






一、需求
1.定时抓取固定网站新闻标题、内容、发表时间和来源。
2.程序需要支持分布式、多线程
二、设计
1.网站是固定,但是未来也可能添加新的网站去抓取,每个网站内容节点设计都不一样,这样就需要支持动态可配置来新增网站以方便未来的扩展,这样就需要每次都需要开发介入。
2.网站html节点的结构可能发生变化,所以也要支持提取节点可配置。
3.怎样支持分布式?暂时最简单的想法就是:多机器部署程序,还有新搞一台或者部署程序其中一台制作一个定时任务,定时开启每台机器应该抓取哪个网站,暂时不能支持同一个网站同时可以支持被多台机器同时抓取,这样会比较麻烦,要用到分布式队列。所以暂时一个网站同时只会被单台机器抓取。
4.多线程,怎样多线程?多线程抓取我这边有两个实现:
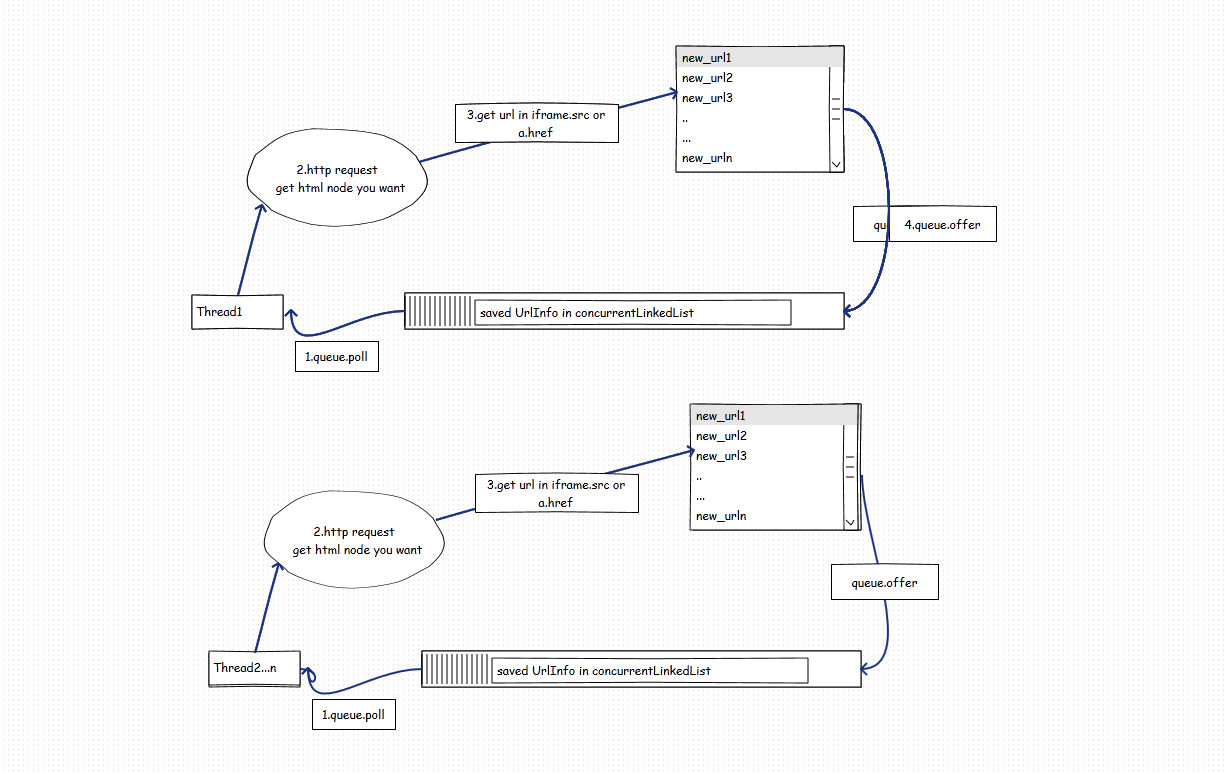
(1)一个线程抓取一个网站,维护一个自己的url队列做广度抓取,同时抓取多个网站。如图:
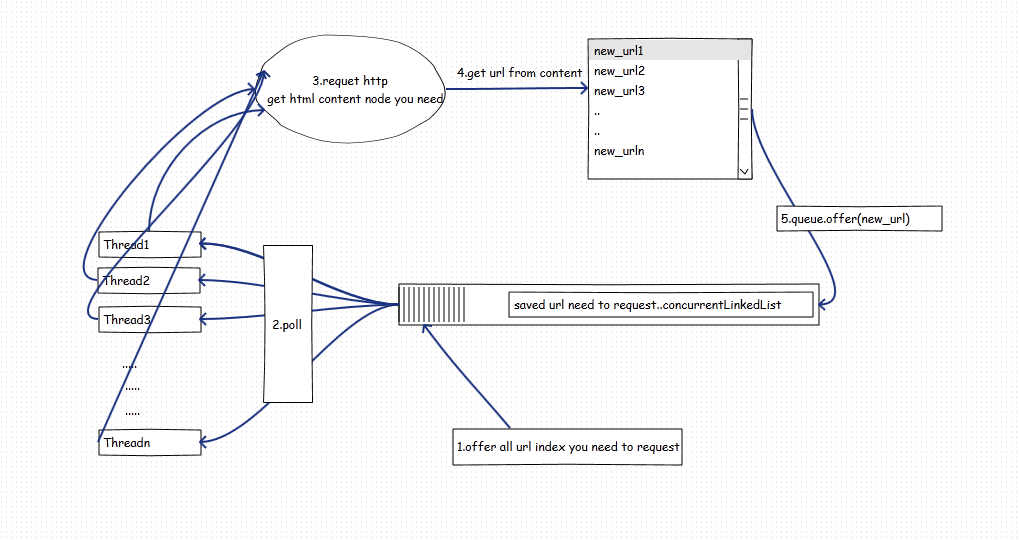
(2)多个线程同时抓取不同的网站。如图:
以上两张办法其实各有优点,也给有缺点,看我们怎么取舍了。
方法1:每个线程创建一个自己的队列,图中的queue可以不用concurrentQueue,优点:不涉及到控制并发,每个网站一个线程抓取一个网站,抓取完毕即自动回收销毁线程。控制方便。缺点:线程数不可以扩展,例如当只有3个网站,你最多只能开3个线程来抓取,不能开更多,有一定的局限性。
方法2:N个线程同时抓取N个网站,线程数和网站数目不挂钩,优点:线程数可以调整并且和和抓取网站数量无关。3个网站我们可以开4个5个或者10个这个可以根据您的硬件资源进行调整。缺点:需要控制并发,并且要控制什么时候销毁线程(thread1空闲,并且queue为空不代表任务可以结束,可能thread2结果还没返回),当被抓取的网站响应较慢时,会拖慢整个爬虫进度。
三、实现
抓取方式最终还是选择了方法二,因为线程数可配置!
使用技术:
jfinal 用了之后才发现这东西不适合,但是由于项目进度问题,还是使用了。
maven项目管理
jetty server
mysql
eclipse 开发
项目需要重点攻破的难点:
(1)合理的控制N个线程正常的抓取网站,并且当所有线程工作都完成了并且需要抓取的队列为空时,N个线程同时退出销毁。
(2)不同网站设计节点不一样,需要通过配置解决各个网站需要抓取的URL和抓取节点内容在html节点的位置。
(3)个性化内容处理,由于html结构设计问题,抓取的内容可能有些多余的html标签,或者多余的内容该怎么处理。
实现1:线程管理建立一个线程中心管理控制器,控制器负责线程的销毁。如图:
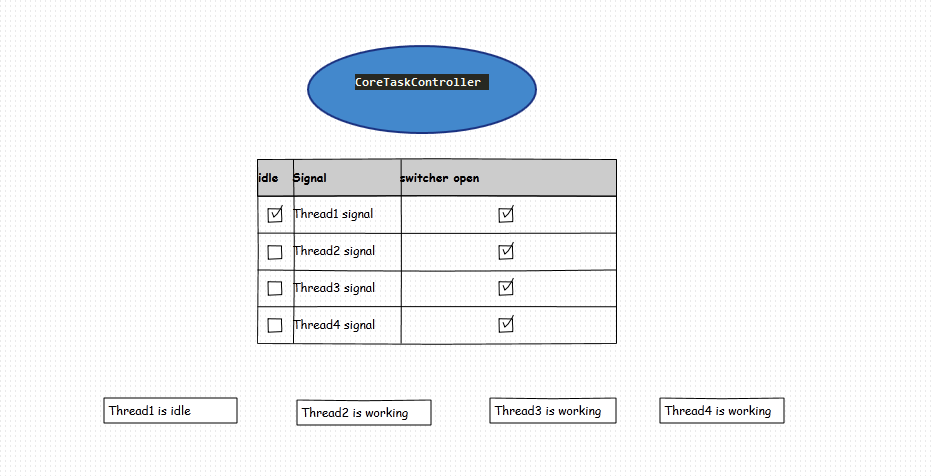
(1)创建一个中心管理器,管理器存放N个线程的signal数组标记,用来标记线程是否空闲,并且创建N个标记的线程开关。用来同时结束N个线程。
(2)线程在开始抓取请求链接时把idle置为false,抓取链接完毕之后继续循环取队列(循环时候判断开关是否为true),当从队列poll结果为空时,把线程置为idle=true,并且sleep 1S(看个人爱好)。
