






前言
要通过elasticsearch实现数据检索,首先要将数据导入elasticsearch,并实现数据源与elasticsearch数据同步.这里使用的数据源是Mysql数据库.目前mysql与elasticsearch常用的同步机制大多是基于插件实现的,常用的插件包括:logstash-input-jdbc,go-mysql-elasticsearch, elasticsearch-jdbc。
插件优缺点对比
1. logstash-input-jdbc
logstash官方插件,集成在logstash中,下载logstash即可,通过配置文件实现mysql与elasticsearch数据同步
优点
- 能实现mysql数据全量和增量的数据同步,且能实现定时同步.
- 版本更新迭代快,相对稳定.
- 作为ES固有插件logstash一部分,易用
缺点
- 不能实现同步删除操作,MySQL数据删除后Elasticsearch中数据仍存在.
- 同步最短时间差为一分钟,一分钟数据同步一次,无法做到实时同步.
2. go-mysql-elasticsearch
go-mysql-elasticsearch 是国内作者开发的一款插件
优点
- 能实现mysql数据增加,删除,修改操作的实时数据同步
缺点
- 无法实现数据全量同步Elasticsearch
- 仍处理开发、相对不稳定阶段
3. elasticsearch-jdbc
目前最新的版本是2.3.4,支持的ElasticSearch的版本为2.3.4, 未实践
优点
- 能实现mysql数据全量和增量的数据同步.
缺点
- 目前最新的版本是2.3.4,支持的ElasticSearch的版本为2.3.4
- 不能实现同步删除操作,MySQL数据删除后Elasticsearch中数据仍存在.
方案一:logstash-input-jdbc实现mysql数据库与elasticsearch同步
1.安装
logstash5.x之后,集成了logstash-input-jdbc插件。安装logstash后通过命令安装logstash-input-jdbc插件
cd /logstash-6.4.2/bin
./logstash-plugin install logstash-input-jdbc2.配置
在logstash-6.4.2/config文件夹下新建jdbc.conf,配置内容如下
# 输入部分
input {
stdin {}
jdbc {
# mysql数据库驱动
jdbc_driver_library => "/usr/local/logstash-6.4.2/config/mysql-connector-java-5.1.30.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
# mysql数据库链接,数据库名
jdbc_connection_string => "jdbc:mysql://localhost:3306/octopus"
# mysql数据库用户名,密码
jdbc_user => "root"
jdbc_password => "12345678"
# 设置监听间隔 各字段含义(分、时、天、月、年),全部为*默认含义为每分钟更新一次
schedule => "* * * * *"
# 分页
jdbc_paging_enabled => "true"
# 分页大小
jdbc_page_size => "50000"
# sql语句执行文件,也可直接使用 statement => 'select * from t_employee'
statement_filepath => "/usr/local/logstash-6.4.2/config/jdbc.sql"
# elasticsearch索引类型名
type => "t_employee"
}
}
# 过滤部分(不是必须项)
filter {
json {
source => "message"
remove_field => ["message"]
}
}
# 输出部分
output {
elasticsearch {
# elasticsearch索引名
index => "octopus"
# 使用input中的type作为elasticsearch索引下的类型名
document_type => "%{type}" # <- use the type from each input
# elasticsearch的ip和端口号
hosts => "localhost:9200"
# 同步mysql中数据id作为elasticsearch中文档id
document_id => "%{id}"
}
stdout {
codec => json_lines
}
}
# 注: 使用时请去掉此文件中的注释,不然会报错在logstash-6.4.2/config 目录下新建jdbc.sql文件
select * from t_employee3.运行
cd logstash-6.4.2
# 检查配置文件语法是否正确
bin/logstash -f config/jdbc.conf --config.test_and_exit
# 启动
bin/logstash -f config/jdbc.conf --config.reload.automatic--config.reload.automatic: 会自动重新加载配置文件内容
在kibana中创建索引后查看同步数据
PUT octopus
GET octopus/_search方案二: go-mysql-elasticsearch实现mysql数据库与elasticsearch同步
1. mysql binlog日志
