







文章目录
负载均衡式在线OJ
1.项目技术和开发环境
项目技术
- C++ STL 标准库
- Boost 库
- cpp-httplib 第三方开源网络库
- ctemplate 第三方开源前端网页渲染库
- jsoncpp 第三方开源序列化、反序列化库
- 负载均衡设计
- 多进程、多线程
- MySQL C Connect
- html /css/js/jquery/ajax
开发环境
- centos 7 服务器
- vim / gcc(g++) / makefile
2. 结构设计和实现思路
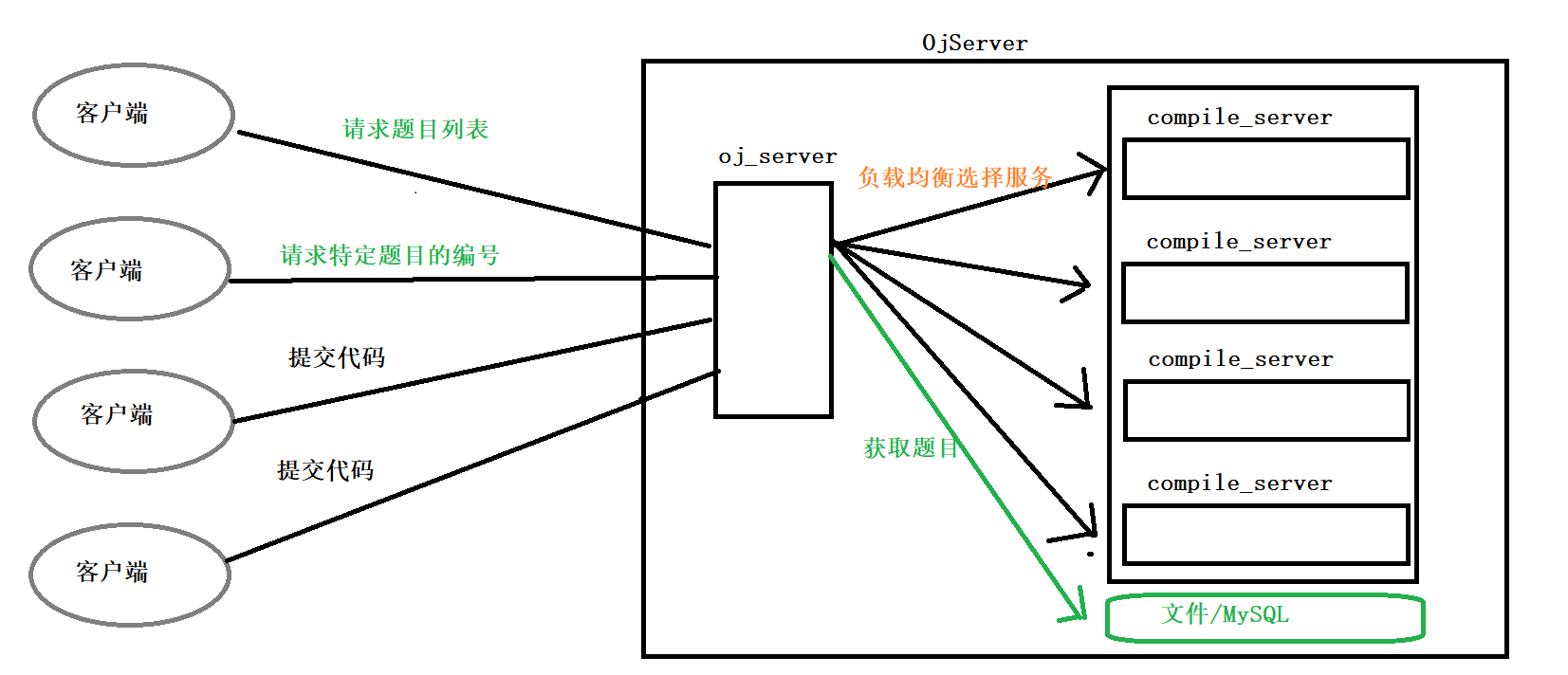
1)如果用户请求的是:题目列表/特定的题目, 此时并不需要对代码进行编译,只需要通过oj_server访问后端的数据库/文件去拉取对应的题目列表/题目即可
2)如果用户请求的是:提交代码,此时就需要oj_server负载均衡的选择一台后端主机进行编译服务
编译服务器和OJ服务器,两个模块之间采用网络套接字的方式互相通信,就可以把编译模块部署在服务器的多台机器上,OJ服务只需要一台,能够以集群处理的方式对外输出在线OJ服务
项目宏观结构
我们的项目核心是如下三个模块:
| 目录 | 介绍 |
|---|---|
comm |
公共模块,存放公用的代码如一些工具类:文件操作,字符串处理,日志 |
compile_server |
编译运行模块,让用户的代码在自己的服务器上形成临时文件,并且编译,运行,得到运行结果 |
oj_server |
采用MAC的设计模式,使用算法负载均衡式的调用编译模块以及访问文件或数据库,把题目列表和编辑界面展示给用户 |
关于题目:实现两个版本:文件版本和数据库版本
用户直接访问的是OJServer模块,OJServer收到请求后会进行功能路由,根据不同的请求给用户返回不同的结果,如果用户是提交代码,那么OJServer模块还会更具后端的CompilerServer服务器的负载负载均衡的选择主机提供的编译服务,然后拿到编译的结果在给用户返回
项目目录结构大致如下:
Online_judge/
├── comm/ //存放工具模块
│ ├── httplib.h -> ../third_part/cpp-httplib/httplib.h
│ ├── log.hpp //日志类
│ └── util.hpp //工具类:路径,时间,文件,字符串相关工具
├── compile_server/ //编译运行模块
│ ├── compile_server.cc //以网络的形式,对外提供服务
│ ├── compile_run.hpp //对外提供接口 -编译并且运行
│ ├── compiler.hpp //编译
│ ├── runner.hpp //运行
│ ├── Makefile
│ └── temp/
├── oj_server/ //负责负载均衡的调用
│ ├── oj_server.cc //我们要形成的网络服务 -> 负载均衡式的去调用后端的编译服务
│ ├── oj_model.hpp //主要用来和数据进行交互,对外提供访问数据的接口
│ ├── oj_control.hpp
│ ├── oj_view.hpp //形成网页给用户显示
│ └── Makefile
└── Makefile
3.日志模块-log.hpp
日志功能整个项目都要使用,所以自然应该属于Comm公共模块,在Comm目录下创建一个专属的log.hpp文件
我们将日志设计为五个等级:
- INFO:表示正常的打印信息
- DEBUG:表示用来dubug的信息
- WARNING:警告,但是不影响继续使用,但存在风险
- ERROR:错误,用户无法正常使用了,但该事件不影响服务器继续运行
- FATAL:致命错误,该事件将导致服务器停止运行
上述的等级,可以通过枚举定义
日志说明:
- 日志级别: 分为5个等级,从低到高依次是INFO、DEBUG,WARNING、ERROR、FATAL
- 时间戳: 事件产生的时间
- 日志信息: 事件产生的日志信息
- 错误文件名称: 事件在哪一个文件产生
- 行数: 事件在对应文件的哪一行产生
关于时间戳:
方法1:调用time函数时传入nullptr即可获取当前的时间戳
方法2:调用时间工具类的函数
关于文件名称和行数的问题
1)通过C语言中的预定义符号__FILE__和_LINE_,分别可以获取当前文件的名称和当前的行数,但最好在调用Log函数时不用调用者显示的传入__FILE__和__LINE__,因为每次调用Log函数时传入的这两个参数都是固定的,
2)需要注意的是,不能将__FILE__和__LINE__设置为参数的缺省值,因为这样每次获取到的都是Log函数所在的文件名称和所在的行数,而宏可以在预处理期间将代码插入到目标地点,因此我们可以定义如下宏:
#define LOG(level) Log(#level, __FILE__, __LINE__)
Log函数返回的是输出流对象,调用该日志的方法是:LOG(level)<<“日志信息”<<endl,我们这里的是开放式的日志
#pragma once
#include <iostream>
#include <string>
#include "util.hpp"
namespace ns_log
{
using namespace ns_util;//使用时间工具类
// 日志等级
enum
{
INFO,
DEBUG,
WARNING,
ERROR,
FATAL
};
