import xlwt
import requests
from bs4 import BeautifulSoup
import re
url = "https://music.163.com/discover/artist/cat?id=1001"#'http://music.163.com/discover/artist/cat?id=1001'#华语男歌手页面
head={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.169.400 QQBrowser/11.0.5130.400"}
r = requests.get(url,headers=head)
#r.raise_for_status()
#r.encoding = r.apparent_encoding
html=r.text #获取整个网页
#print(html)
soup = BeautifulSoup(html,'html.parser') #
top_10 = soup.find_all('div',attrs = {'class':'u-cover u-cover-5'})
#print(top_10)
singers = []
for i in top_10:
singers.append(re.findall(r'.*?<a class="msk" href="(/artist\?id=\d+)" title="(.*?)的音乐"></a>.*?',str(i))[0])
print(singers)
book = xlwt.Workbook()
url = 'http://music.163.com'
for singer in singers:
new_url = url + str(singer[0])
#print(new_url)
head={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.169.400 QQBrowser/11.0.5130.400"}
songs=requests.get(new_url,headers=head).text
soup = BeautifulSoup(songs,'html.parser')
Info = soup.find_all('textarea',attrs = {'style':'display:none;'})[0]
songs_url_and_name = soup.find_all('ul',attrs = {'class':'f-hide'})[0]
#print(songs_url_and_name)
datas = []
data1 = re.findall(r'"album".*?"name":"(.*?)".*?',str(Info.text))
data2 = re.findall(r'.*?<li><a href="(/song\?id=\d+)">(.*?)</a></li>.*?',str(songs_url_and_name))
for i in range(len(data2)):
datas.append([data2[i][1],data1[i],'http://music.163.com/#'+ str(data2[i][0])])
#print(datas)
sheet1=book.add_sheet(str(singer[1]),cell_overwrite_ok =True)#(添加工作表,并设置同一单元格可以重复写入)
sheet1.col(0).width = (25*256)
sheet1.col(1).width = (30*256)
sheet1.col(2).width = (40*256)
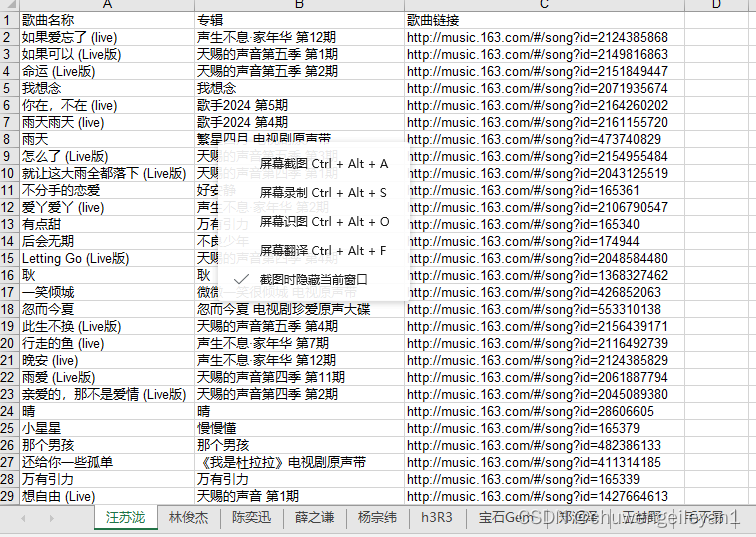
heads=['歌曲名称','专辑','歌曲链接']
count=0
for head in heads:
sheet1.write(0,count,head)
count+=1
i=1
for data in datas:
j=0
for k in data:
sheet1.write(i,j,k)
j+=1
i+=1
book.save(str(singer[1])+'.xls')#括号里写存入的地址
book.save("1.xls")#括号里写存入的地址






















 236
236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