go-mysql-elasticsearch通过mysql中binlog日志实现数据增加,删除,修改同步elasticsearch
mysql的binlog日志主要用于数据库的主从复制与数据恢复。binlog中记录了数据的增删改查操作,主从复制过程中,主库向从库同步binlog日志,从库对binlog日志中的事件进行重放,从而实现主从同步。
mysql binlog日志有三种模式,分别为:
ROW: 记录每一行数据被修改的情况,但是日志量太大
STATEMENT: 记录每一条修改数据的SQL语句,减少了日志量,但是SQL语句使用函数或触发器时容易出现主从不一致
MIXED: 结合了ROW和STATEMENT的优点,根据具体执行数据操作的SQL语句选择使用ROW或者STATEMENT记录日志
要通过mysql binlog将数据同步到ES集群,只能使用ROW模式,因为只有ROW模式才能知道mysql中的数据的修改内容。
以UPDATE操作为例,ROW模式的binlog日志内容示例如下:
SET TIMESTAMP=1527917394/*!*/;
BEGIN
/*!*/;
# at 3751
#180602 13:29:54 server id 1 end_log_pos 3819 CRC32 0x8dabdf01 Table_map: `webservice`.`building` mapped to number 74
# at 3819
#180602 13:29:54 server id 1 end_log_pos 3949 CRC32 0x59a8ed85 Update_rows: table id 74 flags: STMT_END_F
BINLOG '
UisSWxMBAAAARAAAAOsOAAAAAEoAAAAAAAEACndlYnNlcnZpY2UACGJ1aWxkaW5nAAYIDwEPEREG
wACAAQAAAAHfq40=
UisSWx8BAAAAggAAAG0PAAAAAEoAAAAAAAEAAgAG///A1gcAAAAAAAALYnVpbGRpbmctMTAADwB3
UkRNbjNLYlV5d1k3ajVbD64WWw+uFsDWBwAAAAAAAAtidWlsZGluZy0xMAEPAHdSRE1uM0tiVXl3
WTdqNVsPrhZbD64Whe2oWQ==
'/*!*/;
### UPDATE `webservice`.`building`
### WHERE
### @1=2006 /* LONGINT meta=0 nullable=0 is_null=0 */
### @2='building-10' /* VARSTRING(192) meta=192 nullable=0 is_null=0 */
### @3=0 /* TINYINT meta=0 nullable=0 is_null=0 */
### @4='wRDMn3KbUywY7j5' /* VARSTRING(384) meta=384 nullable=0 is_null=0 */
### @5=1527754262 /* TIMESTAMP(0) meta=0 nullable=0 is_null=0 */
### @6=1527754262 /* TIMESTAMP(0) meta=0 nullable=0 is_null=0 */
### SET
### @1=2006 /* LONGINT meta=0 nullable=0 is_null=0 */
### @2='building-10' /* VARSTRING(192) meta=192 nullable=0 is_null=0 */
### @3=1 /* TINYINT meta=0 nullable=0 is_null=0 */
### @4='wRDMn3KbUywY7j5' /* VARSTRING(384) meta=384 nullable=0 is_null=0 */
### @5=1527754262 /* TIMESTAMP(0) meta=0 nullable=0 is_null=0 */
### @6=1527754262 /* TIMESTAMP(0) meta=0 nullable=0 is_null=0 */
# at 3949
#180602 13:29:54 server id 1 end_log_pos 3980 CRC32 0x58226b8f Xid = 182
COMMIT/*!*/;
STATEMENT模式下binlog日志内容示例为:
SET TIMESTAMP=1527919329/*!*/;
update building set Status=1 where Id=2000
/*!*/;
# at 688
#180602 14:02:09 server id 1 end_log_pos 719 CRC32 0x4c550a7d Xid = 200
COMMIT/*!*/;
从ROW模式和STATEMENT模式下UPDATE操作的日志内容可以看出,ROW模式完整地记录了要修改的某行数据更新前的所有字段的值以及更改后所有字段的值,而STATEMENT模式只单单记录了UPDATE操作的SQL语句。我们要将mysql的数据实时同步到ES, 只能选择ROW模式的binlog, 获取并解析binlog日志的数据内容,执行ES document api,将数据同步到ES集群中。
查看,修改binlog模式
# 查看binlog模式
mysql> show variables like "%binlog_format%";
# 修改binlog模式
mysql> set global binlog_format='ROW';
# 查看binlog是否开启
mysql> show variables like 'log_bin';