//参数:日志等级 在哪个文件打的日志 哪一行,方便追溯出错原因
//将来是这样调用的: LOG(INFO) << "message输出信息" << "\n";
//返回值:标准输出std::cout
inline std::ostream &Log(const std::string &level, const std::string &file_name, int line)
{
// 添加日志等级
std::string message = "[";
message += level;
message += "]";
// 添加报错文件名称
message += "[";
message += file_name;
message += "]";
// 添加报错行
message += "[";
message += std::to_string(line);
message += "]";
// 日志时间戳 是什么时候打印的报错信息
message += "[";
message += TimeUtil::GetTimeStamp();
message += "]";
// cout 本质内部是包含缓冲区的 ,将刚才的message写入到缓冲区
std::cout << message; //不要endl进行刷新,此时message就会暂存到cout的缓冲区当中
return std::cout;
}
// 将来是这样调用的: LOG(等级) << "message" << "\n";
// 开放式日志
#define LOG(level) Log(#level, __FILE__, __LINE__) //给宏参带#,将宏名称以字符串形式进行展示
}
4.公共模块 -comm存放工具类
我们定义一个名字为comm的文件夹,里面存放我们需要用的公共内容: 日志模块 + 工具类 + httplib.h
comm/httplib.h
comm/log.hpp
comm/util.hpp
关于路径的工具类-PathUtil
后序我们进行编译及运行,都只是只传入文件的名字,所以我们要根据文件的名字,拼接出带路径的文件名字+后缀
需要形成的文件的路径:源文件,可执行程序,编译报错文件,标准输入,标准输出,标准错误文件
后缀分别为: .cpp .exe .compile_error .stdin .stdout .stderr
做法:定义一个函数:AddSuffix,用于给指定名字的文件添加后缀和路径,后序只需要传递对应的文件名+后缀即可
const std::string temp_path = "./temp/"; //生成的文件保存的位置,也就是compiler_server/temp下
class PathUtil //提供对路径的操作方法-路径工具
{
public:
//添加后缀
static std::string AddSuffix(const std::string &file_name, const std::string &suffix)
{
//例如:file_name=1234
std::string path_name = temp_path ;// ./temp/
path_name += file_name;// ./temp/1234
path_name += suffix;// ./temp/1234.cpp
return path_name;
}
// 编译时需要有的临时文件
// 构建源文件路径+后缀的完整文件名 file_name:1234 -> 返回: ./temp/1234.cpp
static std::string Src(const std::string &file_name)
{
return AddSuffix(file_name, ".cpp");
}
// 构建可执行程序的完整路径+后缀名 file_name:1234 -> 返回: ./temp/1234.exe
static std::string Exe(const std::string &file_name)
{
return AddSuffix(file_name, ".exe");
}
static std::string CompilerError(const std::string &file_name)
{
return AddSuffix(file_name, ".compile_error"); //编译报错文件
}
//-----------------------------------------------------------------------------------
// 运行时需要的临时文件
static std::string Stdin(const std::string &file_name) //形成一个标准输入文件
{
return AddSuffix(file_name, ".stdin");
}
static std::string Stdout(const std::string &file_name)//形成一个标准输出文件
{
return AddSuffix(file_name, ".stdout");
}
// 构建该程序对应的标准错误完整的路径+后缀名 file_name:1234 -> 返回: ./temp/1234.stderr
//运行时报错的文件
static std::string Stderr(const std::string &file_name) //形成一个标准错误文件
{
return AddSuffix(file_name, ".stderr");
