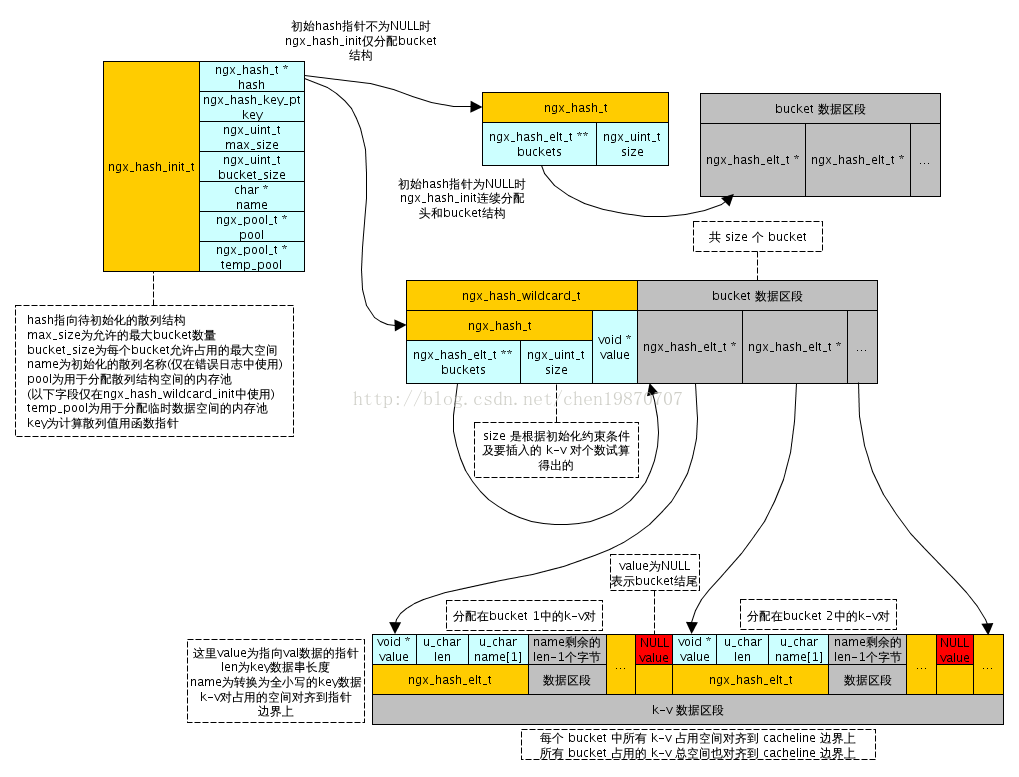
3.1 hash表中元素ngx_hash_elt_t
ngx_hash_elt是哈希表的元素,它负责存储key-value值,其中key为name 、value为value,这里看到name仅为一个字节的uchar数组,仅用于指出key的首地址,而key的长度是可变的,所以哈希表元素的大小并不是由sizeof(ngx_hash_elt_t_t)决定的,而是在初始化时指定的。

- value是指向用户自定义数据类型的指针,如果hash表中这个位置没有元素,则value = NULL
- len 表示关键字key的长度,关键字的长度是不定的
- name 为key的首地址
1: typedef struct { 2: void *value; //指向用户自定义元素的指针,如果该位置没有元素,即为NULL 3: u_short len; //key的长度 4: u_char name[1]; //key的首地址 5: } ngx_hash_elt_t;
3.2 基本哈希表结构 ngx_hash_t
哈希表结构是一个ngx_hash_elt_t的数组,其中buckets指向哈希表的首地址,也是第一个槽的地址,size为哈希表中槽的总个数
1: typedef struct { 2: ngx_hash_elt_t **buckets; 3: ngx_uint_t size; 4: } ngx_hash_t;3.3 支持通配符的哈希表结构 ngx_hash_wildcard_t
ngx_hash_wildcard_t专用于表示牵制或后置通配符的哈希表,如:前置*.test.com,后置:www.test.* ,它只是对ngx_hash_t的简单封装,是由一个基本哈希表hash和一个额外的value指针,当使用ngx_hash_wildcard_t通配符哈希表作为容器元素时,可以使用value指向用户数据。
1: typedef struct { 2: ngx_hash_t hash; 3: void *value; 4: } ngx_hash_wildcard_t;
3.4 组合类型哈希表 ngx_hash_combined_t
ngx_hash_combined_t是由3个哈希表组成,一个普通hash表hash,一个包含前向通配符的hash表wc_head和一个包含后向通配符的hash表 wc_tail。
1: typedef struct {2: ngx_hash_t hash;3: ngx_hash_wildcard_t *wc_head;4: ngx_hash_wildcard_t *wc_tail;5: } ngx_hash_combined_t;
3.5 哈希表初始化ngx_hash_init_t
·hash初始化结构是ngx_hash_init_t,ngx_hash_init用于初始化哈希表,初始化哈希表的槽的总数并不是完全由max_size成员决定的,而是由在做初始化时预先加入到哈希表的所有元素决定的,包括这些元素的总是、每个元素的关键字长度等,还包括操作系统的页面大小,这个算法比较复杂,可以在ngx_hash_init函数中找到这个算法它的结构如下:
1: typedef struct { 2: ngx_hash_t *hash; //指向普通的完全匹配哈希表 3: ngx_hash_key_pt key; //哈希方法 4: 5: ngx_uint_t max_size; //哈希表中槽的最大个数 6: ngx_uint_t bucket_size; //哈希表中一个槽的空间大小,不是sizeof(ngx_hash_elt_t) 7: 8: char *name; //哈希表的名称 9: ngx_pool_t *pool; //内存池,它负责分配基本哈希列表、前置通配哈希列表、后置哈希列表中所有槽 10: ngx_pool_t *temp_pool; //临时内存池,它仅存在初始化哈希表之前。用于分配一些临时的动态数组,带通配符的元素初始化时需要用到临时动态数组 11: } ngx_hash_init_t;
3.6 预添加哈希散列元素结构 ngx_hash_key_t
ngx_hash_key_t用于表示即将添加到哈希表中的元素,其结构如下:
1: typedef struct { 2: ngx_str_t key; //元素关键字 3: ngx_uint_t key_hash; //由哈希方法算出来的哈希值 4: void *value; //指向用户自定义数据 5: } ngx_hash_key_t;
3.7 ngx_hash_key_t构造结构 ngx_hash_keys_arrays_t
可以看到,这里设计了3个简易的哈希列表( keys_hash、dns_wc_head_hash、dns_wc_tail_hash),即采用分离链表法来解决冲突,这样做的好处是如果没有这三个次啊用分离链表法来解决冲突的建议哈希列表,那么每添加一个关键字元素都要遍历数组(数组采用开放地址法解决冲突,冲突就必须遍历)。
