







写在前面
大家好,我是三雒,今天这一篇我们来讨论一下GC抑制。大家都知道C/C++内存的申请和释放需要程序员手动管理,程序员需要付出精力去释放不用的内存,而作为人无论再牛逼细心总会有出错的时候。Java引入GC来实现内存的自动释放,但是天下没有免费的午餐,相应的代价是牺牲应用运行性能。 Android上虚拟机一代目Dalvik 在进行GC时候会“stop the world" 造成应用的严重卡顿,而二代目ART上对GC进行了更多优化,把GC任务拆分成更精细的阶段,只有某些阶段才会影响其他线程,以尽可能减少对其他线程的影响,但即使如此,GC依然会影响到用户体验。GC作为虚拟机的一部分,它采用预估的方式来计算触发的阈值,但这种冷冰冰的策略并不会考虑用户在干什么,因此就还存在一定的优化空间,这也就是我们做GC抑制的基础。
GC导致主线程卡顿
在做流畅度优化和启动优化的过程中,经常会看到如下的Trace,主线程和其他线程产生锁竞争进而被block产生耗时。

进一步查看和主线程竞争锁的线程16634对应的是HeapTaskDaemon线程,也就是执行后台并发GC的线程,我们从下图的Trace也可以看到正在执行并发拷贝GC。虽然是后台GC,但由于某些阶段还是需要暂停一些线程,因此还是会对主线程产生影响。

这个问题线下经常能遇到,我们决定优化一下,思路大致就是在一些用户操作的关键场景,比如启动、滑动等情况下停止GC任务执行,从而规避GC对给用户带来的卡顿耗时,也就是我们常说的GC抑制。
既然要做GC抑制,那么需要对ART虚拟机的GC有一定的了解才可以入手,GC相关的内容大致包括垃圾收集算法(标记清除、标记压缩、拷贝)、GC类型、触发的原因和时机这些,为了实现GC抑制,并不需要对GC算法内部实现有过多了解,我们只需要了解下触发的原因和时机。
GC触发的原因
在ART虚拟机代码中GcCause 定义了触发GC的原因,种类非常之多,但常见的也就下面四种:
-
kGcCauseForAlloc ****Alloc GC或者 Blocking GC , 是指线程分配对象失败触发GC, 一般是因为堆内存触顶导致的,这时候GC会直接在分配对象线程直接执行
-
kGcCauseBackground Background GC是虚拟机为了保证较低的内存使用水位,分配对象时候能有足够的内存而主动触发的GC,这种类型在后台线程(HeapTaskDaemon) 执行。但并不是说只有kGcCauseBackground在后台线程执行,其他的很多原因也会在后台触发GC,比如kGcCauseForNativeAlloc
-
kGcCauseForNativeAlloc 当应用求分配大量Native内存时,如果检测到内存不足可能会触发这个类型的GC,用来释放一些被Java对象引用的Native对象
-
kGcCauseExplicit 代码中直接调用System.gc()显式执行的,取决于我们自己的应用代码
文章开头Trace中的问题是由于我们被并发GC阻塞,所以我们着重去看下kGcCauseBackground ****这种Cause怎么触发的,同时也分析一下kGcCauseForAlloc这种类型。
GC触发时机
在代码中搜索kGcCauseBackground引用的地方主要有两处,第一处是在TriggerPostForkCCGcTask 中,这个Task和Android 10在启动时候抑制GC的方案有关,我们后续再讨论,这里主要看第二处。
class Heap::TriggerPostForkCCGcTask : public HeapTask {
public:
explicit TriggerPostForkCCGcTask(uint64_t target_time, uint32_t initial_gc_num) :
HeapTask(target_time), initial_gc_num_(initial_gc_num) {}
void Run(Thread* self) override {
gc::Heap* heap = Runtime::Current()->GetHeap();
if (heap->GetCurrentGcNum() == initial_gc_num_) {
if (kLogAllGCs) {
LOG(INFO) << "Forcing GC for allocation-inactive process";
}
heap -> RequestConcurrentGC ( self , kGcCauseBackground , false , initial_gc_num_ );
}
}
private:
uint32_t initial_gc_num_;
};第二处在Heap类中的RequestConcurrentGCAndSaveObject 方法中,如下:
https://cs.android.com/android/platform/superproject/main/+/main:art/runtime/gc/heap.cc;bpv=1;bpt=1;l=3937?q=kGcCauseBackground&ss=android%2Fplatform%2Fsuperproject%2Fmain&gsn=RequestConcurrentGCAndSaveObject&gs=KYTHE%3A%2F%2Fkythe%3A%2F%2Fandroid.googlesource.com%2Fplatform%2Fsuperproject%2Fmain%2F%2Fmain%3Flang%3Dc%252B%252B%3Fpath%3Dart%2Fruntime%2Fgc%2Fheap.cc%23jVjkKSzMSsywjyzpn-iwG8k9_3SNfpAuK1cmB7XbSeE
void Heap::RequestConcurrentGCAndSaveObject(Thread* self,
bool force_full,
uint32_t observed_gc_num,
ObjPtr<mirror::Object>* obj) {
StackHandleScope<1> hs(self);
HandleWrapperObjPtr<mirror::Object> wrapper(hs.NewHandleWrapper(obj));
//请求后台并发GC
RequestConcurrentGC ( self , kGcCauseBackground , force_full , observed_gc_num );
}再向上寻找调用RequestConcurrentGCAndSaveObject方法的地方,最终会发现是在AllocObjectWithAllocator方法中调用的。这个方法在Java创建对象时调用,无论是通过new、反射创建、还是编译后的机器码创建最终都会执行到这个方法来分配对象内存,我们接下梳理这个方法来看下对象分配过程中是怎么触发GC的。
https://cs.android.com/android/platform/superproject/+/android-9.0.0_r1:art/runtime/gc/heap-inl.h;l=44
