






1.HBase产生的需求背景——适用于解决的问题
.HDFS只能执行批量处理,并且只以顺序方式访问数据。这意味着即使是最简单的搜索工作也必须搜索整个数据集。这就导致了无法进行快速查询。
.HBase是Key-Value类型的数据库,通过其行键使用Hash和辅助索引,可以实现快速随机访问数据。
2.表结构和表结构设计过程中的要点
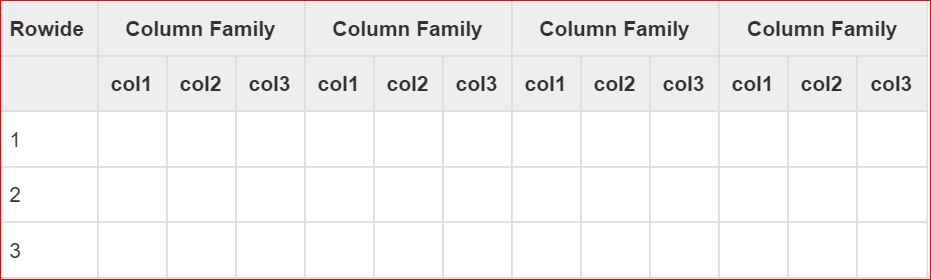
2.1表结构
.最基本的单位是列(Column)
.一列或多列形成一行(ROW)并由唯一的行键(Rowkey)来确定存储。
.一个表(Table)有若干行,其中每列可能有多个版本(时间戳),在每一个单元格(Cell)中存储了不同的值。
2.2表结构设计过程中的要点
1.Rowkey也是一段二进制码流,最大长度为64KB,建议是越短越好,不要超过16个字节,8字节的整数倍利用操作系统的最佳特性。
原因:持久化的存储效率、MemStroe缓存的检索效率、操作系统一般为64位,内存8字节对齐。
2.Rowkey必须在设计上保证其唯一性。
原因:作为键值对的key进行存储、查询。
3.Rowkey散列,通过预分区避免热点实现RegionServer负载均衡
原因:存储的顺序是对Rowkey按字典排序,假如使用时间戳放在二进制码的前面,将产生所有新数据都在一个RegionServer上堆积的热点现象,这样在做数据检索的
时候负载将会集中在个别RegionServer,降低查询效率。
4.针对查询需求进行设计:
4.1非结构化:行键作为一级索引
简单例子如:随机查询条件——随机查询条件
例如分组筛选条件即一些可以确保唯一性的id
例如FileHash生成的UUID,即成为根据分组筛选条件快速查询全部满足条件的行的结构。
4.2结构化:利用协处理器插入数据时设置多级索引空间换时间
简单例子如:
http://www.infoq.com/cn/articles/hbase-second-index-engine/

3HBase架构、原理和实际使用中的优化
3.1架构
http://www.yiibai.com/hbase/hbase_architecture.html
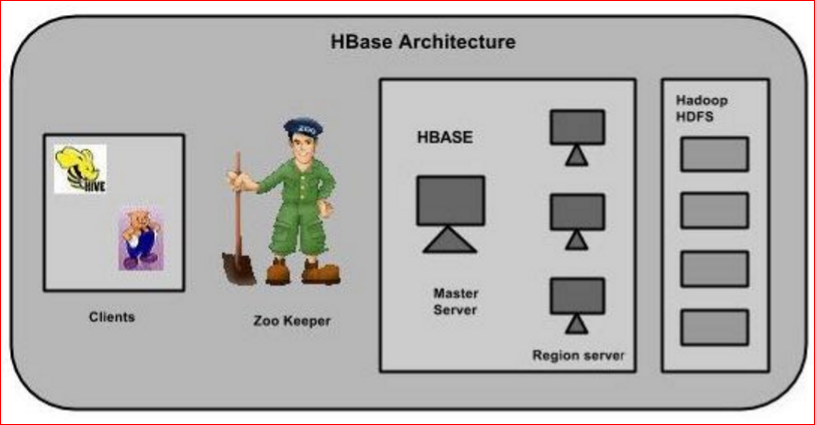
在HBase中,表被分割成区域,并由区域服务器提供服务。区域被列族垂直分为“Stores”。Stores被保存在HDFS文件。
HBase有三个主要组成部分:客户端库,主服务器和区域服务器。区域服务器可以按要求添加或删除。
主服务器
主服务器是 -
- 分配区域给区域服务器并在Apache ZooKeeper的帮助下完成这个任务。
- 处理跨区域的服务器区域的负载均衡。它卸载繁忙的服务器和转移区域较少占用的服务器。
- 通过判定负载均衡以维护集群的状态。
- 负责模式变化和其他元数据操作,如创建表和列。
区域
区域只不过是表被拆分,并分布在区域服务器。
区域服务器
区域服务器拥有区域如下 -
- 与客户端进行通信并处理数据相关的操作。
- 句柄读写的所有地区的请求。
- 由以下的区域大小的阈值决定的区域的大小。
需要深入探讨区域服务器:包含区域和存储,如下图所示:

存储包含内存存储和HFiles。memstore就像一个高速缓存。在这里开始进入了HBase存储。数据被传送并保存在Hfiles作为块并且memstore刷新。
Zookeeper
- Zookeeper管理是一个开源项目,提供服务,如维护配置信息,命名,提供分布式同步等
- Zookeeper代表不同区域的服务器短暂节点。主服务器使用这些节点来发现可用的服务器。
- 除了可用性,该节点也用于追踪服务器故障或网络分区。
- 客户端通过与zookeeper区域服务器进行通信。
- 在模拟和独立模式,HBase由zookeeper来管理。
3.2主要流程原理
http://lxw1234.com/archives/2016/09/719.htm
1.regionserver 定位
- 首先,Client通过访问ZK来请求目标数据的地址。
- ZK中保存了-ROOT-表的地址,所以ZK通过访问-ROOT-表来请求数据地址。
- 同样,-ROOT-表中保存的是.META.的信息,通过访问.META.表来获取具体的RS。
- .META.表查询到具体RS信息后返回具体RS地址给Client。
- Client端获取到目标地址后,然后直接向该地址发送数据请求。
2.split
- region先更改ZK中该region的状态为SPLITING。
- Master检测到region状态改变。
- region会在存储目录下新建.split文件夹用于保存split后的daughter region信息。
- Parent region关闭数据写入并触发flush操作,保证所有写入Parent region的数据都能持久化。
- 在.split文件夹下新建两个region,称之为daughter A、daughter B。
- Daughter A、Daughter B拷贝到HBase根目录下,形成两个新的region。
- Parent region通知修改.META.表后下线,不再提供服务。
- Daughter A、Daughter B上线,开始向外提供服务。
- 如果开启了balance_switch服务,split后的region将会被重新分布。
3.根据这个架构和原理,实际使用的经验
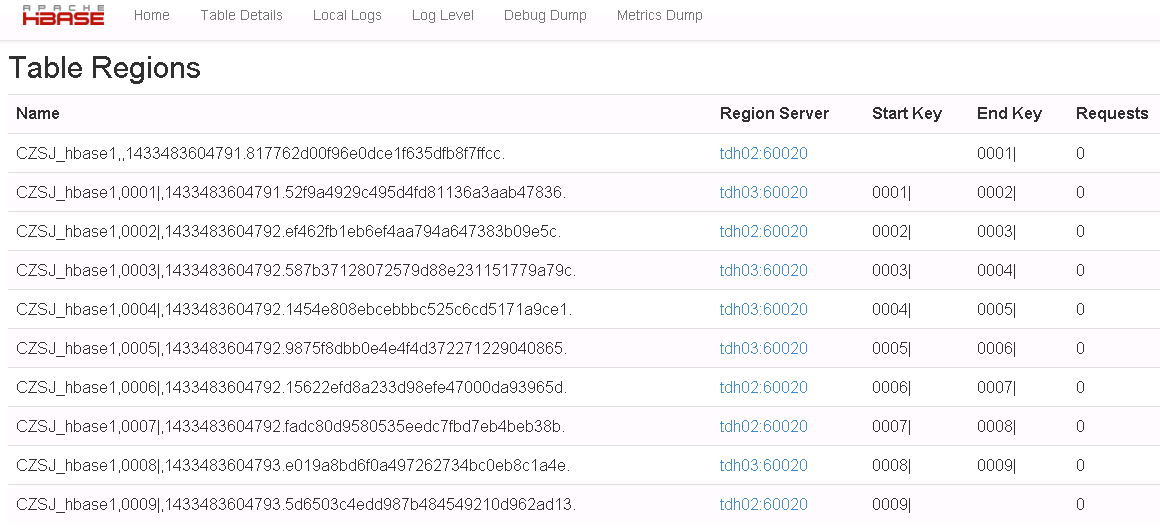
1.由于数据量激增之后有——个HBase自动维护的split的过程,这个过程中的RegionServer性能消耗很大。所以在建表时应该对数据进行预分区,具体实现如下:
private byte[][] getSplitKeys() {
String[] keys = new String[] { "10|", "20|", "30|", "40|", "50|",
"60|", "70|", "80|", "90|" };
byte[][] splitKeys = new byte[keys.length][];
TreeSet<byte[]> rows = new TreeSet<byte[]>(Bytes.BYTES_COMPARATOR);//升序排序
for (int i = 0; i < keys.length; i++) {
rows.add(Bytes.toBytes(keys[i]));
}
Iterator<byte[]> rowKeyIter = rows.iterator();
int i=0;
while (rowKeyIter.hasNext()) {
byte[] tempRow = rowKeyIter.next();
rowKeyIter.remove();
splitKeys[i] = tempRow;
i++;
}
return splitKeys;
}
在admin.create的时候传入预分region。
效果:















 2019
2019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