1: typedef struct { 2: ngx_uint_t hsize; //散列中槽总数 3: 4: ngx_pool_t *pool; //内存池,用于分配永久性的内存 5: ngx_pool_t *temp_pool; //临时内存池,下面的临时动态数组都是由临时内存池分配 6: 7: ngx_array_t keys; //存放所有非通配符key的数组。 8: ngx_array_t *keys_hash; //这是个二维数组,第一个维度代表的是bucket的编号,那么keys_hash[i]中存放的是所有的key算出来的hash值对hsize取模以后的值为i的key。假设有3个key,分别是key1,key2和key3假设hash值算出来以后对hsize取模的值都是i,那么这三个key的值就顺序存放在keys_hash[i][0],keys_hash[i][1], keys_hash[i][2]。该值在调用的过程中用来保存和检测是否有冲突的key值,也就是是否有重复。 9: 10: ngx_array_t dns_wc_head; //存放前向通配符key被处理完成以后的值。比如:“*.abc.com”被处理完成以后,变成“com.abc.”被存放在此数组中。 11: ngx_array_t *dns_wc_head_hash; //该值在调用的过程中用来保存和检测是否有冲突的前向通配符的key值,也就是是否有重复。 12: 13: ngx_array_t dns_wc_tail; //存放后向通配符key被处理完成以后的值。比如:“mail.xxx.*”被处理完成以后,变成“mail.xxx.”被存放在此数组中。 14: ngx_array_t *dns_wc_tail_hash; //该值在调用的过程中用来保存和检测是否有冲突的后向通配符的key值,也就是是否有重复。 15: } ngx_hash_keys_arrays_t;
4.普通哈希表初始化ngx_hash_init
初始化设计操作设计还是很巧妙的,巧妙的结构设计在这里都得到体现,主要有:
- 桶大小估算,这里一开始 按照 ngx_hash_elt_t估算最小需要的桶的数目,然后再从这个数目开始搜索,大大提高了效率,值得学习。
- ngx_hash_elt_t中uchar name[1]的设计,如果在name很短的情况下,name和 ushort 的字节对齐可能只用占到一个字节,这样就比放一个uchar* 的指针少占用一个字节,可以看到ngx是真的在内存上考虑,节省每一分内存来提高并发。
先看一下求ngx_hash_elt_t的占用内存大小的方法,前面提到不是用sizeof(ngx_hash_elt_t),原因是因为name的特殊设计,正确的求法如下,可以看到是一个sizeof(void*) 即用户自定义指针(value),一个长度len(sizeof(unsigned short)) 和 name 的真实长度len 对void*字节对齐。
1: typedef struct {2: void *value;3: u_short len;4: u_char name[1];5: } ngx_hash_elt_t;6:7: #define NGX_HASH_ELT_SIZE(name) \8: (sizeof(void *) + ngx_align((name)->key.len + 2, sizeof(void *)))
如下是注释版源代码,比较长,总的流程即为:预估需要的桶数量 –> 搜索需要的桶数量->分配桶内存->初始化每一个ngx_hash_elt_t
1: //hinit是哈希表初始化结构指针,names是预添加到哈希表结构的数组,nelts为names元素个数 2: ngx_int_t ngx_hash_init(ngx_hash_init_t *hinit, ngx_hash_key_t *names, ngx_uint_t nelts) 3: { 4: u_char *elts; 5: size_t len; 6: u_short *test; 7: ngx_uint_t i, n, key, size, start, bucket_size; 8: ngx_hash_elt_t *elt, **buckets; 9: 10: //遍历预添加数组names,数组的每一个元素,判断槽的大小bucket_size是否够分配 11: for (n = 0; n < nelts; n++) 12: { 13: if (hinit->bucket_size < NGX_HASH_ELT_SIZE(&names[n]) + sizeof(void *)) 14: { 15: //有任何一个元素,槽的大小不够为该元素分配空间,则退出 16: ngx_log_error(NGX_LOG_EMERG, hinit->pool->log, 0, 17: "could not build the %s, you should " 18: "increase %s_bucket_size: %i", 19: hinit->name, hinit->name, hinit->bucket_size); 20: return NGX_ERROR; 21: } 22: } 23: 24: //test 是short数组,用于临时保存每个桶的当前大小 25: test = ngx_alloc(hinit->max_size * sizeof(u_short), hinit->pool->log); 26: if (test == NULL) { 27: return NGX_ERROR; 28: } 29: 30: // 为什么会多一个指针大小呢?