}
};
关于时间的工具类-TimeUtil
需要提供两个函数:
1.因为打日志我们需要知道是什么时候打的日志,所以我们需要一个可以获取系统的时间戳 (秒级别的) 函数
2.因为每时每刻都有用户在提交代码,生成对应的文件,形成的文件名必须具有唯一性,我们通过毫秒级时间戳+原子性递增唯一值来保证这个事情, 所以我们需要提供一个可以获得毫秒时间戳的函数 (如果用秒,跨度太长了,所以使用毫秒级别的)
关于gettimeofday函数
方法:使用系统调用接口gettimeofday

参数:
-
第一个参数:要获得的时间是什么,是输出型参数,返回的是当前的秒级别时间戳和微秒级别的时间戳
-
第二个参数:时区,但是我们不关心,置为空
函数返回值:
- 成功是0,失败-1,但是我们这里并不关心
class TimeUtil //关于时间的工具类
{
public:
static std::string GetTimeStamp() //获取系统的时间戳 (秒级别的)
{
struct timeval _time;
gettimeofday(&_time, nullptr);
return std::to_string(_time.tv_sec);//返回秒级别时间戳
}
//获得毫秒时间戳 ->如果用秒,跨度太长了,所以使用毫秒级别的
static std::string GetTimeMs()
{
struct timeval _time;
gettimeofday(&_time, nullptr);
//毫秒级时间戳 = 秒级别时间戳*1000 + 微秒级别时间戳/1000
return std::to_string(_time.tv_sec * 1000 + _time.tv_usec / 1000);
}
};
关于文件的工具类-FileUtil
需要提供的函数:
1.判断文件是否存在
关于stat函数
方法1:把文件以读取方式打开,如果打开失败了,说明文件不存在 -》太简单粗暴了
方法2: 使用系统调用接口stat,可以检测特定路径下的文件,获取它的属性
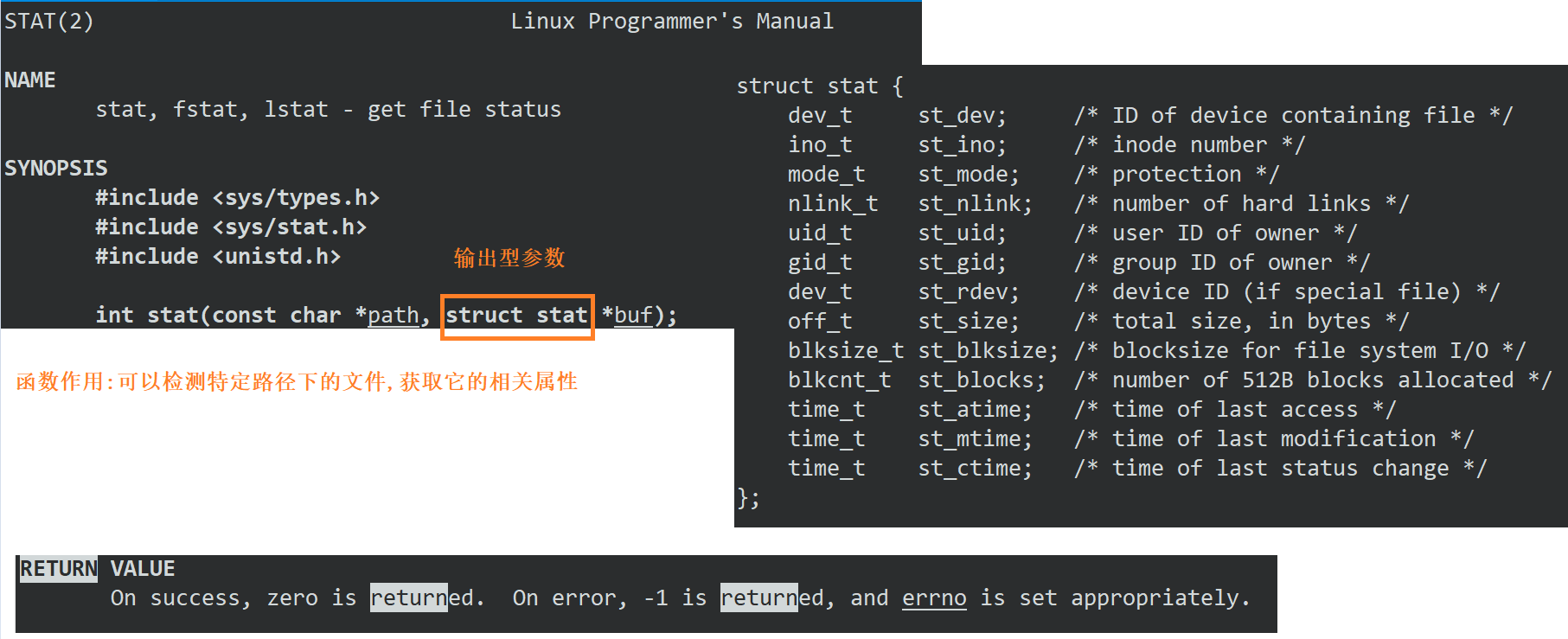
返回值:获取文件属性成功了返回0 -> 说明文件存在 如果函数返回-1,则说明文件不存在
// path_name是完整的路径 例如: ./temp/1234.stderr
static bool IsFileExists(const std::string &path_name) //判断文件是否存在
{
struct stat st;
//返回值:获取文件属性成功了返回0 -> 说明文件存在 否则返回-1
if (stat(path_name.c_str(), &st) == 0)
{
//获取属性成功,文件已经存在
return true;
}
return false;
}
2.形成唯一的文件名
方法:根据毫秒级时间戳+原子性递增唯一值: 来保证唯一性,
-
关于毫秒级时间戳: 直接复用上面时间工具类当中的函数
-
关于原子性递增唯一值:这里需要使用C++11当中的atomic,其就是原子性递增的计数器,需要引入头文件#include ,因为值是整数,所以我们使用
atomic_uint
static std::string UniqFileName() //形成唯一的文件名
{
//要定义为static,否则每一次都是对不同的id++
static std::atomic_uint id(0);
id++;//原子性++
std::string ms = TimeUtil::GetTimeMs(); //获得毫秒级别的时间戳
std::string uniq_id = std::to_string(id);//原子递增的唯一值
return ms + "_" + uniq_id;
}
3.写入文件
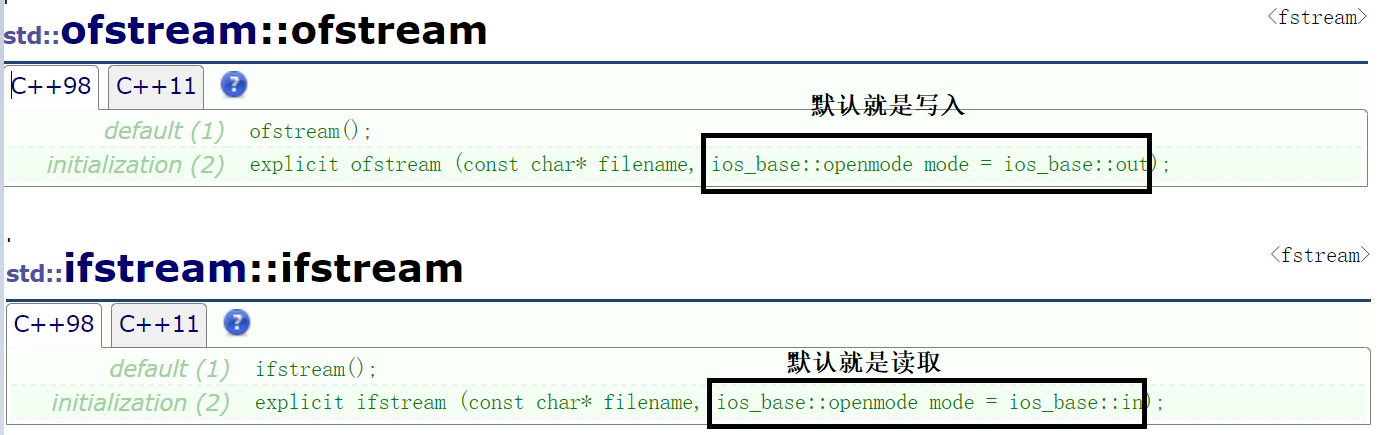
方法:打开要被写入的文件,判断是否打开成功, 如果打开失败直接返回, 打开成功:调用系统调用write函数进行写入,最后记得关闭文件流
//把content的内容写入到target文件
static bool WriteFile(const std::string &target, const std::string &content)
{
std::ofstream out(target);//打开文件,ofstream默认就是写入
if (!out.is_open())
{
return false;//打开失败
}
//第一个参数:要写谁 第二个参数:写多少个字节
out.write(content.c_str(), content.size()); //写入文件
out.close();//关闭文件流
return true;
}
4.读取文件的内容
把文件的内容读取出来, 使用getline,一次读取一行的内容,但是需要注意:getline读取一行内容的时候不保存\n,这里我们在读取的时候,有时需要保存文件当中的\n,而有时不需要保存,所以我们可以增加一个参数:是否保存\n
参数1:文件路径 参数2:输出型参数,读取的内容放到这个位置 参数3:是否需要保留\n 默认是false,表示不需要
static bool ReadFile(const std::string &target, std::string *content, bool keep = false)
{
(*content).clear();//最好先把传入的空间先清空!