对象分配流程
在AllocObjectWithAllocator方法中,如果从GC触发的视角看主要就分为如下注释中的三步。
inline mirror::Object* Heap::AllocObjectWithAllocator(Thread* self,
ObjPtr<mirror::Class> klass,
size_t byte_count,
AllocatorType allocator,
const PreFenceVisitor& pre_fence_visitor) {
//1. 直接分配对象
obj = TryToAllocate<kInstrumented, false>(self, allocator, byte_count, &bytes_allocated,
&usable_size, &bytes_tl_bulk_allocated);
if (UNLIKELY(obj == nullptr)) {
//2. 分配失败,执行AllocateInternalWithGc, 里面会执行 等上次GC完成后分配、尝试几种不同程度的GC后分配、扩容分配、回收软引用并扩容分配、最终失败抛出OOM等逻辑
obj = AllocateInternalWithGc(self,
allocator,
kInstrumented,
byte_count,
&bytes_allocated,
&usable_size,
&bytes_tl_bulk_allocated,
&klass);
}
//...
if ( IsGcConcurrent()) {
//3. 对象分配完成之后,检查当前所使用内存是否达到并发GC出发阈值,如果达到则触发并发GC
CheckConcurrentGC(self, new_num_bytes_allocated, &obj);
}
}直接分配对象
如果堆内存充足的情况下,直接就会分配完成,但如果判断内存不足以分配的情况,就会返回走AllocateInternalWithGc直接在分配线程GC。
inline mirror::Object* Heap::TryToAllocate(Thread* self,
AllocatorType allocator_type,
size_t alloc_size,
size_t* bytes_allocated,
size_t* usable_size,
size_t* bytes_tl_bulk_allocated) {
//如果会导致OOM返回nullptr, 此时才会走往后走AllocateInternalWithGc
if (
UNLIKELY(IsOutOfMemoryOnAllocation(allocator_type, alloc_size, kGrow))) {
return nullptr;
}
//在对应的Space上分配对象过程
switch (allocator_type) {
// ...
case kAllocatorTypeDlMalloc: {
if (kInstrumented && UNLIKELY(is_running_on_memory_tool_)) {
ret = dlmalloc_space_->Alloc(self, alloc_size, bytes_allocated, usable_size,
bytes_tl_bulk_allocated);
} else {
DCHECK(!is_running_on_memory_tool_);
ret = dlmalloc_space_->AllocNonvirtual(self, alloc_size, bytes_allocated, usable_size,
bytes_tl_bulk_allocated);
}
break;
}
//...
return ret;
}OOM判断
inline bool Heap::IsOutOfMemoryOnAllocation(AllocatorType allocator_type, size_t alloc_size) {
//分配之后预计占用的内存
size_t new_footprint = num_bytes_allocated_.LoadSequentiallyConsistent() + alloc_size;
//如果分配之后预计占用内存大于max_allowed_footprint,max_allowed_footprint是虚拟机给堆内存的一个软限制,表示当前能用的总内存,对应Runtime.totalMemory
if (UNLIKELY(new_footprint > max_allowed_footprint_)) {
//如果超过growth_limit_ 则直接OOM,growth_limit_表示虚拟机能用的最大堆内存,对应于Runtime.maxMemory
if (UNLIKELY(new_footprint > growth_limit_)) {
return true;
}
// 如果处于在max_allowed_footprint_和growth_limit_之间,并且是并发GC模式则认为不会认为OOM,IsGcConcurrent()大部分情况是true;因为max_allowed_footprint_ 只是个软限制,真正分配内存的Space是没有这个限制空间充足,可以先进行分配之后分配完成再出发并发GC进行回收以及扩容
if (!IsGcConcurrent()) {
if (!kGrow) {
return true;
}
max_allowed_footprint_ = new_footprint;
}
}
// 如果分配之后预计占用内存小于max_allowed_footprint,则一定不OOM
return false;
}可以看出当内存触顶达将要到最大堆内存之后才会分配失败,进一步执行AllocateInternalWithGc,触发分配GC,未达到totalMemory是不会执行同步的Blocking GC的 。分配GC 是指在对象分配过程中直接在分配线程本身执行GC,也称Blocking GC,接下来我们了解下Alloc GC的详细细节。
Alloc GC
Heap::AllocateInternalWithGc
https://cs.android.com/android/platform/superproject/+/android-9.0.0_r1:art/runtime/gc/heap.cc;l=1571
mirror::Object* Heap::AllocateInternalWithGc(Thread* self,
AllocatorType allocator,
bool instrumented,
size_t alloc_size,
size_t* bytes_allocated,
size_t* usable_size,
size_t* bytes_tl_bulk_allocated,
mirror::Class** klass) {
...