# 开启bīnlog
修改my.cnf文件log-bin = mysql-bin2. 安装
# 安装go
sudo apt-get install go
# 安装godep
go get github.com/tools/godep
# 获取go-mysql-elasticsearch插件
go get github.com/siddontang/go-mysql-elasticsearch
# 安装go-mysql-elasticsearch插件
cd go/src/github.com/siddontang/go-mysql-elasticsearch
make3. 配置
go/src/github.com/siddontang/go-mysql-elasticsearch/etc/river.toml
# MySQL address, user and password
# user must have replication privilege in MySQL.
my_addr = "127.0.0.1:3306" # 需要同步的mysql基本设置
my_user = "root"
my_pass = "root"
# Elasticsearch address
es_addr = "127.0.0.1:9200" # 本地elasticsearch配置
# Path to store data, like master.info, and dump MySQL data
data_dir = "./var" # 数据存储的url
# 以下配置保存默认不变
# Inner Http status address
stat_addr = "127.0.0.1:12800"
# pseudo server id like a slave
server_id = 1001
# mysql or mariadb
flavor = "mysql"
# mysqldump execution path
mysqldump = "mysqldump"
# MySQL data source
[[source]]
schema = "test" //elasticsearch 与 mysql 同步时对应的数据库名称
# Only below tables will be synced into Elasticsearch.
# 要同步test这个database里面的几张表。对于一些项目如果使用了分表机制,我们可以用通配符来匹配,譬如t_[0-9]{4},就可# 以匹配 table t_0000 到 t_9999。
tables = ["t", "t_[0-9]{4}", "tfield", "tfilter"]
# Below is for special rule mapping
# 对一个 table,我们需要指定将它的数据同步到 ES 的哪一个 index 的 type 里面。如果不指定,我们默认会用起 schema # name 作为 ES 的 index 和 type
[[rule]]
schema = "test" //数据库名称
table = "t" //表名称
index = "test" //对应的索引名称
type = "t" //对应的类型名称
# 将所有满足格式 t_[0-9]{4} 的 table 同步到 ES 的 index 为 test,type 为 t 的下面。当然,这些表需要保证
# schema 是一致的
[[rule]]
schema = "test"
table = "t_[0-9]{4}"
index = "test"
type = "t"