std::ifstream in(target);
if (!in.is_open())
{
return false;
}
std::string line;//每次读取一行内容
// getline:不保存行分割符(\n)->不读取\n,但是有些时候需要保留\n,
// getline内部重载了强制类型转化,所以读取成功与否,有true和false保证
while (std::getline(in, line)) //第一个参数:从那里读 第二个参数:读到哪里
{
(*content) += line;
(*content) += (keep ? "\n" : ""); //如果keep为真:保留\n
}
in.close();//关闭文件流!
return true;
}
关于字符串的工具类-StringUtil
1.字符串切分函数
关于boost::split函数
这里我们需要使用boost库当中的split函数,需要引入头文件:#include <boost/algorithm/string.hpp>
函数原型
boost::split(type, select_list, boost::is_any_of(","), boost::token_compress_off)
第一个参数:用于存放切割好的字符串
第二个参数:要切割的字符串,可以为空
第三个参数 :切割符(分隔符)
第四个参数:是一个选项,token_compress_on或者token_compress_off,默认是token_compress_off

如果是token_compress_on:含义就是将连续多个分隔符当一个, 一般建议打开!
例子: 针对第四个参数: aaa\3\3\3\3bb 如果是token_compress_on:意思就是把字符串压缩成:aaa\3bb,然后切分
class StringUtil //进行字符串切分
{
public:
//第一个参数:切分谁 第二个参数: 切分好的内容放到哪里 第三个参数:以什么为分隔符切分
static void SplitString(const std::string &target, std::vector<std::string> *out, const std::string &sep)
{
//is_any_of表示:凡是在这个里面的任何一个字符都作为原始字符串当中的分隔符
//第一个参数:保存在哪里 第二个参数:数据源 第三个:分隔符
//第四个参数:分隔符和分隔符之间的内容是否进行压缩
boost::split(*out, target, boost::is_any_of(sep), boost::token_compress_on);
}
};
测试这个split函数的代码:
#include<iostream>
#include<string>
#include<vector>
#include<boost/algorithm/string.hpp>
int main()
{
std::vector<std::string> result;
std::string target = "aaa\3\3\3bbb\3ccc";
boost::split(result,target,boost::is_any_of("\3"),boost::token_compress_on);
for(auto& s:result)
{
std::cout << s<<std::endl;
}
return 0;
}

token_compress_on:把压缩打开,可以理解为将相连的分隔符压缩成一个