这里主要还是为了后面将每个元素对齐到指针 31: bucket_size = hinit->bucket_size - sizeof(void *); 32: 33: /* 计算需要桶数目的下界 34: 每个元素最少需要 NGX_HASH_ELT_SIZE(&name[n]) > (2*sizeof(void*)) 的空间 35: 因此 bucket_size 大小的桶最多能容下 bucket_size/(2*sizeof(void*)) 个元素 36: 因此 nelts 个元素就最少需要start个桶。 37: */ 38: start = nelts / (bucket_size / (2 * sizeof(void *))); 39: start = start ? start : 1; 40: 41: if (hinit->max_size > 10000 && nelts && hinit->max_size / nelts < 100) { 42: start = hinit->max_size - 1000; 43: } 44: 45: /* 从最小桶数目开始试,计算容下 nelts 个元素需要多少个桶 */ 46: for (size = start; size <= hinit->max_size; size++) { 47: ngx_memzero(test, size * sizeof(u_short)); 48: 49: for (n = 0; n < nelts; n++) { 50: if (names[n].key.data == NULL) { 51: continue; 52: } 53: 54: //根据哈希值计算计算要放在哪个桶 55: key = names[n].key_hash % size; 56: //将桶大小增加一个ngx_hash_elt_t 57: test[key] = (u_short) (test[key] + NGX_HASH_ELT_SIZE(&names[n])); 58: 59: #if 0 60: ngx_log_error(NGX_LOG_ALERT, hinit->pool->log, 0, 61: "%ui: %ui %ui \"%V\"", 62: size, key, test[key], &names[n].key); 63: #endif 64: 65: //发现放在size 个桶中,还是有放不下的情况,所以需要的桶+1,再循环 66: if (test[key] > (u_short) bucket_size) { 67: goto next; 68: } 69: } 70: 71: //names中所有元素都可以放入size个桶中,找到正确的size大小了 72: goto found; 73: 74: next: 75: 76: continue; 77: } 78: 79: ngx_log_error(NGX_LOG_WARN, hinit->pool->log, 0, 80: "could not build optimal %s, you should increase " 81: "either %s_max_size: %i or %s_bucket_size: %i; " 82: "ignoring %s_bucket_size", 83: hinit->name, hinit->name, hinit->max_size, 84: hinit->name, hinit->bucket_size, hinit->name); 85: 86: found: 87: /* 执行到这里就得到了 容下 nelts 个元素需要 size 个桶 ,初始化每个桶大小*/ 88: for (i = 0; i < size; i++) { 89: test[i] = sizeof(void *); 90: } 91: 92: //计算实际上每个桶的大小 93: for (n = 0; n < nelts; n++) { 94: if (names[n].key.data == NULL) { 95: continue; 96: } 97: 98: //根据哈希值,应该放在第key个桶中,大小增加一个ngx_hash_elt_t 99: key = names[n].key_hash % size; 100: test[key] = (u_short) (test[key] + NGX_HASH_ELT_SIZE(&names[n])); 