# 对于 table tfilter,我们只会同步 id 和 name 这两列,其他的都不会同步
filter = ["id", "name"]
# table tfield 的 column id ,我们映射成了 es_id,而 tags 则映射成了 es_tags
# list 这个字段,他显示的告知需要将对应的 column 数据转成 ES 的 array type。这个现在通常用于 MySQL 的 varchar # 等类型,我们可能会存放类似 “a,b,c” 这样的数据,然后希望同步给 ES 的时候变成 [a, b, c] 这样的列表形式。
[rule.field]
# Map column `id` to ES field `es_id`
id="es_id"
# Map column `tags` to ES field `es_tags` with array type
tags="es_tags,list"
# Map column `keywords` to ES with array type
keywords=",list"
4. 运行
cd go/src/github.com/siddontang/go-mysql-elasticsearch
bin/go-mysql-elasticsearch -config=./etc/river.toml方案三: Apache-NiFi实现mysql数据与elasticsearch同步
1. 背景
NiFi之前是在美国国家安全局(NSA)开发和使用了8年的一个可视化、可定制的数据集成产品。2014年NSA将其贡献给了Apache开源社区,2015年7月成功成为Apache顶级项目。
2. 简介
Apache NiFi 是一个易于使用、功能强大而且可靠的数据处理和分发系统。Apache NiFi 是为数据流设计,它支持高度可配置的指示图的数据路由、转换和系统中介逻辑,支持从多种数据源动态拉取数据。简单地说,NiFi是为自动化系统之间的数据流而生。 这里的数据流表示系统之间的自动化和受管理的信息流。 基于WEB图形界面,通过拖拽、连接、配置完成基于流程的编程,实现数据采集、处理等功能。
3. 下载安装配置
- Apache NiFi 基于 java 开发,要求运行环境为 JDK 8.0 以上。
- Apache NiFi 下载地址:http://nifi.apache.org/download.html
- 常用配置在 conf 目录下的 nifi.properties 和 bootstrap.conf 文件中,详见:NiFi System Administrator's Guide
- web 控制台端口在 nifi.proerties 文件中的
nifi.web.http.port参数修改,默认值8080
4. 启动Apache NiFi
命令行进入 Apache NiFi 目录,运行命令 ./bin/nifi.sh start
Apache NiFi 的常用命令:
| 命令 | 说明 |
|---|---|
| run | 交互式启动 |
| start | 后台启动 |
| stop | 停止 |
| status | 查看服务状态 |
5. 实例应用
描述
数字图书馆有一套基于 MySQL 的电子书管理系统,电子书的基本信息保存在数据库表中,书的数字内容以多种常见的文档格式(PDF、Word、PPT、RTF、TXT、CHM、EPUB等)保存在存储系统中。现在需要利用 ElasticSearch 实现一套全文检索系统,以便用户可以通过对电子书的基本信息和数字内容进行模糊查询,快速找到相关书籍。
数据库表结构
CREATE TABLE `book` (
`id` varchar(100) NOT NULL,
`title` varchar(50) DEFAULT NULL,