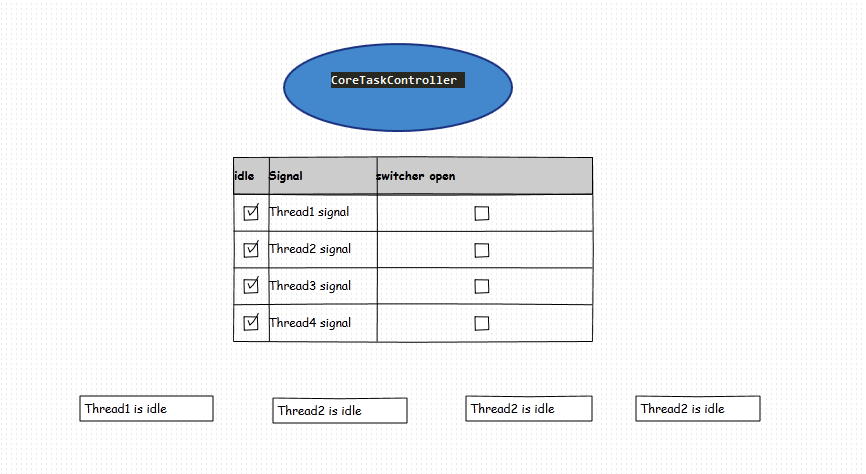
(3)线程中心中心管理器调度一个定时检测任务1s钟检测一次 线程的signal数组标记和queue.size(),当queue.size()==0并且数组标记全部都标记空闲的时候,把线程开关switcher全部置为false(关闭,这样线程会结束while退出)
如图下情况,4个线程的状态后线程即可自行退出:
核心控制功能和线程功能代码如下:
CoreTaskController.java
import java.util.Arrays;
import java.util.Timer;
import java.util.TimerTask;
import org.apache.log4j.Logger;
import com.crawler.core.conf.CrawlerConf;
/**
* 任务核心控制器
* @author Jacky
* 2015-9-30
*/
public class CoreTaskController {
public static Logger log = Logger.getLogger(CoreTaskController.class);
/**
* 信号量,用来标记当前线程是否空闲
* 0表示空闲
* 1表示繁忙
* CrawlerConf.getMaxT()表示获取最大线程数
*/
public static volatile int[] signal = new int[CrawlerConf.getMaxT()];;
public static volatile boolean totalSwitcher = true;
/**
* 线程开关
* 1表示打开
* 0表示关闭
*/
public static volatile int[] switcher = new int[CrawlerConf.getMaxT()];
public static Timer timer;
public static void init() {
// 开启所有线程开关
for(int i=0;i<switcher.length;i++) {
switcher[i] = 1;
}
}
public static void startSc() {
if(null != timer) {
timer.cancel();
}
timer = new Timer();
timer.schedule(new JobTask(), 5000,1000);
}
static class JobTask extends TimerTask {
@Override
public void run() {
// 当总开关被关闭,立即结束所有线程
if(!totalSwitcher) {
// 关闭线程开关
for(int i=0;i<switcher.length;i++) {
switcher[i] = 0;
// 停止调度此任务
this.cancel();
CoreTaskController.timer.cancel();