101: } 102: 103: len = 0; 104: 105: for (i = 0; i < size; i++) { 106: //桶中没有元素 107: if (test[i] == sizeof(void *)) { 108: continue; 109: } 110: 111: //行缓存对其,CPU读取内存不是一个一个字节,而是以cacheline_size为单位,以行缓存对其,提高CPU读取效率 112: test[i] = (u_short) (ngx_align(test[i], ngx_cacheline_size)); 113: 114: len += test[i]; 115: } 116: 117: // 这里似乎看起来很奇怪,既然是hash,为什么分配空间的大小又跟hash结构体一点关联都没有呢 118: // 这里很有意思,因为ngx_hash_wildchard_t包含hash这个结构体,所以就一起分配了 119: // 并且把每个桶的指针也分配在一起了,这种思考跟以前学的面向对象思想很不一样,但这样会很高效 120: if (hinit->hash == NULL) { 121: hinit->hash = ngx_pcalloc(hinit->pool, sizeof(ngx_hash_wildcard_t) 122: + size * sizeof(ngx_hash_elt_t *)); 123: if (hinit->hash == NULL) { 124: ngx_free(test); 125: return NGX_ERROR; 126: } 127: 128: buckets = (ngx_hash_elt_t **) 129: ((u_char *) hinit->hash + sizeof(ngx_hash_wildcard_t)); 130: 131: } else { 132: //分配桶 133: buckets = ngx_pcalloc(hinit->pool, size * sizeof(ngx_hash_elt_t *)); 134: if (buckets == NULL) { 135: ngx_free(test); 136: return NGX_ERROR; 137: } 138: } 139: 140: //将内存池对其到行缓存,提高CPU读取效率 141: elts = ngx_palloc(hinit->pool, len + ngx_cacheline_size); 142: if (elts == NULL) { 143: ngx_free(test); 144: return NGX_ERROR; 145: } 146: 147: //对指针地址的对齐操作 148: elts = ngx_align_ptr(elts, ngx_cacheline_size); 149: 150: for (i = 0; i < size; i++) { 151: if (test[i] == sizeof(void *)) { 152: continue; 153: } 154: // 给bucket每个桶地址赋值 155: buckets[i] = (ngx_hash_elt_t *) elts; 156: elts += test[i]; 157: 158: } 159: // 清空重新计算 160: for (i = 0; i < size; i++) { 161: test[i] = 0; 162: } 163: 164: for (n = 0; n < nelts; n++) { 165: if (names[n].key.data == NULL) { 166: continue; 167: } 168: 169: //根据哈希值找到桶 170: key = names[n].key_hash % size; 171: 172: //找到每个元素的地址 173: elt = (ngx_hash_elt_t *) ((u_char *) buckets[key] + test[key]); 174: 175: //给value和len赋值 176: elt->value = names[n].value; 177: elt->len = (u_short) names[n].key.len; 178: 179: //拷贝name,name长度在前面计算size时已经算好了 180: ngx_strlow(elt->name, names[n].key.data, names[n].key.len); 181: 182: //增加这个桶的索引 183: test[key] = (u_short) (test[key] + NGX_HASH_ELT_SIZE(&names[n])); 184: } 185: 186: // 设置每个桶的结束元素为NULL 187: for (i = 0; i < size; i++) { 188: if (buckets[i] == NULL) { 189: continue; 190: } 191: 192: elt = (ngx_hash_elt_t *) ((u_char *) buckets[i] + test[i]); 193: 194: elt->value = NULL; 195: } 196: 197: //释放临时动态数组 198: ngx_free(test); 199: 200: //给哈希表赋值 201: hinit->hash->buckets = buckets; 202: hinit->hash->size = size; 203: return NGX_OK; 204: }