// 1.等待上一次GC完成之后,尝试重新分配对象
collector::GcType last_gc = WaitForGcToComplete(kGcCauseForAlloc, self);
if (last_gc != collector::kGcTypeNone) {
mirror::Object* ptr = TryToAllocate<true, false>(self, allocator, alloc_size, bytes_allocated,
usable_size, bytes_tl_bulk_allocated);
if (ptr != nullptr) {
return ptr;
}
}
...
// 2.遍历进行几种不同强度的GC 并尝试分配
for (collector::GcType gc_type : gc_plan_) {
if (gc_type == tried_type) {
continue;
}
const bool plan_gc_ran =
CollectGarbageInternal(gc_type, kGcCauseForAlloc, false) != collector::kGcTypeNone;
if (plan_gc_ran) {
mirror::Object* ptr = TryToAllocate<true, false>(self, allocator, alloc_size, bytes_allocated,
usable_size, bytes_tl_bulk_allocated);
if (ptr != nullptr) {
return ptr;
}
}
}
// 3.同步Blokcing GC ,对堆扩容然后尝试分配, TryToAllocate<true, true> 模版参数第二true表示走grow逻辑
mirror::Object* ptr = TryToAllocate<true, true>(self, allocator, alloc_size, bytes_allocated,
usable_size, bytes_tl_bulk_allocated);
if (ptr != nullptr) {
return ptr;
}
//4. 触发回收软引用的GC,第三个参数true表示回收软引用对象,并且对堆扩容进行分配
CollectGarbageInternal(gc_plan_.back(), kGcCauseForAlloc, true);
ptr = TryToAllocate<true, true>(self, allocator, alloc_size, bytes_allocated, usable_size,
bytes_tl_bulk_allocated);
...
if (ptr == nullptr) {
// 5.最终分配失败,抛出OOM异常
ThrowOutOfMemoryError(self, alloc_size, allocator);
}
return ptr;
}
AllocateInternalWithGc 代码主要分上面的五步,这里简单说下2和4。在第2步这里GcType有三种,垃圾回收的强度不同。
-
kGcTypeSticky 仅回收上次GC之后分配的对象。
-
kGcTypePartial 回收整个App Heap的对象。
-
kGcTyepFull 回收整个App Heap 以及Zygote Heap上的对象。
在第4步中,主要是想说下我们在背Java引用的八股文时候就知道软引用在虚拟机内存不足时候回收,那具体到底是什么时候呢,这一刻知识闭环了。
对于GC抑制的目标而言,Alloc GC其实给我们两点启示:
-
Alloc GC是不能进行抑制的,因为他在即将OOM时候触发,没法再抑制了。
-
如果我们抑制后台GC的话,一定有个限度不能太久,在主线程触发Alloc GC反而适得其反。
Background GC
触发GC
在分配完成一个对象之后会检查当前堆上分配的对象大小new_num_bytes_allocated是否超过并发GC阈值,如果超过则执行RequestConcurrentGCAndSaveObject,去提交并发GC任务。
inline void Heap::CheckConcurrentGC(Thread* self,
size_t new_num_bytes_allocated,
mirror::Object** obj) {
//如果当前分配的空间超过concurrent_start_bytes_ ,concurrent_start_bytes_是并发GC的阈值,在上次堆扩容之后动态计算出来的
if (UNLIKELY(new_num_bytes_allocated >= concurrent_start_bytes_)) {
RequestConcurrentGCAndSaveObject(self, false, obj);
}
}RequestConcurrentGCAndSaveObject主要就调用RequestConcurrentGC。
void Heap::RequestConcurrentGCAndSaveObject(Thread* self, bool force_full, mirror::Object** obj) {
StackHandleScope<1> hs(self);
HandleWrapper<mirror::Object> wrapper(hs.NewHandleWrapper(obj));
RequestConcurrentGC(self, force_full);
}RequestConcurrentGC中会先检测下当前有没有正在执行中的GC任务,如果没有的话会往task_processor_添加ConcurrentGCTask, task_processor_负责管理GC相关的任务队列。另外这里检查有没有pending GC任务的逻辑很关键,我们下文会用到。
void Heap::RequestConcurrentGC(Thread* self, bool force_full) {
//如果没有正常执行的并发gc任务,将concurrent_gc_pending_ 由false置成true
if (CanAddHeapTask(self) &&
concurrent_gc_pending_.CompareExchangeStrongSequentiallyConsistent(false, true)) {
//给task_processor_添加任务,由HeapDaemonTask线程进行遍历消费
task_processor_->AddTask(self, new ConcurrentGCTask(NanoTime(),
force_full));
}
//...
