






1.总述
在构建爬虫体系的时候,参考了现在的各种爬虫框架,如:python的scrapy框架,java的webmagic等等,但是都有一些问题
无法回避,即:如果抓取的网页特别多,不是几百上千个,而是以万为单位来计数的话,怎么办?不可能每个url地址都去写解析,
都在线抓取,那么怎么设计一个通用的爬虫流程处理体系,尽量少写代码,利用开放式的插件体系与参数配置来解决这个问题,
就显的尤为重要.本文就针对这个问题,进行如下方案设计.针对这个问题,我们将爬虫设计为4个阶段:初始化任务阶段(url地址的
初始化),下载阶段(download,将url地址对应的内容下载为服务器上的txt文本),解析阶段(解析内容,以及发现新的url地址),
数据入库(数据存储,入mongodb或者其他类型的数据库).这样就能将整个过程进行流程化处理.2.任务作业设计
在这里,利用库表的方式进行爬虫任务的设计工作.如果以后数据量比较大,可以考虑分库分表的方式来做.当然,当量很大的时候,对url地址的过滤,有点问题,可采取redis过滤或者利用md5主键过滤或者BloomFilter过滤,方法很多,可自行选择。
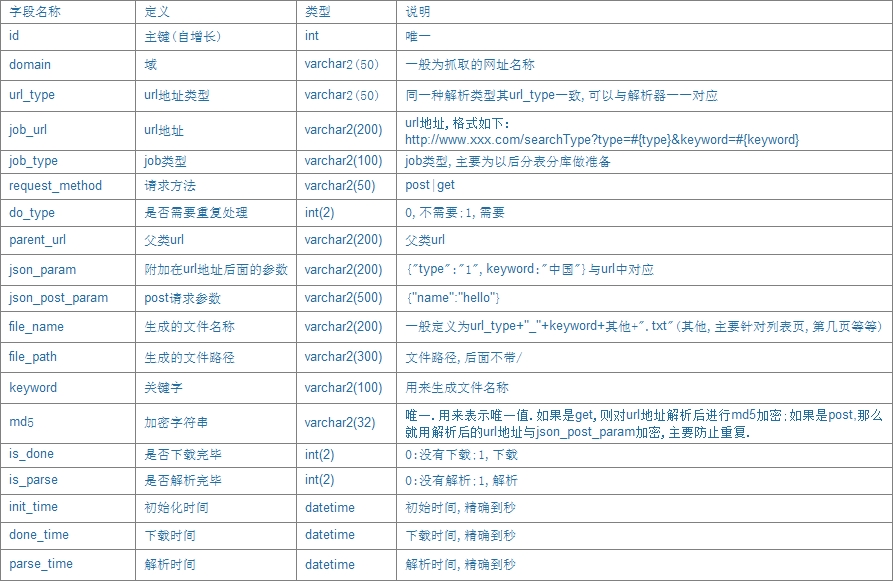
3.任务的初始化操作
在任务的初始化阶段,由于外界因素比较多,那么如何在多变的外界环境下,统一生成url任务呢?我们先来分析外界因素有哪些?
1.搜索型的.例如利用关键字来查询.此时给出的外界因素就是一个excel文件,那么我们如何设置输入参数呢?
url:http://www.xxx.com/searchAll
requestMethod:post
jsonParam:{t:now()}
jsonPostParam:{objectType:2}
paramFileName:/Users/dev/data/1.xls(或者windows下的路径)
这个xls可能很大,也可能很小,怎么处理?有可能是一个字段,有可能是多个字段.now()为Long类型的毫秒数,
这个视情况而定,为自定义的.
2.在解析文本之后,才发现新的URL任务地址,此时就需要在解析器中进行设置初始化任务。初步考虑是利用xml配置来实现解析任务.
根据解析规则来实现任务的初始化操作4.数据下载
在这里,利用HttpClient4.5.2来实现针对post和get不同方式下的数据下载任务
在这里,需要注意以下几个因素
1.ip代理的问题.需要自己准备一个ip代理池.如果抓取频率太高,很容易导致IP被封
2.抓取的RequestHeader设置,一般来说,需要设置如下几个参数:
userAgent:(一般情况,会有一个UserAgent列表,每次随机获取一个)
Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36
Proxy-Connection:keep-alive
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Encoding:gzip, deflate, sdch
Accept-Language:zh-CN,zh;q=0.8
Cache-Control:max-age=0
Host:www.xxx.com
Referer:http://www.xxx.com/5.数据解析
根据数据格式的不同,可以分为以下几种数据格式
1.html格式:利用xpath来解析.这里需要注意几点,有可能在此过程中,同时有明细和列表页以及新的url任务的获取等操作.
需要明确对待
2.json格式:需要明确,有可能是个列表页,含有pageNumber等字段,需要解析JSONArray再获取内容;
也有可能直接解析一个JSONObject
3.javascript格式:这类数据比较特殊,目前我看到的,有一个数组格式的,有json格式的,都基本是如下定义的:
var Data_ACWorthTrend = [[1438272000000,1.0],[1438617600000,1.0],[1438876800000,1.0]];
var Data_performanceEvaluation =
{"avr":"51.50",
"categories":["选证能力","收益率","跟踪误差","超额收益","管理规模"],
"dsc":["反映基金挑选证券而实现风险调整\u003cbr\u003e后获得超额收益的能力",
"根据阶段收益评分,反映基金的盈利能力","根据基金跟踪指数的密切程度评分",
"反映基金投资的超额风险所带来的超额收益","根据基金的资产规模评分"],
"data":[60.0,60.0,50.0,50.0,50.0]
};6.数据入库
在这里,为了实现的方便,可以考虑mongodb来存储数据,如果条件受限,采取mysql等也可以,唯一区别是mysql需要建表,
针对不同的抓取任务建立不同的数据表,而mongodb则不需要建表.针对这种方式,可以视自己的情况而定7.ip代理池
在ip代理这块,可以考虑开源的python实现的IP代理池 IPProxyPool.我们采取的方案是代理池中的ip用python实现,
然后入mysql数据库,然后单独提供一个API接口(用java实现,RPC接口)供其他方调用,尽量保证IP的调用频率在同一个级别上,
确保不会出现某些IP调用次数过大,某些IP调用频率过低的情况。这个算法与url任务中的domain域有关.















 554
554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