5.支持通配符哈希表ngx_hash_wildcard_init
首先看一下ngx_hash_wildcard_init 的内存结构,当构造此类型的hash表的时候,实际上是构造了一个hash表的一个“链表”,是通过hash表中的key“链接”起来的。比如:对于“*.abc.com”将会构造出2个hash表,第一个hash表中有一个key为com的表项,该表项的value包含有指向第二个hash表的指针,而第二个hash表中有一个表项abc,该表项的value包含有指向*.abc.com对应的value的指针。那么查询的时候,比如查询www.abc.com的时候,先查com,通过查com可以找到第二级的hash表,在第二级hash表中,再查找abc,依次类推,直到在某一级的hash表中查到的表项对应的value对应一个真正的值而非一个指向下一级hash表的指针的时候,查询过程结束。

理解了这个,我们就可以看源代码了,ngx_hash_wildcard是一个递归函数,递归创建如上图的hash链表,如下为注释版源代码。
精彩的读点有:
- 由于指针都字节对齐了,低2位肯定为0,这种操作(name->value = (void *) ((uintptr_t) wdc | (dot ? 3 : 2)) ) 巧妙的使用了指针的低位携带额外信息,节省了内存,让人不得不佩服ngx设计者的想象力。
1: /*hinit为初始化结构体指针,names为预加入哈希表数组,elts为预加入数组大小 2: 特别要注意的是这里的key已经都是被预处理过的。例如:“*.abc.com”或者“.abc.com”被预处理完成以后, 3: 变成了“com.abc.”。而“mail.xxx.*”则被预处理为“mail.xxx.”*/ 4: ngx_int_t ngx_hash_wildcard_init(ngx_hash_init_t *hinit, ngx_hash_key_t *names,ngx_uint_t nelts) 5: { 6: size_t len, dot_len; 7: ngx_uint_t i, n, dot; 8: ngx_array_t curr_names, next_names; 9: ngx_hash_key_t *name, *next_name; 10: ngx_hash_init_t h; 11: ngx_hash_wildcard_t *wdc; 12: 13: //初始化临时动态数组curr_names,curr_names是存放当前关键字的数组 14: if (ngx_array_init(&curr_names, hinit->temp_pool, nelts, 15: sizeof(ngx_hash_key_t)) 16: != NGX_OK) 17: { 18: return NGX_ERROR; 19: } 20: 21: //初始化临时动态数组next_names,next_names是存放关键字去掉后剩余关键字 22: if (ngx_array_init(&next_names, hinit->temp_pool, nelts, sizeof(ngx_hash_key_t)) != NGX_OK) 23: { 24: return NGX_ERROR; 25: } 26: 27: //遍历 names 数组 28: for (n = 0; n < nelts; n = i) 29: { 30: dot = 0; 31: 32: //查找 dot 33: for (len = 0; len < names[n].key.len; len++) 34: { 35: if (names[n].key.data[len] == '.') 