}接下来我们来看下ConcurrentGCTask具体做了哪些事。
ConcurrentGCTask
ConcurrentGCTask继承自HeapTask,除了GC之外也会有一些其他和Heap相关的任务,比如TriggerPostForkCCGcTask、HeapTrimTask。在Run方法中先是执行Heap的ConcurrentGC方法真正执行并发GC逻辑,待GC逻辑完成后调用ClearConcurrentGCRequest()清除pending任务的状态,这和上文AddTask时候的检测逻辑对应。
class Heap::ConcurrentGCTask : public HeapTask {
virtual void Run(Thread* self) OVERRIDE {
gc::Heap* heap = Runtime::Current()->GetHeap();
//调用ConcurrentGC
heap->ConcurrentGC(self, force_full_);
//将concurrent_gc_pending重置为false
heap->ClearConcurrentGCRequest();
}
};
void Heap::ClearConcurrentGCRequest() {
concurrent_gc_pending_.StoreRelaxed(false);
}在ConcurrentGC方法中主要调用了CollectGarbageInternal去尝试不同力度的GC,直到回收成功。
void Heap::ConcurrentGC(Thread* self, bool force_full) {
//如果有正在执行中的GC任务就不在重复GC,返回kGcTypeNone表示没有正在执行GC
if (WaitForGcToComplete(kGcCauseBackground, self) == collector::kGcTypeNone) {
collector::GcType next_gc_type = next_gc_type_;
if (force_full && next_gc_type == collector::kGcTypeSticky) {
next_gc_type = HasZygoteSpace() ? collector::kGcTypePartial : collector::kGcTypeFull;
}
//最终调用到CollectGarbageInternal 方法,这个方法是所有GC执行的入口,如果返回kGcTypeNone表示没有展开回收工作
if (CollectGarbageInternal(next_gc_type, kGcCauseBackground, false) ==
collector::kGcTypeNone) {
//好不容触发一次GC不能就此终止,下面将尝试回收力度更大的策略进行回收,直到回收成功
for (collector::GcType gc_type : gc_plan_) {
if (gc_type > next_gc_type &&
CollectGarbageInternal(gc_type, kGcCauseBackground, false) !=
collector::kGcTypeNone) {
break;
}
}
}
}
}CollectGarbageInternal是Heap指挥垃圾收集执行GC的入口方法,在上文分配GC时候我们看到调用的是这个方法,马上来看这个方法。这个方法参数的意思就不多解释了,返回值表示的是本次GC实际使用的gc_type,可能和入参不同,如果返回kGcTypeNone表示并没有真正执行GC。
collector::GcType Heap::CollectGarbageInternal(collector::GcType gc_type,
GcCause gc_cause,
bool clear_soft_references) {
bool compacting_gc;
{
// 虚拟机同一时间只能有一个GC在执行,等待上次GC执行完成
WaitForGcToCompleteLocked(gc_cause, self);
}
//记录本次GC执行前堆内存使用的字节数
const size_t bytes_allocated_before_gc = GetBytesAllocated();
if (compacting_gc) {
//根据collector_type_以及 gc_type确定选择的
switch (collector_type_) {
case kCollectorTypeCMC:
collector = mark_compact_;
break;
case kCollectorTypeCC:
collector::ConcurrentCopying* active_cc_collector;
collector = active_concurrent_copying_collector_.load(std::memory_order_relaxed);
break;
}
} else if (current_allocator_ == kAllocatorTypeRosAlloc ||
current_allocator_ == kAllocatorTypeDlMalloc) {
collector = FindCollectorByGcType(gc_type);
}
//运行垃圾回收器的Run方法执行真正的回收工作
collector->Run(gc_cause, clear_soft_references || runtime->IsZygote());
//给task_processor添加一个HeapTrimTask,内部调用HeapTrim
RequestTrim(self);
//GC完成做一些数学计算,计算下target_footprint和下次并发GC触发的阈值
GrowForUtilization (collector, bytes_allocated_before_gc);
//本次GC处理完成
FinishGC(self, gc_type);
//...
return gc_type;
}这里GrowForUtilization方法中有具体计算并发GC阈值的细节,下文还会具体分析一下。
GC Task调度
那么添加给TaskProcessor的后台GC任务怎么执行呢?
