






大家都知道PDF文件是由高清图片和文字内容组合而成的文件。当大家在浏览PDF文件时,想要使用文件当中的图片,就需要将文件当中图片给提取出来。可是大家也知道PDF文件无法直接编辑操作,因此提取图片也是相当复杂。下面小编就教给大家如何提取PDF文件中图片。

1.在线提取PDF文件中的图片。在百度当中搜索迅捷PDF在线提取图片,点击进入操作页面。在页面内找到并点击选中PDF图片获取。
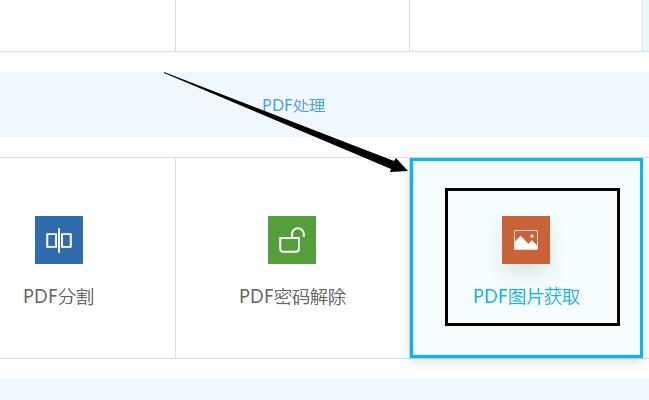
2.在提取图片前,先选择需要提取图片的页面页码数,然后也需要选择提取出的图片格式为jpg或png。
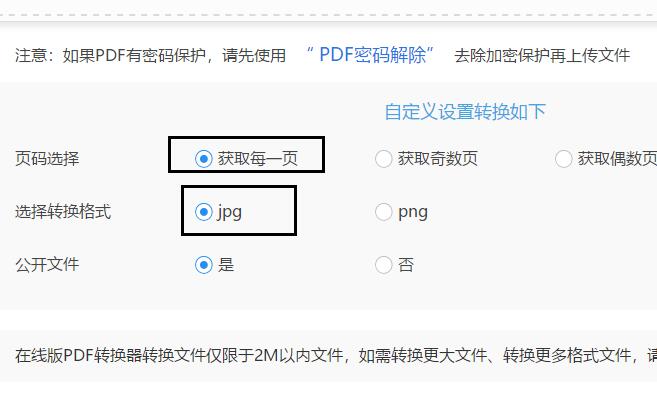
3.移动鼠标点击选择文件选项,把要提取图片的PDF文件添加到页面当中。在弹出的窗口中选中PDF文件,点击右下角打开键即可。
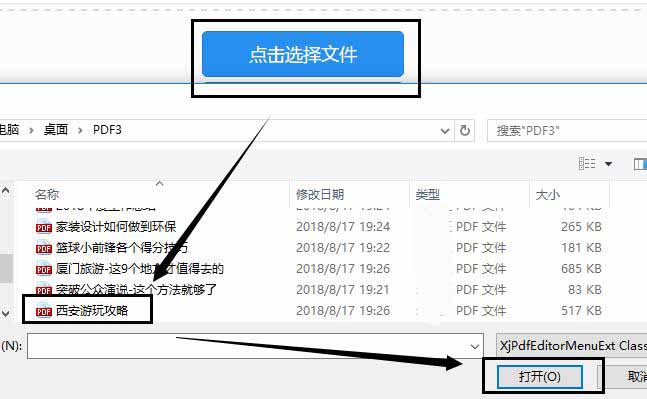
4.鼠标点击文件右下角的开始获取选项,稍加等候后PDF文件中的图片就会提取出来。