36: { 37: dot = 1; 38: break; 39: } 40: } 41: 42: //将关键字dot以前的关键字放入curr_names 43: name = ngx_array_push(&curr_names); 44: if (name == NULL) { 45: return NGX_ERROR; 46: } 47: 48: name->key.len = len; 49: name->key.data = names[n].key.data; 50: name->key_hash = hinit->key(name->key.data, name->key.len); 51: name->value = names[n].value; 52: 53: dot_len = len + 1; 54: 55: //len指向dot后剩余关键字 56: if (dot) 57: { 58: len++; 59: } 60: 61: next_names.nelts = 0; 62: 63: //如果names[n] dot后还有剩余关键字,将剩余关键字放入next_names中 64: if (names[n].key.len != len) 65: { 66: next_name = ngx_array_push(&next_names); 67: if (next_name == NULL) { 68: return NGX_ERROR; 69: } 70: 71: next_name->key.len = names[n].key.len - len; 72: next_name->key.data = names[n].key.data + len; 73: next_name->key_hash = 0; 74: next_name->value = names[n].value; 75: 76: } 77: 78: //如果上面搜索到的关键字没有dot,从n+1遍历names,将关键字比它长的全部放入next_name 79: for (i = n + 1; i < nelts; i++) 80: { 81: //前len个关键字相同 82: if (ngx_strncmp(names[n].key.data, names[i].key.data, len) != 0) { 83: break; 84: } 85: 86: 87: if (!dot 88: && names[i].key.len > len 89: && names[i].key.data[len] != '.') 90: { 91: break; 92: } 93: 94: next_name = ngx_array_push(&next_names); 95: if (next_name == NULL) { 96: return NGX_ERROR; 97: } 98: 99: next_name->key.len = names[i].key.len - dot_len; 100: next_name->key.data = names[i].key.data + dot_len; 101: next_name->key_hash = 0; 102: next_name->value = names[i].value; 103: 104: } 105: 106: //如果next_name非空 107: if (next_names.nelts) 108: { 109: h = *hinit; 110: h.hash = NULL; 111: 112: //递归,创建一个新的哈西表 113: if (ngx_hash_wildcard_init(&h, (ngx_hash_key_t *) next_names.elts,next_names.nelts) != NGX_OK) 114: { 115: return NGX_ERROR; 116: } 117: 118: wdc = (ngx_hash_wildcard_t *) h.hash; 119: 120: //如上图,将用户value值放入新的hash表 121: if (names[n].key.len == len) 122: { 123: wdc->value = names[n].value; 124: } 125: 126: //并将当前value值指向新的hash表 127: name->value = (void *) ((uintptr_t) wdc | (dot ? 3 : 2)); 128: 129: } else if (dot) 130: { 131: name->value = (void *) ((uintptr_t) name->value | 1); 132: } 133: } 134: 135: //将最外层hash初始化 136: if (ngx_hash_init(hinit, (ngx_hash_key_t *) curr_names.elts,curr_names.nelts) != NGX_OK) 137: { 138: return NGX_ERROR; 139: } 140: 141: return NGX_OK; 142: }
6.总结
由于ngx_hash的内容比较多,很多设计都值得学习和研究,将在《菜鸟nginx源码剖析数据结构篇(六) 哈希表 ngx_hash_t(下)》 探讨剩余内容。
-
Echo Chen:Blog.csdn.net/chen19870707
-















 1926
1926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