`desc` varchar(1000) DEFAULT NULL,
`path` varchar(200) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8| 字段 | 意义 |
|---|---|
| id | 主键 |
| title | 书名 |
| desc | 介绍 |
| path | 存储路径 |
| create_time | 创建时间 |
| update_time | 更新时间 |
逻辑约束:创建书籍记录时,create_time 等于 update_time,即当前时间,每次更新书籍时,更新 update_time 时间。全文检索系统根据 update_time 时间更新书籍索引。
技术方案
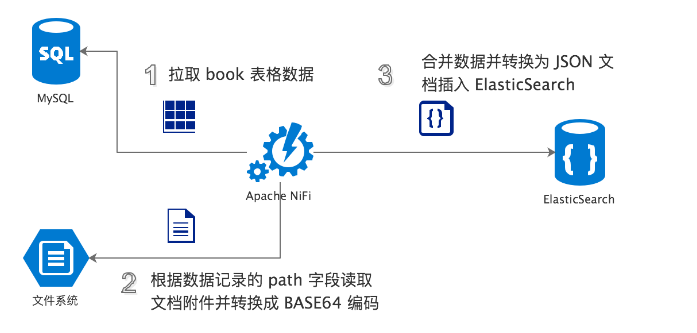
基本思路:
- 定期扫描 MySQL 中的 book 表,根据字段 update_time 批量抓取最新的电子书数据。
- 从 path 字段获取电子书数字内容的文档存储路径。从存储系统中抓取电子书文档并进行 BASE64编码。
- 将从 book 表批量抓取的数据转换为 JSON 文档,并将 BASE64编码后的电子书文档合并入 JSON,一同写入 ElasticSearch,利用 ElasticSearch 的插件 Ingest Attachment Processor Plugin 对电子书文档进行文本抽取,并进行持久化,建立全文索引。
文档附件的文本抽取
ElasticSearch只能处理文本,不能直接处理二进制文档。要利用 ElasticSearch 实现附件文档的全文检索需要 2 个步骤:
- 对多种主流格式的文档进行文本抽取。
- 将抽取出来的文本内容导入 ElasticSearch ,利用 ElasticSearch强大的分词和全文索引能力。
Ingest Attachment Processor Plugin 是一个开箱即用的插件,使用它可以帮助 ElasticSearch 自动完成这 2 个步骤。
基本原理是利用 ElasticSearch 的 Ingest Node 功能,此功能支持定义命名处理器管道 pipeline,pipeline中可以定义多个处理器,在数据插入 ElasticSearch 之前进行预处理。而 Ingest Attachment Processor Plugin 提供了关键的预处理器 attachment,支持自动对入库文档的指定字段作为文档文件进行文本抽取,并将抽取后得到的文本内容和相关元数据加入原始入库文档。
因为 ElasticSearch 是基于 JSON 格式的文档数据库,所以附件文档在插入 ElasticSearch 之前必须进行 Base64 编码。
当然,Attachment Processor Plugin 不是唯一方案。如果需要深入定制文档抽取功能,或基于功能解耦等考量,完全可以利用 Apache Tika http://tika.apache.org 实现独立的文档抽取应用。
安装附件文本抽取插件
cd elasticsearch-6.4.2
./bin/elasticsearch-plugin install ingest-attachment安装中文分词插件
cd elasticsearch-6.4.2
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.4.2/elasticsearch-analysis-ik-6.4.2.zip
使用kibana建立文本抽取管道
PUT /_ingest/pipeline/attachment
{