class StringUtil
{
public:
/*************************************
* str: 输入型,目标要切分的字符串
* target: 输出型参数,保存切分完毕的结果
* sep: 指定的分割符
* **********************************/
static void SplitString(const std::string &str, std::vector<std::string> *target, const std::string &sep)
{
boost::split((*target),str,boost::is_any_of(sep), boost::algorithm::token_compress_on);
}
};
5.编译运行模块-compile_server
编译运行模块的功能是:编译并运行客户端通过网络提交的代码,并得到运行的结果
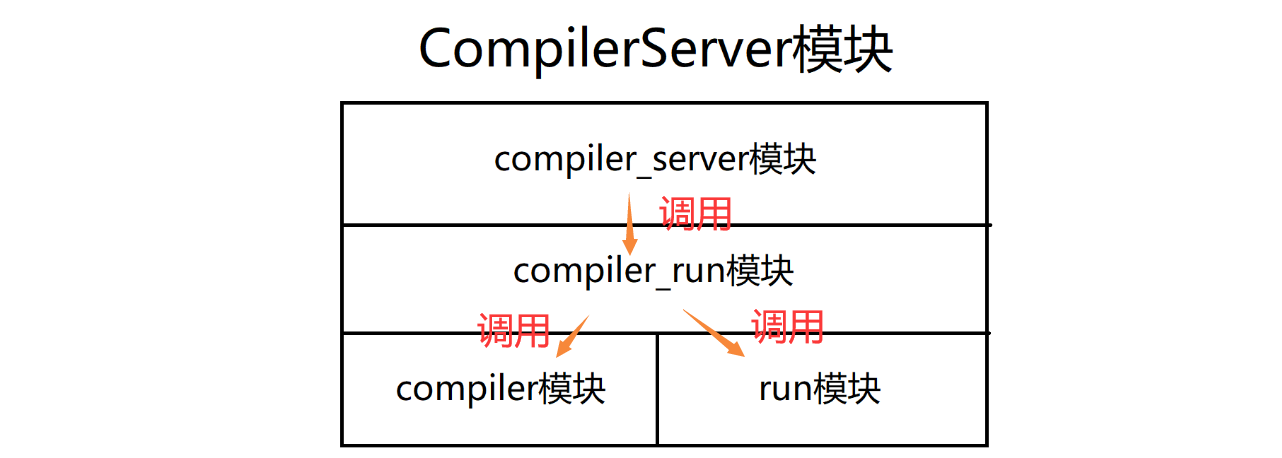
把整个模块分为4个部分:
- compiler模块**:只负责代码的编译,拿到待编译代码的文件名,进行编译,并形成对应的可执行或者错误保存编译时错误信息的临时文件,**
- run模块:只负责运行代码,通过文件名执行指定的可执行程序,并且形成用于保存运行的结果的临时文件方便获得对应的内容,
- compiler_run模块:整合编译模块和运行模块,解析用户发来的json串,得到json串形式的代码内容,形成一个可以用来编译的源文件,调用编译和运行两个模块完成功能,构建结果返回给编译服务模块,
- compiler_server模块:负责搭建http服务,接收客户端发来的请求,提取出json串形式的代码,然后调用compiler_run模块编译运行,得到结构后返回给客户端
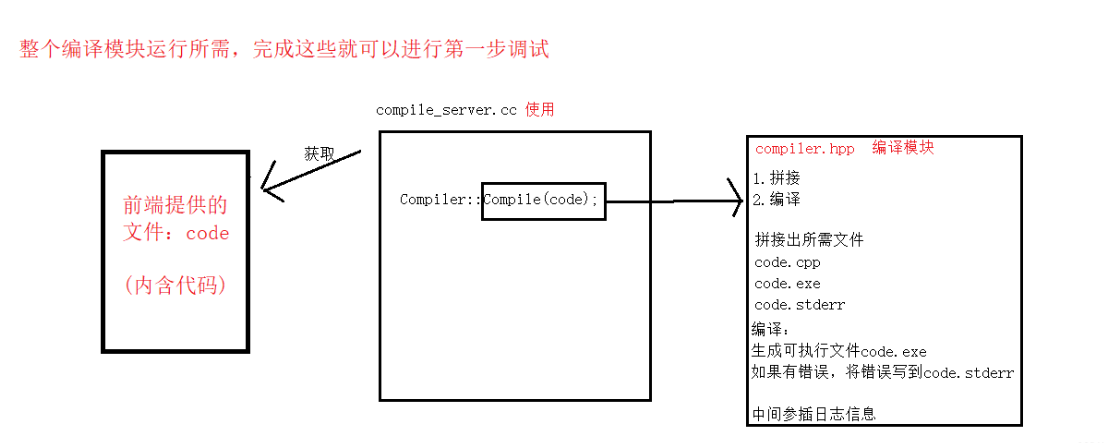
在compiler_server目录下定义一个temp目录,用来存储生成的临时文件,但是实际上并不需要存储,我们编译运行完成之后,就可以清除这些临时文件
编译模块-compiler.hpp
主要功能:提供编译服务 -只负责进行代码的编译
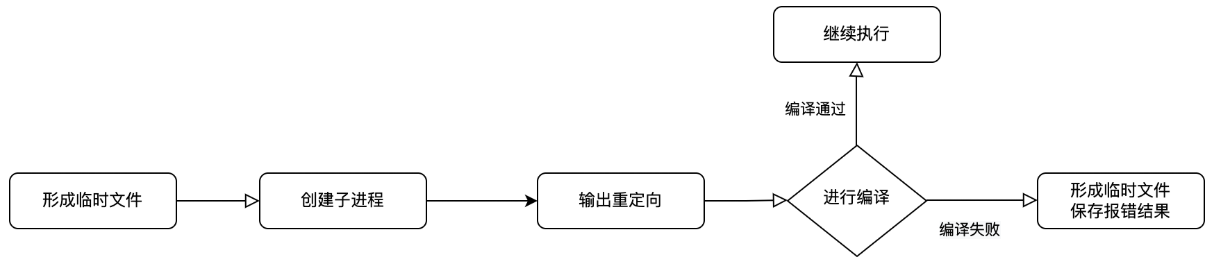
需要实现的函数:static bool Compile(const std::string &file_name)
- 参数:要进行编译的文件的名字,不需要带后缀,在函数内部自动调用路径工具进行拼接
1.我们需要根据文件名字,构建出带路径和后缀的:源文件,可执行文件,标准错误文件
2.我们需要创建子进程来帮我们完成编译工作,而不是让主进程干这个活,
子进程:
-
编译之前,首先需要打开该文件名同名的,后缀为compile_error的临时文件(编译时报错的文件),就是为了编译失败的时候写入它
-
因为该文件可能不存在,所以如果不存在就创建它,因为需要设置文件的权限,权限还受权限掩码的影响,所以我们先把权限掩码清0
-
我们调用
dup函数,把标准错误重定向到我们打开的文件当中,后序如果编译报错,该文件就会有错误信息-
#include <unistd.h> int dup2(int oldfd,int newfd); -
让newfd指向的内容变成oldfd指向内容的一份拷贝,也就是说让newfd指向之前oldfd指向的文件
-
例如:想要把2号文件描述符重定向到_stderr文件, :dup(_stderr,2)
-
-