}
UrlQueue.concurrentSet.clear();
return;
}
/**
* UrlQueue.concurrentQueue 就是用来存放
* url的队列
*/
if(UrlQueue.concurrentQueue.size() == 0 ) {
boolean stop = true;
for(int i : signal) {
stop = stop & (i == 0);
}
if(stop) {
// 关闭线程开关
for(int i=0;i<switcher.length;i++) {
switcher[i] = 0;
// 停止调度此任务
this.cancel();
CoreTaskController.timer.cancel();
}
UrlQueue.concurrentSet.clear();
}
}
log.warn("time task 调度中..signal="+Arrays.toString(signal)+",urlQueueSize="+UrlQueue.concurrentQueue.size()+",switcher="+Arrays.toString(switcher));
}
}
}ConcurrentCrawlerTask.java 线程任务代码
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.commons.httpclient.DefaultHttpMethodRetryHandler;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpStatus;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.httpclient.params.HttpMethodParams;
import org.apache.commons.lang.StringUtils;
import org.apache.log4j.Logger;
import com.crawler.core.conf.HttpConf;
import com.crawler.core.conf.UrlConf;
import com.crawler.core.conf.WebsiteConf;
import com.crawler.system.model.OriginContent;
/**
* 爬虫任务类
* @author Jacky
* 2015-9-29
*/
public class ConcurrentCrawlerTask extends Thread {
Logger log = Logger.getLogger(ConcurrentCrawlerTask.class);
private int index;
public ConcurrentCrawlerTask(int index,String taskName) {
super(taskName);
this.index = index;
}
@Override