"description": "Extract attachment information",
"processors": [
{
"attachment": {
"field": "data",
"ignore_missing": true
}
},
{
"remove": {
"field": "data"
}
}
]
}以上,我们建立了 一个 pipeline 命名 attachment,其中定义了 2 个预处理器 "attachment" 和 "remove" ,它们按定义顺序对入库数据进行预处理。
"attachment" 预处理器即上文安装的插件 "Ingest Attachment Processor Plugin" 提供,将入库文档字段 "data" 视为文档附件进行文本抽取。要求入库文档必须将文档附件进行 BASE64编码写入 "data" 字段。
文本抽取后, 后续不再需要保留 BASE64 编码的文档附件,将其持久化到 ElasticSearch 中没有意义,"remove" 预处理器用于将其从源文档中删除。
使用kibana建立文档结构映射
ElasticSearch 是文档型数据库,以 JSON 文档为处理对象。文档结构以 mapping 形式定义,相当于关系型数据库建立表结构。以下,我们建立 MySQL 的 book 表在 ElasticSearch 中的文档结构映射。
PUT /book
{
"mappings": {
"idx": {
"properties": {
"id": {
"type": "keyword"
},
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"desc": {
"type": "text",
"analyzer": "ik_max_word"
},
"path": {
"type": "keyword"
},
"create_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"update_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"attachment": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
}
}除了 book 表中的原有字段外,我们在 ElasticSearch 中增加了 "attachment" 字段,这个字段是 "attachment" 命名 pipeline 抽取文档附件中文本后自动附加的字段。这是一个嵌套字段,其包含多个子字段,包括抽取文本 content 和一些文档信息元数据。
在本文的应用场景中,我们需要对 book 的 title、desc 和 attachment.content 进行全文检索,所以在建立 mapping 时,我们为这 3 个字段指定分析器 "analyzer" 为 "ik_max_word",以让 ElasticSearch 在建立全文索引时对它们进行中文分词。
导入apache NiFi流程模板
Apache NiFi 支持将配置好的流程保存为模板,鼓励社区开发者之间分享模板。本文及使用的流程模板在开源项目:
https://gitee.com/streamone/full-text-search-in-action
模板文件在 /nifi/FullText-mysql.xml
下载模板文件 FullText-mysql.xml ,然后点击控制台左侧 "Operate" 操作栏里的 "Upload Template" 上传模板。
应用流程模板