子进程需要做的:调用g++编译器,完成对代码的编译工作 ->需要使用程序替换
-
#include <unistd.h> int execlp(const char* file,const char* arg, ...); -
第一个参数是要进行替换的程序的名字,因为我们是要编译代码,所以这个程序名就是g++,后面的参数是一个可变参数,我们在命令行怎么执行改程序,就怎么把参数传给这个替换函数,这就需要用到上面封装的路径工具类了,每个参数都是字符串类型,最后还有一个nullptr
-
明确一下:程序替换,并不影响进程的文件描述符表
-
g++ -o 目标文件 源文件 -std=c++11 ,注意程序替换的参数不要忘记以nullptr作为结尾
-
注意:
1.这里的编译选项还有一点需要注意,在编译模块只需要可以编译代码就可以了,但是我们整个代码的设计是分为两部分的,一部分预设代码,即在用户请求编译时已经存在的一部分代码,然后提交给后端
2.后端通过用户提交的代码和题目对应的测试用例拼接起来,才形成一个完整的代码,而为了在测试用例一般会加入条件编译,具体原因我会在题库设计时讲解,所有编译时还要多加一个选项才能让代码正常编译
父进程:
1.等待子进程结束,我们不关心退出结果,因为如果有编译失败,错误信息已经保存在了和该文件同名的,后缀为compile_error的临时文件当中
2.判断是否编译成功 (本质是看有没有形成对应的可执行程序 -> 该文件是否存在)
所以是可以通过:g++ -o 路径/123.exe 路径/123.cpp -std=c++11 来编译cpp文件,在该路径下生成名字为123.exe的可执行程序

namespace ns_compiler
{
using namespace ns_util;//为了引入路径工具类
using namespace ns_log; //引入日志
class Compiler
{
public:
Compiler()
{
}
~Compiler()
{
}
//返回值:编译成功:true,否则:false
//输入参数:编译的文件名,例如:file_name: 1234
//构建源文件 可执行文件 标准错误的文件名
//1234 -> ./temp/1234.cpp ./temp/1234.exe ./temp/1234.stderr
static bool Compile(const std::string &file_name) //参数:文件名
{
pid_t pid = fork();
if(pid < 0) //创建子进程失败
{
LOG(ERROR) << "内部错误,创建子进程失败" << "\n";
return false;
}
else if (pid == 0) //子进程
{
//编译前,先打开后缀为compile_error的临时文件(编译时报错的文件),为了失败的时候写入
umask(0);//将默认的umask清0,
int _stderr = open(PathUtil::CompilerError(file_name).c_str(), O_CREAT | O_WRONLY, 0644);//不存在就创建这个文件,文件权限为rw-r--r--
if(_stderr < 0) //判断是否打开文件成功
{
LOG(WARNING) << "没有成功形成stderr文件" << "\n";
exit(1);//打开文件失败->说明一旦编译报错,也不能给用户提供报错信息
}
dup2(_stderr, 2); //将标准错误重定向到文件_stderr
