






mysql 约束
| 约束名称 | 作用 |
| PRIMARY KEY | 主键约束--用于唯一标识 |
| FOREIGN KEY | 外键约束--用于与其他表关联 |
| NOT NULL | 非空约束--用于限制字段不为空 |
| UNIQUE | 唯一性约束--用于限制字段不重复 |
| DEFAULT | 默认约束--用于在没有赋值的情况下的默认值 |
| AUTO_INCREMENT | 自增约束--每一列固定增加步长标识 |
1、PRIMARY KEY 主键约束:
该字段不能为空、并且不能重复
//单个主键设置方法
create table student
(
//设置id为主键
id int primary key,
name varchar(20)
)engine=myisam;
//联合主键
create table student
(
id int(10),
name varchar(20),
bath datetime,
//设置id 和name 为联合主键
primary key(id,name)
)engine=myisam;
2、FOREIGN KEY 外键约束:
如何找关系
分析步骤:
#1、先站在左表的角度去找
是否左表的多条记录可以对应右表的一条记录,如果是,则证明左表的一个字段foreign key 右表一个字段(通常是id)
#2、再站在右表的角度去找
是否右表的多条记录可以对应左表的一条记录,如果是,则证明右表的一个字段foreign key 左表一个字段(通常是id)
#3、总结:
#多对一:
如果只有步骤1成立,则是左表多对一右表
如果只有步骤2成立,则是右表多对一左表
#多对多
如果步骤1和2同时成立,则证明这两张表时一个双向的多对一,即多对多,需要定义一个这两张表的关系表来专门存放二者的关系
#一对一:
如果1和2都不成立,而是左表的一条记录唯一对应右表的一条记录,反之亦然。这种情况很简单,就是在左表foreign key右表的基础上,将左表的外键字段设置成unique即可当然这只是我找到的好一点的思路,因为外键约束,已经在编程语言应用层管理了,数据库层面不做仔细研究。
3、NOT NULL 非空约束:
限制字段不可以为空
create table student
(
//设置id 不为空
id int(10) NOT NULl
)engine=mysiam;
4、UNIQUE 唯一性约束:
限制该字段不能有重复值
create table student
(
//创建id 字段限制该字段不能重复
id int NOT NUll
)engine=mysiam;5、DEFAULT 默认性约束:
create table student
(
//创建id 字段限制该字段不能重复
id int DEFAULT ''
)engine=mysiam;
6、 AUTO_INCREMENT 默认性约束:
create table student
(
//创建id 字段限制该字段不能重复
id int auto increment
)engine=mysiam;mysql 索引
索引的作用:索引的目的在于提高查询效率,与我们查阅图书所用的目录是一个道理:先定位到章,然后定位到该章下的一个小节,然后找到页数。相似的例子还有:查字典,查火车车次,飞机航班等。
先创建我们需要测试的表
create table student
(
id int auto_increment unique not null,
name varchar(50) default '',
age int(4) default 0
);
//插入数据
insert into student (name,age) values ('张三',20),('李四',22),('王五',18),('狗蛋',23);建立单字段索引
//创建name字段索引
create index index_name on student(name);分析利用索引检索数据
explain select * from student where name='张三';
创建复合索引
//删除旧的索引,如果不删除将会对索引结果有影响
drop index index_name on student;
create index index_name_age on student(name,age); 分析使用复合索引 
使索引失效的几种情况
单索引:
- 对检索字段进行操作(数据库只存在index_age 索引和主键id 索引):

- 使用 in 字段 (数据库只存在index_age 索引和主键id 索引):