public void run() {
UrlConf urlConf = null;
System.out.println("开启线程"+index);
// 有个线程总开关,如果总开关关闭直接结束所有线程循环,
// 每个线程有个自动开关,任务控制器检测到所有线程空闲,并且队列为空自动把开关改为关闭。
while(CoreTaskController.totalSwitcher &&
((urlConf = UrlQueue.concurrentQueue.poll()) != null || (null == urlConf && (CoreTaskController.switcher[index] == 1)))) {
if(urlConf != null) {
working();
try {
if(urlConf.getDepth() <= urlConf.getConf().getDepth()
&& !UrlQueue.concurrentSet.contains(urlConf.getHttpUrl())) {
// 匹配URL是否需要抓取,这些非核心可以无视
Pattern pattern = Pattern.compile(urlConf.getConf().getUrlReg().trim());
Matcher m = pattern.matcher(urlConf.getHttpUrl().trim());
if(urlConf.getDepth() == 1 || m.matches()) {
HttpClient httpClient = new HttpClient();
httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(HttpConf.TIME_OUT);
GetMethod getMethod = new GetMethod(urlConf.getHttpUrl());
initHttpParam(getMethod, urlConf.getConf());
try {
int httpCode = httpClient.executeMethod(getMethod);
if (httpCode != HttpStatus.SC_OK) {
log.error("request url:"+urlConf.getHttpUrl() + " failed! http code = "+httpCode);
continue;
}
BufferedReader reader = new BufferedReader(new InputStreamReader(getMethod.getResponseBodyAsStream(),urlConf.getConf().getCharset()));
StringBuilder stringBuilder = new StringBuilder();
String str = null;
while((str = reader.readLine())!=null){
stringBuilder.append(str);
}
//..
//..