//g++ -o ./temp/1234.exe ./temp/1234.cpp -std=c++11
execlp(
"g++", //第一个参数:要执行的命令
//后续的就像在命名行上的参数一样
"g++",
"-o",
PathUtil::Exe(file_name).c_str(),
PathUtil::Src(file_name).c_str(),
"-std=c++11",
nullptr //最后不要忘了nullptr
);
LOG(ERROR) << "启动编译器g++失败,可能是参数错误" << "\n";
exit(2);//如果走到这里,说明程序替换失败,退出码设为2
}
else //父进程
{
waitpid(pid, nullptr, 0); //等待id为pid子进程结束,不关心退出结果设为nullptr
//判断编译是否成功-> 就看有没有形成对应的可执行程序
if(FileUtil::IsFileExists(PathUtil::Exe(file_name)))
{
LOG(INFO) << PathUtil::Src(file_name) << " 编译成功!" << "\n";
return true;
}
}
LOG(ERROR) << "编译失败,没有形成可执行程序" << "\n";
return false;
}
};
}
测试编译模块
首先我们先在temp目录下添加一个名字为code的.cpp文件,并且编写测试代码
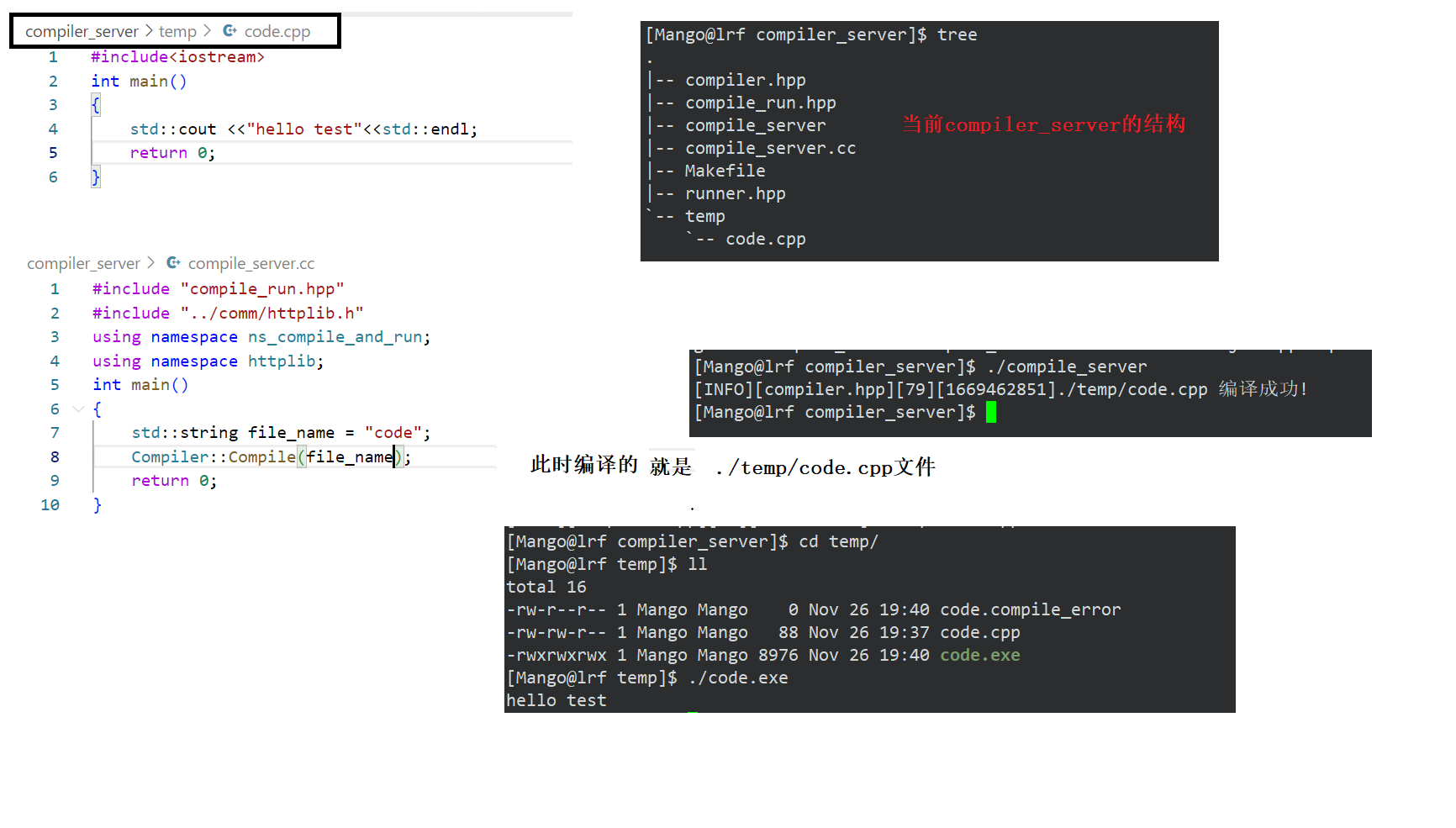
在temp目录下生成对应的文件:源文件,可执行文件,编译时出错文件
运行模块-runner.hpp
我们通常在OJ刷题平台上看的,大部分题目都是限制时间复杂度和空间复杂度的,运行的时候, 有可能用户提供的是恶意的代码,例如:死循环消耗CPU资源,,所以运行的时候,我们要进行时间和空间的约束,以及能根据返回的信号,映射到对应的错误原因,供上层去使用
所以这里我们也需要写一个函数,限制程序的资源的占用大小,如CPU时间,占用空间大小等
setrlimit函数
这是一个系统调用函数,作用是设置资源使用限制
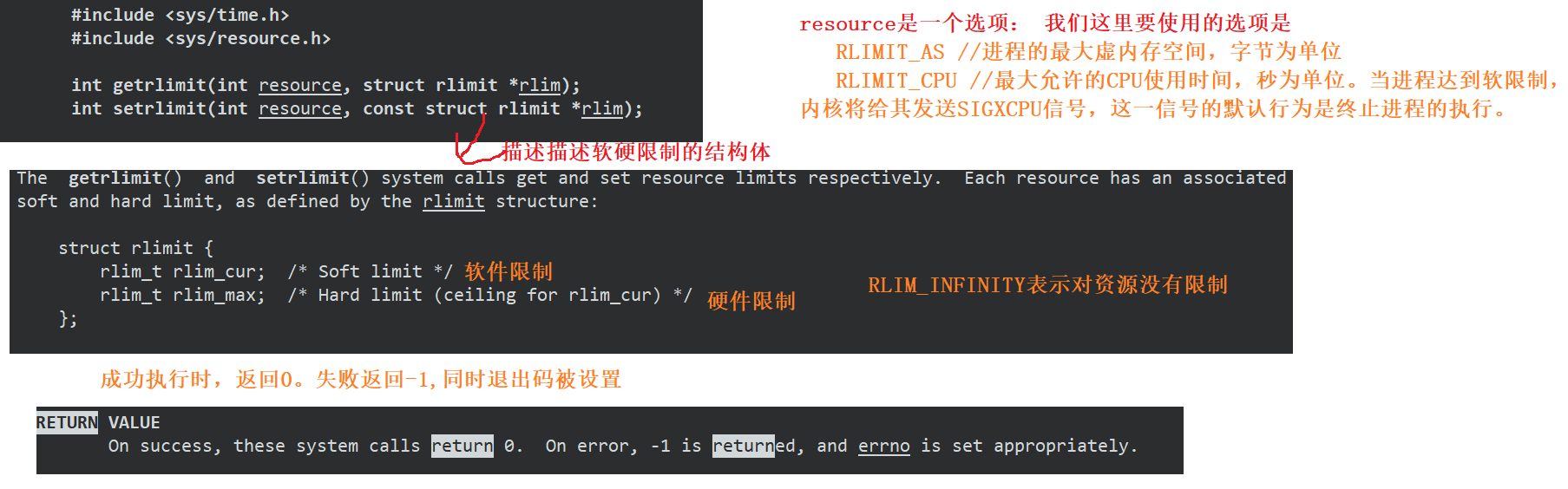
软限制设置的值不能超过硬限制,一般把硬限制设置成RLIM_INFINITY表示无限制,软限制设置成限制的值
测试代码:
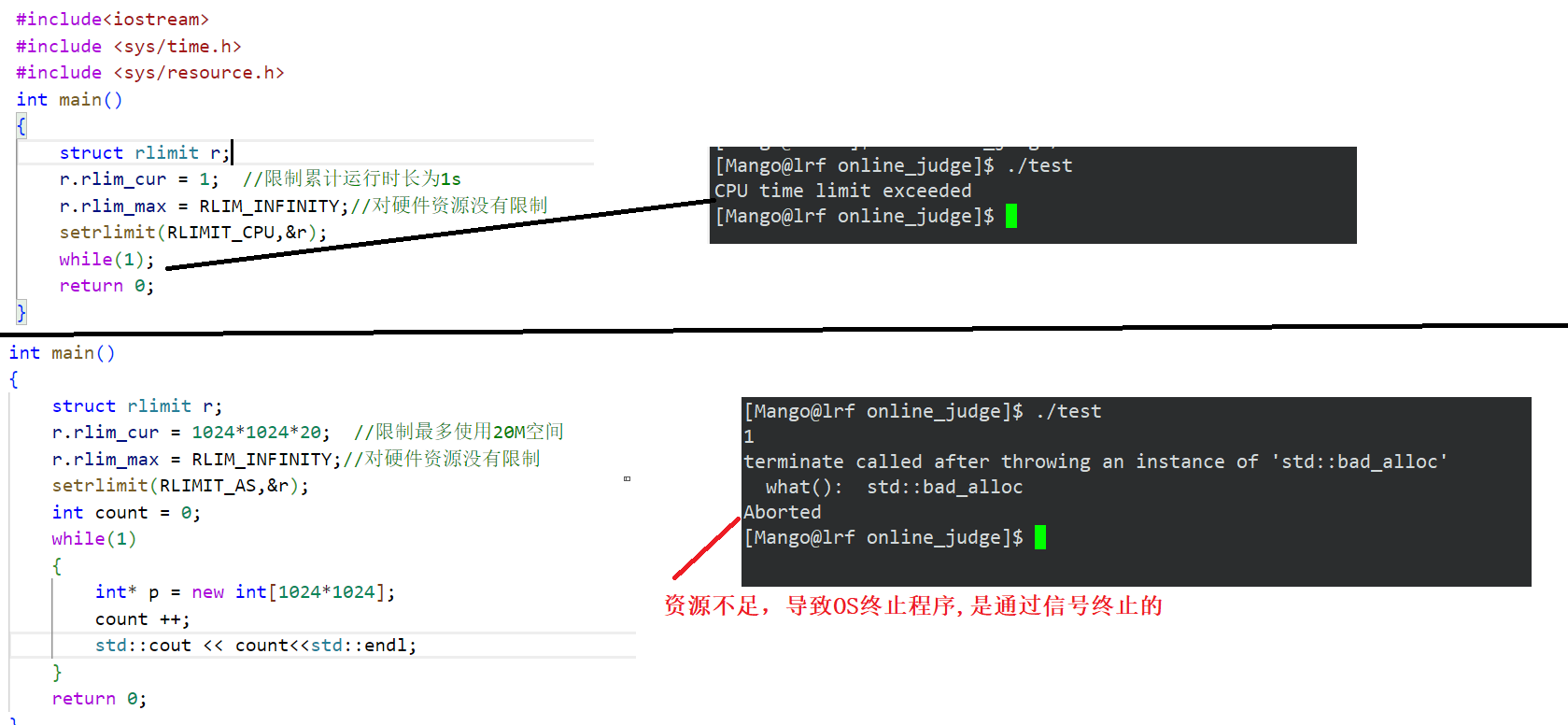
如果超时: OS发送的是24号信号SIGXCPU 如果是资源不足:OS发送的是6号信号SIGABRT
Run函数设计
程序运行结果有3种可能:
1.代码跑完,结果正确 2.代码跑完,结果不正确 3.代码没跑完,异常退出了
在这里,我们不需要关心代码运行的结果是否正确,结果正确与否:这个要交给上层的OJ模块根据测试用例去判断!在这里我们只考虑:程序是否正确运行完毕
其次我们要控制程序的输入输出,
- 标准输入:不作处理 ->即:不考虑用户自己写测试用例的情况,必须由我们来做
- 标准输出:一般是程序运行的结果
- 标准错误:运行时错误信息 (注意:有两种错误:编译时错误和运行时错误,运行时错误才是往stderr打印)
我们执行这个程序,想要的有两个东西:
1.程序执行完的临时数据,尤其是标准输出和标准错误, 写到文件当中,方便查看,
2.程序运行结果是什么已经在标准输出文件中保存了,我们不关心, 我们只关心文件有没有异常,如果异常,结果没必要看了.
如何得知进程有没有异常? 程序运行异常,一定是因为因为收到了信号!