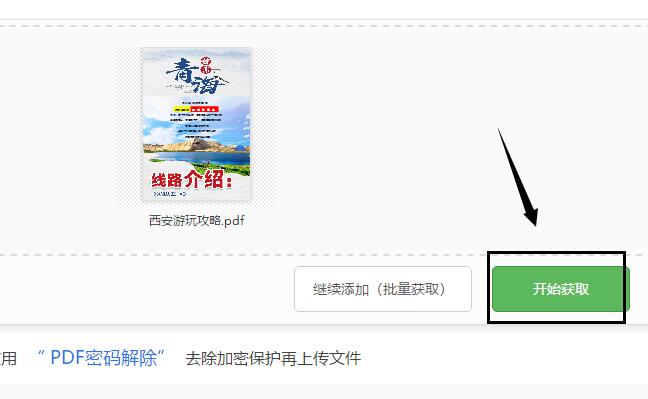
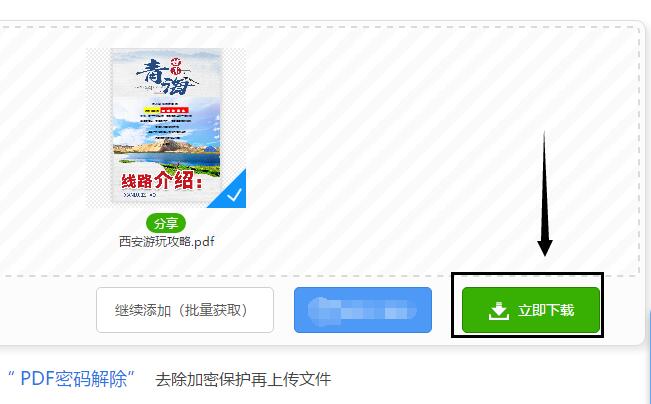
5.当提取图片操作完成后,鼠标点击立即下载选项,将图片下载到电脑当中进行保存与使用。在接下来文章内容中还会与大家分享另外种提取PDF文件图片的方法。
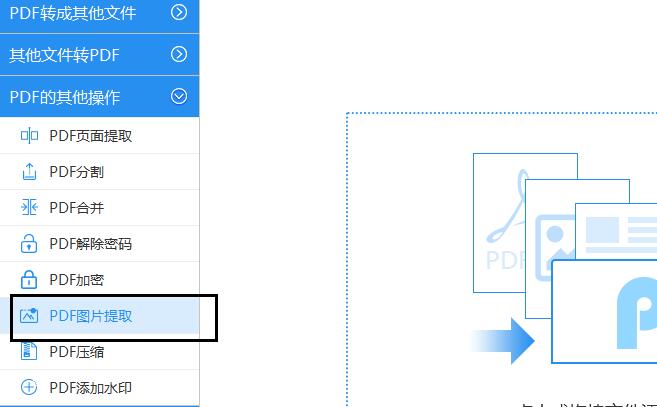
1.打开迅捷PDF转换器进入到操作界面中,鼠标单击选择界面内左侧的PDF的其他操作,接着再单击选择下方的PDF图片提取。
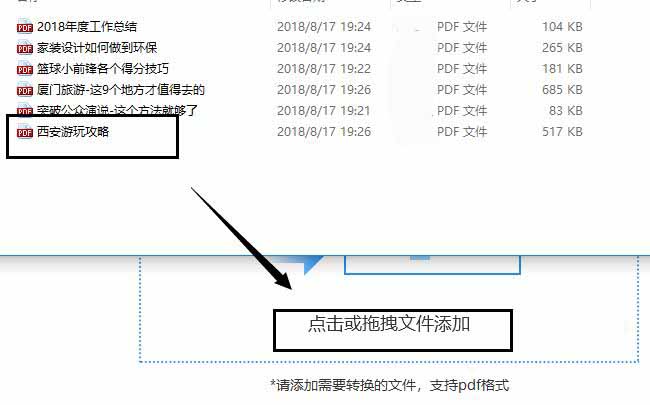
2.打开存储PDF文件的文件夹,选中PDF文件将它拖拽到转换器界面当中。
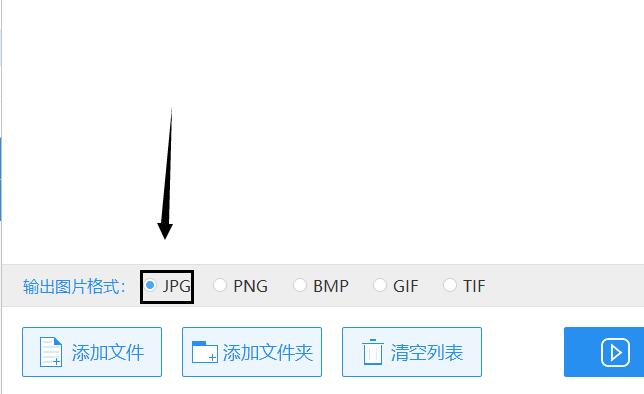
3.图片的格式有很多种,大家在转换器内对提取后图片的格式进行选择。小编选择得是jpg格式。