是由守护线程HeapTaskDaemon来执行的,HeapTaskDaemon 是一个守护线程,随着 Zygote 进程启动便会启动,该线程的 run 方法也比较简单会执行 VMRuntime.getRuntime().runHeapTasks() 方法,runHeapTasks() 函数会执行 RunAllTasks 这个 native 方法,它位于 task_processor.cc 这个类中。
https://cs.android.com/android/platform/superproject/+/android-7.0.0_r31:art/runtime/gc/task_processor.cc
static void VMRuntime_runHeapTasks(JNIEnv* env, jobject) {
Runtime::Current()->GetHeap()->GetTaskProcessor()->RunAllTasks(Thread::ForEnv(env));
}
void TaskProcessor::RunAllTasks(Thread* self) {
while (true) {
// 从队列里取Task,没有则阻塞等待
HeapTask* task = GetTask(self);
if (task != nullptr) {
// 执行Run
task->Run(self);
task->Finalize();
} else if (!IsRunning()) {
break;
}
}
}GetTask方法如下从Task队列里取出Task并按其执行时间执行,整体和Android的消息队列如出一辙。
HeapTask* TaskProcessor::GetTask(Thread* self) {
//...
while (true) {
if (tasks_.empty()) {
//如果 tasks 集合为空,则休眠线程
cond_.Wait(self);
} else {
// 如果 task是集合不会空,则取出第一个 HeapTask
const uint64_t current_time = NanoTime();
HeapTask* task = *tasks_.begin();
uint64_t target_time = task->GetTargetRunTime();
if (!is_running_ || target_time <= current_time) {
tasks_.erase(tasks_.begin());
return task;
}
// 对于延时执行的 HeapTask,这里会进行等待,直到目标时间
const uint64_t delta_time = target_time - current_time;
const uint64_t ms_delta = NsToMs(delta_time);
const uint64_t ns_delta = delta_time - MsToNs(ms_delta);
cond_.TimedWait(self, static_cast<int64_t>(ms_delta), static_cast<int32_t>(ns_delta));
}
}
UNREACHABLE();
}所以HeapTask的执行是一个单线程任务队列模型,ConcurrentGCTask是在队列中执行,并且同一时间队列里只会有一个ConcurrentGCTask。到这里我们知道Alloc GC是没法抑制的,我们只能针对在HeapTaskDaemon线程中执行的并发GC入手。
抑制并发GC任务
从第一性原理出发
我们已经对对象分配过程中触发的两种类型GC有了比较完整的了解,只能对并发GC任务进行抑制,那具体要怎么做呢?从第一性原理出发,我们不妨再整体回顾一下流程,从中寻找切入点。
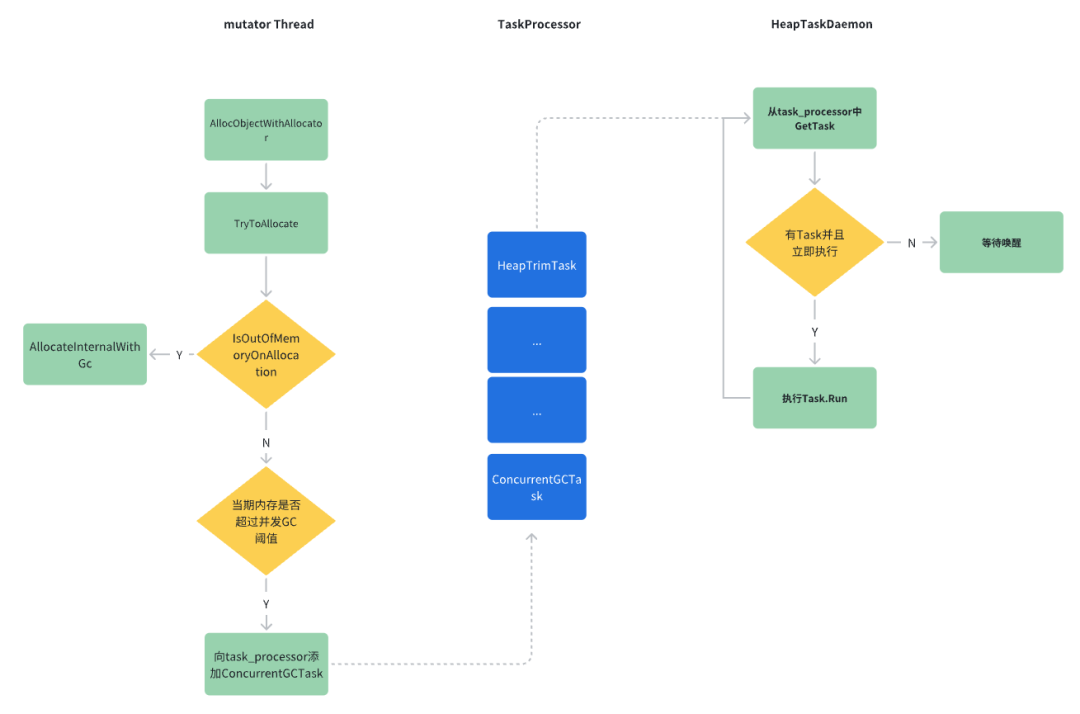