static int Run(const std::string &file_name, int cpu_limit, int mem_limit)
参数:
第一个参数:file_name 指明文件名即可,不需要带路径,不需要带后缀
第二个参数:cpu_limit: 该程序运行的时候,可以使用的最大cpu资源上限
第三个参数:mem_limit: 该程序运行的时候,可以使用的最大的内存大小(以KB为单位) 如果按字节为单位,数字太大
返回值:
关于返回值的设定: 我们这里的返回值是关心运行是否成功
- 返回值>0: 程序异常了,退出时收到了信号,返回值就是对应的信号编号
- 返回值==0:正常运行完毕的,运行接轨保存到了对应的临时文件中(后缀为.stdout)
- 返回值<0:发生了内部错误
1)先根据文件名,使用路径工具类的函数,获取对应的带路径的临时同名文件,包括:可执行程序文件,标准输入文件(因为要往这个文件读取,但是实际我们不处理),标准输出文件(程序运行的结果往这个文件写),标准错误文件(运行的时候出错了就把错误信息写入到该文件)
2)打开上述的三个标准文件,如果不存在就先创建 (因为需要指定权限,所以先把权限掩码清为0)
3)创建子进程执行运行任务,子进程也会形成自己的file_strcut结构体,子进程内核的数据结构task_strcut会以父进程为模板初始化自身,因此父进程和子进程的文件描述符表就是一样的,也就是说子进程会继承父进程的文件描述符表
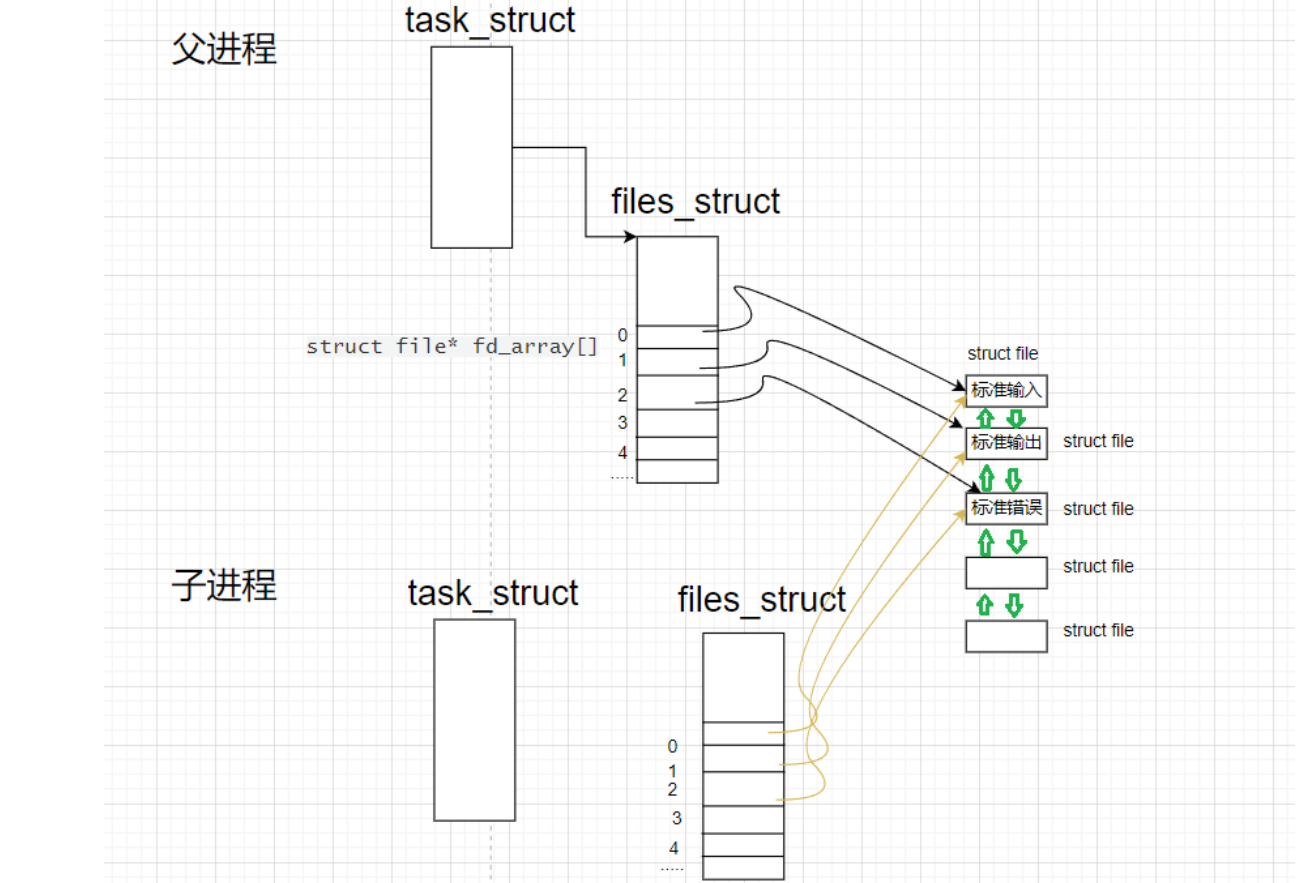
- 如果子进程创建失败:此时就要关闭主进程的文件描述符的内容,然后让主进程退出
子进程:
1.子进程的标准输入,标准输出,标准错误, 默认是键盘显示器显示器,所以我们需要把它们重定向到我们打开的文件,将来程序运行后,运行结果/错误信息都会写入到该文件,注意:并不会影响父进程 此处需要使用dup函数
2.设置子进程的资源限制,添加资源约束是为了让子进程受到资源可控的运行上下文当中
3.执行进程替换,运行程序,需要注意:我们是可以带路径运行程序的,例如: /bin/ls来运行ls指令
父进程:
1.因为父进程不需要使用上述打开的三个标准文件,所以我们要关闭其对应的文件描述符,不会影响子进程,因为进程具有独立性
2.等待子进程退出,这里我们只关心退出时结果是否是异常的,如果程序运行异常,一定是因为因为收到了信号!我们可以在oj模块,根据Run函数的返回值,来判断是因为什么原因出错的
code:
class Runner
{
public:
Runner() {
}
~Runner() {
}
public:
//提供设置进程占用资源大小的接口
static void SetProcLimit(int _cpu_limit, int _mem_limit)
{
// 限制(设置)CPU时长
struct rlimit cpu_rlimit;
cpu_rlimit.rlim_max = RLIM_INFINITY;
cpu_rlimit.rlim_cur = _cpu_limit;
setrlimit(RLIMIT_CPU, &cpu_rlimit);
// 限制(设置)内存大小
struct rlimit mem_rlimit;
mem_rlimit.rlim_max = RLIM_INFINITY;//对硬件资源没有限制
mem_rlimit.rlim_cur = _mem_limit * 1024; //默认限制的单位是字节,转化成为KB
setrlimit(RLIMIT_AS, &mem_rlimit);
}
/*******************************************
* 返回值:关心运行是否成功
* 返回值 > 0: 程序异常了,退出时收到了信号,返回值就是对应的信号编号
* 返回值 == 0: 正常运行完毕的,结果保存到了对应的临时文件中
* 返回值 < 0: 内部错误
*
参数:
* file_name 指明文件名即可,不需要带路径,不需要带后缀
* cpu_limit: 该程序运行的时候,可以使用的最大cpu资源上限
* mem_limit: 该程序运行的时候,可以使用的最大的内存大小(KB) 按字节来看,数字太大了,不好看
* ****************************************
*/
static int Run(const std::string &file_name, int cpu_limit, int mem_limit)
{
/*
********************************************
* 程序运行结果:
* 1. 代码跑完,结果正确
* 2. 代码跑完,结果不正确
* 3. 代码没跑完,异常了
* Run需要考虑代码跑完,结果正确与否吗? 不考虑!
* 结果正确与否:是由我们的测试用例决定的!在这里我们只考虑:程序是否正确运行完毕
* 一个程序在默认启动的时候
* 标准输入: 不处理 -> 即:不考虑用户自己写测试用例的情况,必须由我们来做
* 标准输出: 程序运行完成,输出结果是什么
* 标准错误: 运行时的错误信息
* ******************************************
*/
//根据文件名称 获取 对应的带路径的临时同名文件 ./temp/file_name.exe
std::string _execute = PathUtil::Exe(file_name); //带路径的可执行程序文件
std::string _stdin = PathUtil::Stdin(file_name);//标准输入的东西往这个文件读取
std::string _stdout  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1286
1286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