} catch(Exception e) {
log.error("http error!", e);
}
}
// 用于保存该链接是否已经被访问过
UrlQueue.concurrentSet.add(urlConf.getHttpUrl());
}
//System.out.println("queue size:" + UrlQueue.concurrentQueue.size()+",depth:"+urlConf.getDepth());
} catch(Exception e) {
System.out.println(e.getCause());
log.error("unknow error.",e.getCause());
}
} else {
idle();
System.out.println("线程"+index+"空闲");
log.info("thread:"+index+" 空闲中.");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
break;
}
}
}
System.out.println("线程"+index+",任务结束");
}
private void working() {
CoreTaskController.signal[index] = 1;
}
private void idle() {
CoreTaskController.signal[index] = 0;
}
/**
* 初始化请求参数
* @param getMethod
* @param conf
*/
private void initHttpParam(GetMethod getMethod,WebsiteConf conf) {
getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT, HttpConf.SO_TIMEOUT);
getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
getMethod.getParams().setParameter(HttpMethodParams.USER_AGENT, HttpConf.USER_AGENT);
getMethod.getParams().setParameter(HttpMethodParams.HTTP_CONTENT_CHARSET, conf.getCharset());
getMethod.getParams().setParameter(HttpMethodParams.HTTP_URI_CHARSET, conf.getCharset());
getMethod.getParams().setParameter("refer", HttpConf.REFER);
}
@Override
public void interrupt() {
idle();
super.interrupt();
}
@Override
protected void finalize() throws Throwable {
idle();
super.finalize();
}
public static void main(String[] args) {
Pattern p = Pattern.compile("^http://news.carnoc.com/(cache/)?(list/){1}(\\w(/\\w)*)+.html$");
Matcher m = p.matcher("http://news.carnoc.com/cache/list/news_hotlist_1.html");
System.out.println(m.matches());
}
}实现二:关于抓取各种不同网站节点的问题,最好是能配置。java有很多工具可以解析html,如:htmlparser、htmlcleaner等。但是多网站做到可以配置还是比较麻烦的,当时我就想到能否使用xpath,但是java原声带的xpath对xml格式要求非常严格,大家都知道html结构不是严谨的xml格式,html没有要求严格的闭包,所以这个是行不通的。后来经过查阅资料,htmlcleaner支持xpath语法,这真是一个天大的好消息,因为没有它我们就得自己写一大堆配置文件,自己根据配置文件来解析html,非常耗时。有了htmlCleaner,通过配置xpath即可找到节点。下面是个cleaner使用简单的例子:
HtmlCleaner cleaner = new HtmlCleaner();
TagNode root = cleaner.clean(respStr);
//=======================开始搜集数据=================================
// 新闻标题
// conf.getNewsTitleX()是读取了我配置文件配置的newsTitle的xpath语法
Object title[] = root.evaluateXPath(conf.getNewsTitleX());
if(title.length > 0 && checkType(title[0])) {
this.title = ((TagNode)title[0]).getText().toString().trim();
}下面是我其中一个网站的配置文件:
crawler.name = hkzx
crawler.charset = utf-8
crawler.depth = 4
crawler.url.index = http://www.aviationnow.com.cn/Page/News_Search.aspx
crawler.url.default.head=http://www.aviationnow.com.cn/Page/
crawler.url.reg =^http://www.aviationnow.com.cn/Page/News_details.aspx\\?id=[0-9a-z-]+$
crawler.html.title =//body//div[@class='NewsDetails_Title']//span[@id='d_title'] ##注意看这里,这就是取title的表达式 对应java中的conf.getNewsTitleX()
crawler.html.content = //body//div[@class='NewsDetails_Text']
crawler.html.pubtime =//body//div[@class='NewsDetails_date']
crawler.html.from = //body//div[@class='NewsDetails_source']
crawler.html.readcount =
crawler.html.tag =
crawler.html.keywords =
实现三:在以上工作都完成之后,内容可以抓取到,时间也可以抓取到,但是抓取的时候遇到一个问题,由于网站设计原因,有些程序员会把一些文字如:发表者、发表时间、来源等放到一个标签里面,然后这个标签里面又包含其他标签。
<div class='article_info'><span>发表者:<span>张三</span> 来源:测试网站 发表时间:2015-10-10 00:00:00</span></div>如果要取来源xpath只能定位到节点“//body//div[@class='article_info']//span[1]” ,取出来的innerHtml是 “发表者:<span>张三</span> 来源:测试网站 发表时间:2015-10-10 00:00:00”这种情况后来想想也只能个性化处理了。设置一个filter接口,通过配置文件配置提取某个字段的时候 最字段进行过滤,比如string.subString("空格")[1]来取来源,后来想想其实配置文件中支持配置groovy脚本也是相当不错的,哈哈
开发中需要注意的事项:
1.提取网站url的时候,有些新闻发布网站a标签和iframe标签的链接不会写全类似:http://xxxx.com/article/1234556, 而是直接平级链接如<a href='./11212121' >文章1</a>,这种情况需要处理好
2.被抓取的网站html结构随时发生变更,需要通过查看内容抓取正确来判断网站结构是否发生变化。
3.异步加载的数据一时间没想到怎么去抓
4.要设置访问链接指纹,访问过的就不要再访问了避免循环抓取。数据量巨大的时候可以使用bloomfilter,不大的时候直接hashset就够了。















 4577
4577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