在上面的流程中我们在不考虑实现的情况下,抑制并发GC的切入点可能有如下几个:
-
从并发GC阈值入手,增大阈值进而延迟GC
-
从向task_process添加ConcurrentGCTask入手,丢弃掉Task
-
从ConcurrentGCTask执行Run方法入手,不执行或者阻塞
经过调研,增大GC阈值这种思路google官方在Android 10上已经落地了,另外有网友通过研究GC阈值的计算细节发现通过调节Heap的min_free_和max_free_参数也能变相增大GC阈值;丢弃GCTask这种思路我们通过hook Heap的RequestConcurrentGC 方法应该可以实现,由于并未详细论证和实践本文不再做具体讨论; 阻塞ConcurrentGCTask执行的思路也比较简单,就是hook它的Run方法什么也不执行或者wait一段时间起到延迟执行的作用。 为了对GC抑制有更全面的了解,我们这里还会详细讨论第一种和第三种思路,如果想要看落地方案的话可以直接看下文阻塞ConcurrentGCTask执行 部分 。
增大并发GC阈值
Android 10中的GC抑制
Android 10中在启动的场景下抑制GC 2秒钟,它通过调整并发GC阈值和totalMemory 都为最大值,避免GC的触发,改动在这个commit 可以看。
主要是给Heap增加了PostForkChildAction方法,这个方法在子进程从Zygote fork之后调用,可以看出主要就是把堆内存toalMemory调为最大值并且也把GC并发阈值调为最大值的一半,这样在启动过程中就很难触发并发GC,进而对启动时间有一定优化。
void Heap::PostForkChildAction(Thread* self) {
if (collector_type_ == kCollectorTypeCC && !IsLowMemoryMode()) {
// 设置totalMemory(max_allowed_footprint_) 到最大值growth_limit_
SetIdealFootprint(growth_limit_);
// 是这并发GC阈值 concurrent_start_bytes_ 到 growth_limit_/2
concurrent_start_bytes_ = std::max(max_allowed_footprint_ / 2, GetBytesAllocated());
//向TaskProcessor中添加 TriggerPostForkCCGcTask任务
GetTaskProcessor()->AddTask(
self, new TriggerPostForkCCGcTask(NanoTime() + MsToNs(kPostForkMaxHeapDurationMS)));
}
}在启动kPostForkMaxHeapDurationMS(2000) 时间之后会执行TriggerPostForkCCGcTask主动触发一次GC,由于GC之后并发GC的阈值和max_allowed_footprint_都会重新计算,会恢复到正常值。
class Heap::TriggerPostForkCCGcTask : public HeapTask {
public:
explicit TriggerPostForkCCGcTask(uint64_t target_time) : HeapTask(target_time) {}
void Run(Thread* self) OVERRIDE {
gc::Heap* heap = Runtime::Current()->GetHeap();
// Trigger a GC, if not already done. The first GC after fork, whenever
// takes place, will adjust the thresholds to normal levels.