4.鼠标点击界面内上方的自定义按钮,再点击右侧的浏览选项。在弹出的窗口中选中文件夹,再点击右下角的选择文件夹选项,就可成功为提取后的图片设置保存路径。
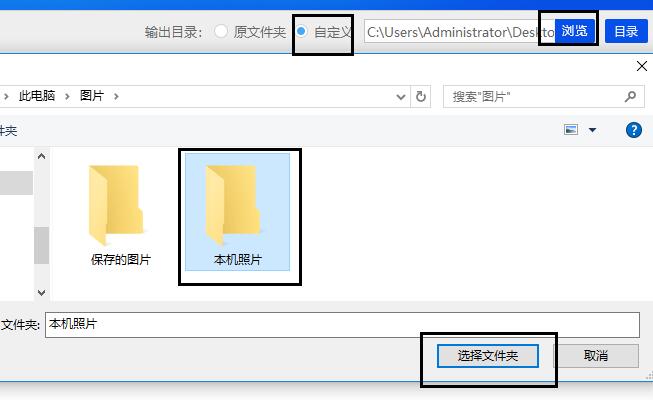
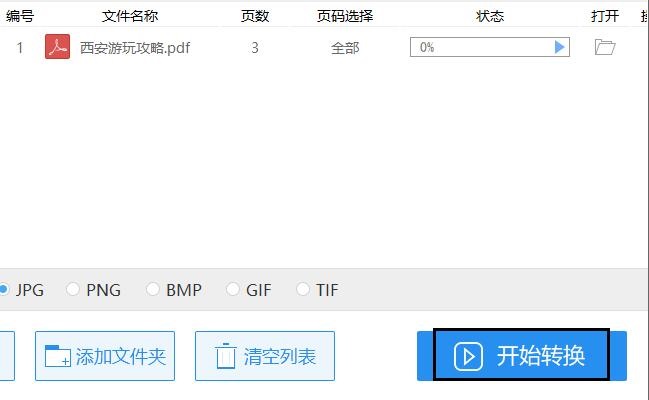
5.移动鼠标左击界面右下角的开始转换选项,转换器就会开始提取图片的操作任务。
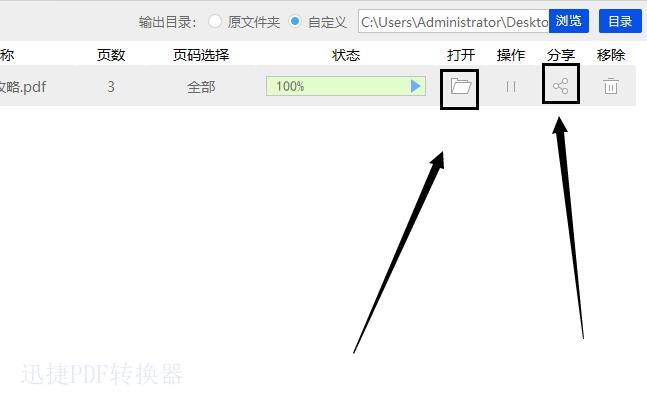
6.当图片成功提取出来后,鼠标点击打开选项下的图片就可将提取出的图片自动打开;点击分享下的图标就能将提取后的图片分享给同事或朋友。
在本文中小编已经把如何提取PDF文件中图片的两种操作方法都详细地告诉了各位小伙伴。希望这些操作方法都帮助大家解决工作中的问题,完成学习中的任务。















 3662
3662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