3. like 前导模糊查询 (数据库只存在index_name 索引和主键id 索引) :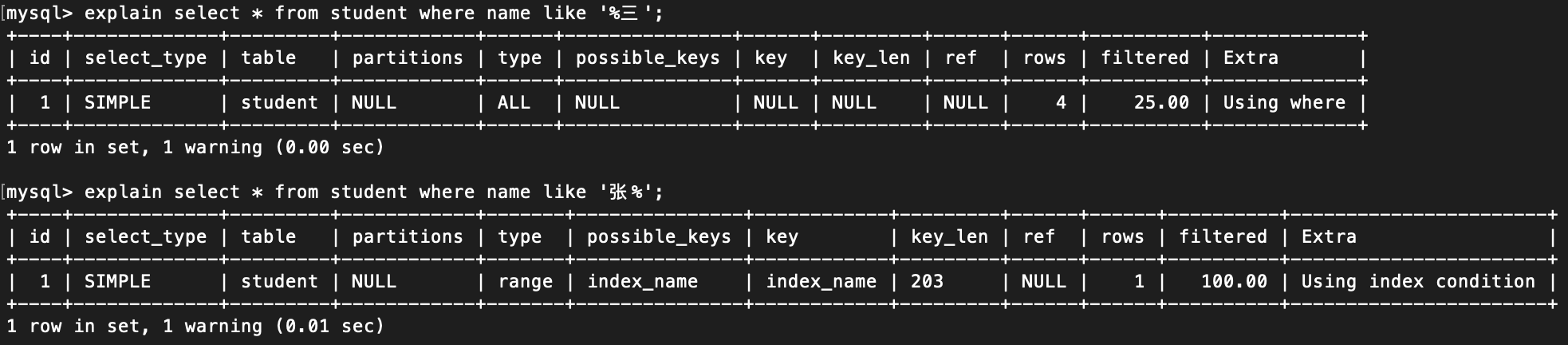
4. 查询条件中 存在 or 的情况 (数据库只存在index_name 索引和主键id 索引) :
5.发生类型转换不使用索引 (数据库只存在index_name 索引和主键id 索引):
6.如果mysql估计使用全表扫描要比使用索引快,则不使用索引:
此情况 只在索引过于庞大,并且表足够小的情况下发生,不做举例,情况比较稀少;
复合索引:
1. 经过测试 in、类型转换 等等 在复合索引中 会保留一个index 全表扫描,非ALL。
2. 跨列索引 跨列索引字段以及后续字段索引失效、或者导致索引降级。一般会使得根据索引表结果检索剩余where 条件 extra 表现为 using index condition (数据库只存在index_id_name_age 索引和主键id 索引) :
下面例子中 跨过name 索引 直接使用age 导致索引降级 index

如果我们索引 name 而不使用 age ,由于name为索引头字段,所以mysql 会直接使用索引 ,不会像上例中 做部分索引全表扫描;

当然,如果 我们按照索引的次序 分别索引 name='张三' and age=22 也是有效的

如果我们次序颠倒 也是有效的 ,因为mysql 内置了 语句优化器 ,会帮你优化sql 语句

ps:顺带提一下mysql 语句的解析顺序以及语句优化的规则
(1)from
(3) join
(2) on
(4) where
(5)group by(开始使用select中的别名,后面的语句中都可以使用)
(6) avg,sum....
(7)having
(8) select
(9) distinct
(10) order by
优化规则 单语句内优化 例如:
目前有 index_name_age 如果 你写成age ='xxx' and name='xxx' 系统自动帮你调整顺序, 但是如果 age ='xxx' group by (name) 这种跨语句的则系统会自动使用 index 全表扫描;

但是跨语句 但是顺序 是对的 则 :

在索引级别上 直接从 index -> ref 效率提升 明显;但是我们最常用的还是 按等于号检索;
特殊的索引
primary key 和 unique 这两个字段在创建表的同时 会创建各自的索引;所有涉及到查询这两个字段的内容时。系统会优先查询这两个索引。如果未有结果 会继续检索剩下的索引 。优先级 高于其他索引。
总结:
primary key 和 unique 两个索引 ,如果sql语句中包含对两个字段的检索 ,mysql 会优先筛选这两个字段的内容。 索引级别为 const 所以可以优先使用该索引。其次 我们编程软件设计输入字段时 确定必填项 和选填项。必填项 必须组成复合索引优先设立索引 ,次序问题mysql 会协助sql 语句优化。选填项目可根据使用频率 合并进 复合索引。 在检索阶段至少保证 检索最低级别 为range 。 注意:不能发生类型转换。会使得转换字段以及后续字段索引失效。失效字段mysql 会使用 using index condition 回表 。 检索范围 可使用 between ... and ... 不建议使用 in 字段。 连表查询 规则 为小表 join 大表 ,一般程序规则为 小表驱动大表。包括编程语言。双层嵌套循环 。外层循环次数建议少于内层。















 566
566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









