




 本文介绍了Python模拟登录网站的原理和步骤,通过分析浏览器与服务器的交互,讲解了如何获取cookie和_xsrf token,使用正则表达式提取关键信息,并在Python中构造POST请求实现登录,最后展示了一段模拟登录的代码示例。
本文介绍了Python模拟登录网站的原理和步骤,通过分析浏览器与服务器的交互,讲解了如何获取cookie和_xsrf token,使用正则表达式提取关键信息,并在Python中构造POST请求实现登录,最后展示了一段模拟登录的代码示例。
备注:python 2.7.9,32位
有些网站需要登录后才能爬取所需要的信息,此时可以设计爬虫进行模拟登录,原理是利用浏览器cookie。
一、浏览器访问服务器的过程:
(1)浏览器(客户端)向Web服务器发出一个HTTP请求(Http request);
(2)Web服务器收到请求,发回响应信息(Http Response);
(3)浏览器解析内容呈现给用户。
二、利用Fiddler查看浏览器行为信息:
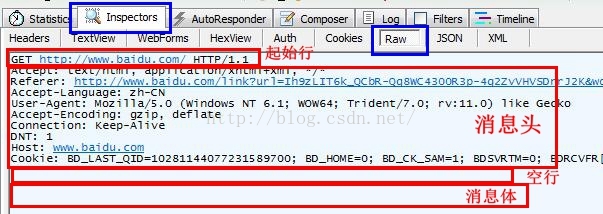
Http请求消息:
(1)起始行:包括请求方法、请求的资源、HTTP协议的版本号
这里GET请求没有消息主体,因此消息头后的空白行中没有其他数据。
(2)消息头:包含各种属性
(3)消息头结束后的空白行
(4)可选的消息体:包含数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2831
2831






 到【灌水乐园】发言
到【灌水乐园】发言