拖拽控制台顶部一排组件图标中的 "Template" 到空白网格区域,在弹出的 "Add Template" 窗口中选择刚刚上传的模板 "FullText-mysql",点击 "Add"。空白网格区域将出现如下下图的 "process group",它是一组 "processor" 的集合,我们的处理流程就是由这组 "processor" 按照数据处理逻辑有序组合而成。
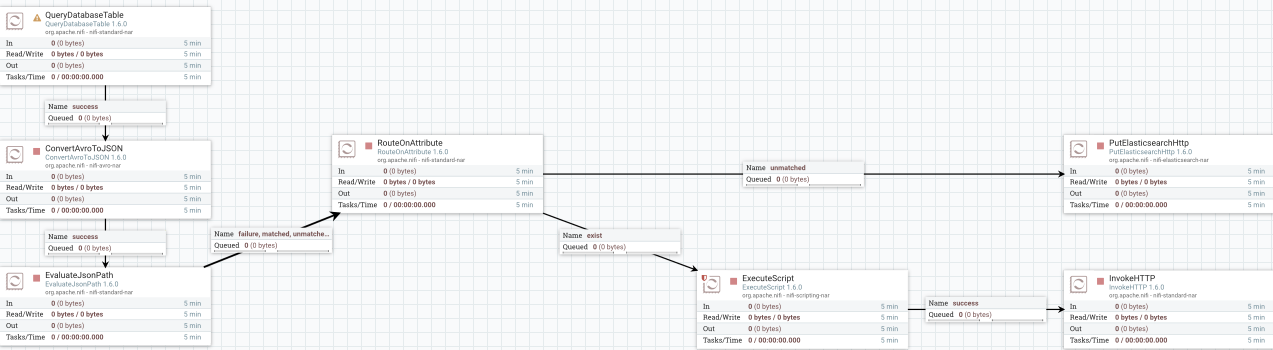
双击此 "process group" 进入,将看到完整的流程配置,如下图:
运行这个流程之前需要完成几个配置项:
-
配置并启动数据库连接池
在空白网格处点击鼠标右键,在弹出菜单中点击 "configure",在弹出的 "FullText-mysql Configuration" 窗口中打开 "controller services" 标签页如下图,点击表格中 "DBCPConnectionPool" 右侧 "Configure" 图标,进行数据库连接池配置。
在弹出的 "Configure Controller Service" 窗口中打开 "PROPERTIES" 标签页,在表格中填写 MySQL数据库相关信息,如下图: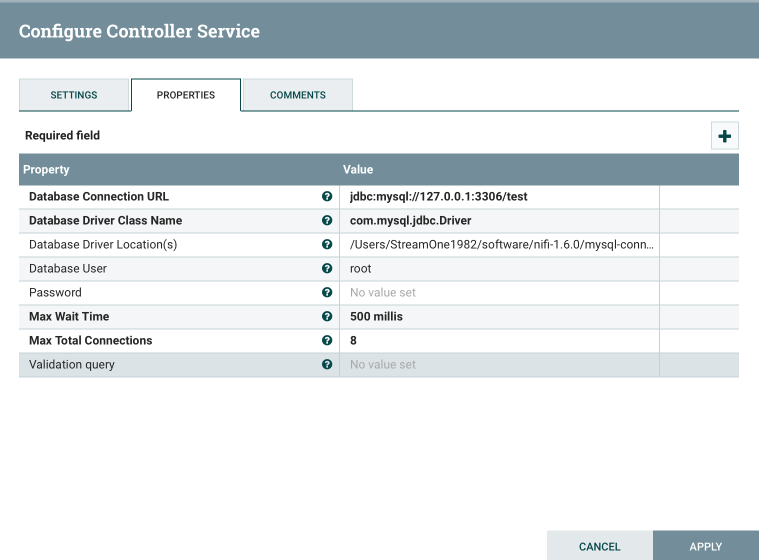
其中的 "Database Driver Location(s)" 填写我们下载的 "mysql-connector-java-5.1.46-bin.jar" 路径。 配置好数据库连接池以后点击 "APPLY" 回到 "controller services" 标签页,点击表格中 “DBCPConnectionPool” 右侧 “Enable” 图标启动数据库连接池。 -
修改变量
在空白网格处点击鼠标右键,在弹出菜单中点击 "variables",打开 "Variables" 窗口,修改表格中的 "elasticSearchServer" 参数值为 ElasticSearch 服务地址,修改表格中的 "rootPath" 参数为电子书数字文档在文件系统中的根路径。
回到 "process group" 流程页面,在空白网格处点击鼠标右键,在弹出菜单中点击 "start" 菜单,启动流程。
至此,我们完成了本文应用场景中 Apache NiFi 的流程配置。Apache NiFi 每隔 10 秒扫描 MySQL 的 book 表,抓取最新的电子书数据,处理后导入 ElasticSearch。
全文检索查询
book表数据

全文检索语句
GET /book/_search
{
"query": {
"multi_match": {
"query": "安静",
"fields": ["title", "desc", "attachment.content"]
}
},
"_source": {
"excludes": ["attachment.content"]
},
"from": 0, "size": 200,
"highlight": {
"encoder": "html",
"pre_tags": ["<em>"],
"post_tags": ["</em>"],
"fields": {
"title": {},
"desc": {},
"attachment.content": {}
}
}
}查询结果
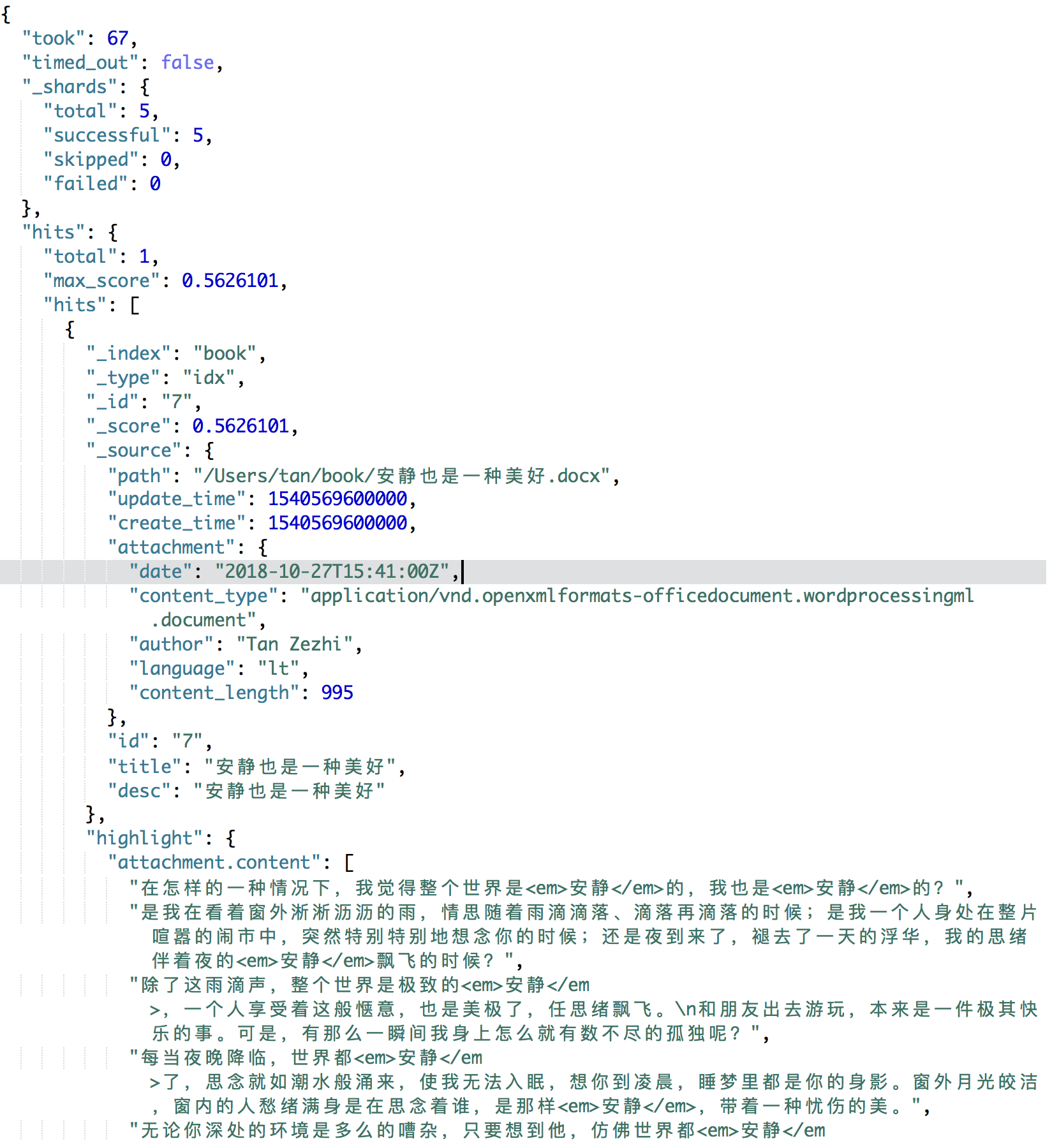
参考链接
https://www.jianshu.com/p/c3faa26bc221















 1737
1737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