if (heap->max_allowed_footprint_ == heap->growth_limit_) {
heap->RequestConcurrentGC(self, kGcCauseBackground, false);
}
}
};这个计算是在我们上文中CollectGarbageInternal 完成GC之后的GrowForUtilization方法中,我们接下来会看下这个方案,并介绍下另外一种思路。
调整min_free_和max_free_ 增大GC阈值
void Heap::GrowForUtilization(collector::GarbageCollector* collector_ran,
uint64_t bytes_allocated_before_gc) {
// 获取本次 GC 后,堆已分配的字节数
const uint64_t bytes_allocated = GetBytesAllocated();
// 如果是后台应用,multiplier 是 1.0,如果是前台应用,根据系统版本,可能是 2.0 或 3.0
const double multiplier = HeapGrowthMultiplier();
const uint64_t adjusted_min_free = static_cast<uint64_t>(min_free_ * multiplier);
const uint64_t adjusted_max_free = static_cast<uint64_t>(max_free_ * multiplier);
/* targetHeapUtilization 默认是 0.75,表示堆内存的利用率
delta 相当于根据 targetHeapUtilization 和 bytes_allocated 计算出来的堆内存未分配的字节数*/
ssize_t delta = bytes_allocated / GetTargetHeapUtilization() - bytes_allocated;
// target_size 相当于当前 heap 内存大小
target_size = bytes_allocated + delta * multiplier;
// 注意,这两行代码,相当于限制堆内存的未分配的字节数,在 [adjusted_min_free,adjusted_max_free]
target_size = std::min(target_size, bytes_allocated + adjusted_max_free);
target_size = std::max(target_size, bytes_allocated + adjusted_min_free);
// 将 max_allowed_footprint_ 设置为 target_size
SetIdealFootprint(target_size);
// 计算本次 GC 释放的字节数
const uint64_t freed_bytes = current_gc_iteration_.GetFreedBytes() +
current_gc_iteration_.GetFreedLargeObjectBytes() +
current_gc_iteration_.GetFreedRevokeBytes();
// 计算在本次并发 GC 期间,堆上新分配的字节数
const uint64_t bytes_allocated_during_gc = bytes_allocated + freed_bytes -
bytes_allocated_before_gc;
// 计算本次并发 GC 的时间
const double gc_duration_seconds = NsToMs(current_gc_iteration_.GetDurationNs()) / 1000.0;
/* 估算当我们需要启动下一个 GC 时,我们堆上至少需要有多少剩余的未分配字节
目的是确保下次并发 GC 时,堆上还有未分配的内存供给用户线程创建对象时使用*/
size_t remaining_bytes = bytes_allocated_during_gc * gc_duration_seconds;
// 计算下一次 GC 触发的堆内存阈值
concurrent_start_bytes_ = std::max(max_allowed_footprint_ - remaining_bytes,
static_cast<size_t>(bytes_allocated));
}
void Heap::SetIdealFootprint(size_t max_allowed_footprint) {
if (max_allowed_footprint > GetMaxMemory()) {
max_allowed_footprint = GetMaxMemory();
}
//给max_allowed_footprint_赋值
max_allowed_footprint_ = max_allowed_footprint;
}上面的代码其实就为了计算两个变量的值,一个是toalMemory( max_allowed_footprint), 另一个是下次并发GC的阈值(concurrent_start_bytes_ )。
-
max_allowed_footprint的也就是target_size的计算,主要是在目前占用的内存bytes_allocated加上一个delta来保证当然堆的利用率在0.75以下,计算出来之后需要保证target_size在 [ bytes_allocated + adjusted_min_free,bytes_allocated + adjusted_max_free]之间。
-
concurrent_start_bytes_的计算是先根据这次GC执行期间分配的内存和执行时间预估出来下次GC期间分配的空间大小remaining_bytes,GC并发阈值就是taget_size- remaining_bytes。
由于remaining_bytes和程序本身有关不受控制,可以看出GC并发阈值的大小基本是由taget_size决定的,而taget_size会保证在 [ bytes_allocated + adjusted_min_free,bytes_allocated + adjusted_max_free] 之间,所以我们只需要同时调大min_free_和max_free_就可以间接实现增大GC阈值,这个方案在GC 抑制 文章中有一个Demo实现,只兼容Android 7.0版本,感兴趣的同学可以自行查看。
https://juejin.cn/post/7291834381314916404?from=search-suggest#heading-4
增大并发GC阈值的方案无论哪个都要修改Heap的成员变量,对结构体成员变量的寻址我们只能通过内存偏移去寻找,由于Android不同版和厂商都可能会对Heap结果进行调整,所以兼容性和稳定性都会比较差,本文并没有采用这种方案。
阻塞ConcurrentGCTask执行
