






1. 浏览器接收URL,包括:协议方案名、服务器地址(服务器端口号)、带层次的文件路径、查询字符串?、片段标识符等;
2. 将URL与缓存进行比对如果请求的页面在缓存中且未过期,则直接进行第8步;
3. 负责域名解析DNS服务,系统进行DNS查找,并将IP地址返回给浏览器;
4. 浏览器与服务器建立TCP连接(在传输层):https3次握手(详情见图1);
5. 浏览器通过TCP协议向服务器发送HTTP请求;
6. 服务器接收到请求,从文档空间中查找资源返回HTTP响应(Response);
7. 浏览器接收HTTP响应,根据Header头里的状态码,做出不同的处理方式;
状态码详解参考:(http://tool.oschina.net/commons?type=5)
8. 如果是可以缓存的,这个响应则会被存储起来。根据首部字段判断是否进行缓存。例如,Cache-Control, no-cache(每次使用缓存前和服务器确认),no-store 绝对禁止缓存。
9. 浏览器解码响应,浏览器拿到index.html文件后,就开始解析其中的html代码,遇js/css/image等静态资源时,就向服务器端去请求下载;解析成对应的树形数据结构DOM树、CSS规则树,Javascript脚本通过DOM API和CSSOM API来操作DOM树、CSS规则树。
10. 渲染页面
11. 关闭TCP连接或继续保持连接,四次握手
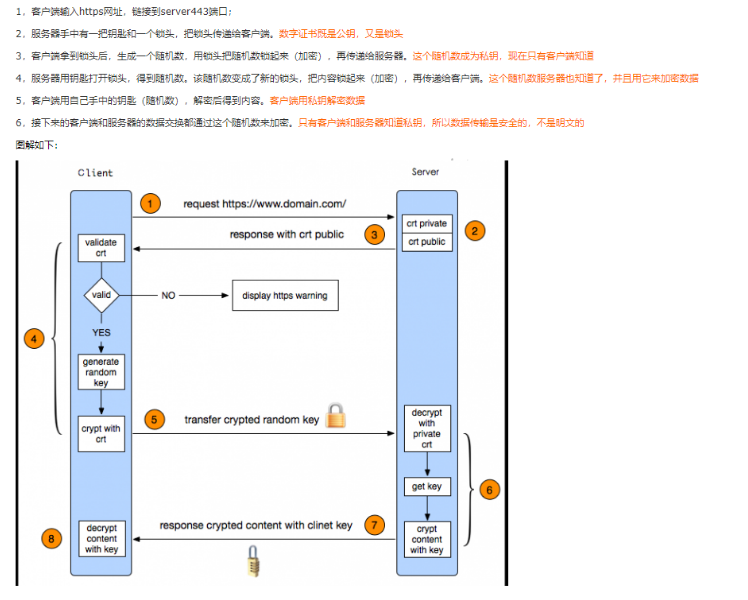
图1 https三次握手
页面渲染的过程
页面渲染过程总的来说是,浏览器拿到html文档,自上而下构建dom树,再根据dom树构建渲染树(和dom树有区别,浏览器解析html文档和解析css样式形成dom树和cssdom树,结合这两种才会构建渲染树)。这里有一种情况,如果在head中写入link某个css文件,而后插入script标签,引入一个巨大的js文件,由于浏览器下载css文件需耗时间,这个时候浏览器还在自上而下地去解析dom树,但是遇到script标签,并且由于样式表没有下载下来,阻塞了构建渲染树。一旦css文件加载完成,会结合刚在的dom树构建渲染树,显示到页面,接续加载js文件。但是恰巧js文件巨大,阻塞了浏览器向下解析,等待这个巨大的js文件下载完成后才继续向下解析。如此反复, 最后将渲染树渲染到页面。















 115
115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