阻塞ConcurrentGCTask执行的话就是hook其Run方法,直接不执行或者wait一段时间起到抑制作用。经过实际测试发现不执行Run方法是行不通的,因为在触发并发GC时候会检查有没有正在执行的ConcurrentGCTask,如果有的话就不会触发,而在ConcurrentGCTask的Run方法中执行完成时候才会重置这个标记,如果不执行的话会导致并发GC再也无法触发。这也是上文中埋的一个伏笔,可以跟进RequestConcurrentGC方法中的concurrent_gc_pending_变量。所以我最终落地的方案是在Run方法中wait,通过另一个方法唤醒从而停止抑制。
实现细节
ConcurrentGCTask的Run方法重载自Closure的虚函数,因此针对这个修改我们可以使用虚函数hook,另外可以使用更加通用的inline hook。由于我们已经验证了字节的shadowhook(还是比较稳定的,本文采用inline hook。
-
通readelf查询符到对应的符号ConcurrentGCTask的Run方法符号为_ZN3art2gc4Heap16ConcurrentGCTask3RunEPNS_6ThreadE

-
使用shadowhook对该函数进行hook
bool hookConcurrentGCRun() {
//already hook success
if (gcStub != nullptr) {
return true;
}
void *origin;
int androidApi = android_get_device_api_level();
if (androidApi < __ANDROID_API_M__) {
return false;
}
char *gcSymbol = FUNC_CONCURRENTGCTASK_RUN;
gcStub = shadowhook_hook_sym_name("libart.so", gcSymbol, (void *) gcRunProxy, &origin);
if (gcStub == nullptr) {
int err_num = shadowhook_get_errno();
const char *err_msg = shadowhook_to_errmsg(err_num);
log("hook GC error %d - %s", err_num, err_msg);
return false;
}
log("hook GC run success");
return true;
}
-
代理函数gcRunProxy实现
直接在这个函数里不调用原始Run方法来抑制GC任务,当想要停止抑制时候unhook ConcurrentGCTask.Run函数。
void gcRunProxy(void *task, void *thread) {
SHADOWHOOK_STACK_SCOPE();
if (task == nullptr || thread == nullptr) {
Utils::log("GC task or thread is null");
SHADOWHOOK_CALL_PREV(gcRunProxy, task, thread);
return;
}
Utils::log("Trigger Background GC and wait");
std::unique_lock<std::mutex> lock(gcMutex);
//wait to notify
while (suppression) {
gcCv.wait(lock);
}
SHADOWHOOK_CALL_PREV(gcRunProxy, task, thread);
Utils::log("Background GC done");
}停止抑制只要notiy就行了。
本地测试
我们通过不停地调用createObject()来创建局部对象来进行测试,通过打印maxMemory、totalMemory和freeMemory来观察堆内存的情况,测试代码如下:
private Person[] createObject() {
int arraySize = 1000000 / 10;
Person[] largeArray = new Person[arraySize];
// Fill the array with some data
for (int i = 0; i < arraySize; i++) {
Person p = new Person("sssssssssssssssss" + i, i);
largeArray[i] = p;
}
return largeArray;
}| 测试情况 | 测试结果 |
|---|---|
| 抑制前: |
|
| 抑制后直接在Run方法中一直抑制,分别在Android 8.1和Anddroid 10上测试 | Android 8.1:
|



到这里我们就实现了一个GC抑制的基本模型,但是我们到底抑制多久呢,是不是一直抑制就好呢?
答案显然是否定的,抑制过久可能会引起Alloc GC 从而适得其反,另外过多的垃圾对象会占用额外的物理内存,所以我们只在一些用户交互的场景下抑制一段时间,并且通过AB实验验证多长时间的效果会更好。
场景和策略
场景选择
关于场景的话主要是选择了启动、滑动和页面打开时间这些场景。
| 场景 | 页面 | 抑制开始 | 抑制结束 |
|---|---|---|---|
| 启动 | 启动路径 | 启动开始 | 首帧渲染完毕 |
| 滑动 | 搜索页 | 滑动开始 | 滑动停止 |
| 页面打开 | 搜索页 | Activity.onCreate 最开始 | 页面第一帧渲染结束 |
超时自动停止抑制
上述的GC抑制开始和停止 必定需要成对出现,否则容易导致抑制一直没停止,为了避免这种异常情况,我们在开始GC抑制时候增加一个超时自动停止的策略,比如超过10s没有停止的话自动停止抑制。
堆使用超过阈值禁止抑制
当堆内存使用占比超过一定比例(比如85%)之后,内存就很容触顶触发Alloc GC, 所以我们这种情况下我们就不要抑制了。
优化效果
经过线上AB实验验证,GC抑制对冷启动、页面打开、滑动等场景下都有不错的收益。
- 对冷启动速度收益约150ms

- 对某核心页面的打开时间优化100ms

- 对某核心页面滑动流畅度值优化2%

总结
本文从线下发现的GC导致主线程卡顿的问题入手引出抑制GC解决问题的思路,并对ART虚拟机执行GC的类型和触发时机做了详细的分析。从第一性原理出发,寻找可能的两种解决思路,分别是增大并发GC阈值和阻塞ConcurrentGCTask执行,并在这两种思路下探讨可落地的方案,最终成功找到阻塞ConcurrentGCTask执行的方案,并上线通过AB实验验证收益。也给我们的一些经验上的感悟:
-
之前看到有些同学说做了GC抑制发现没有任何作用,我想说的是我们要对症下药,有症状才能治,通过线下工具或者线上监控分析确定有对应的症状是决定我们成功的第一步。有症状吃了药没治好,才到第二步分析药本身是不是有问题。
-
在探索GC抑制方案的过程中,依然遵循第一性原理,从事物的本质出发,梳理每一个环节,大胆假设方案,小心求证
参考文档
作者:三雒
链接:https://juejin.cn/post/7381388012276580371
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









