






如何提取PDF文件中的高清图片?现在很多的文件都是以PDF格式上传到网络上,因为在PDF文件中内容丰富,图片清晰且文件内容的排版十分美观。当大家浏览PDF文件时,看到文件内有着自己所需的高清图片,那么这种情况下如何将PDF文件中的高清图片提取出来呢?接下来的文章内容中小编会以多个方法教会大家提取PDF文件中的图片。

1.直接打开PDF文件,登陆扣扣,按住键盘中的ctrl+Alt+A就能将图片内容通过截图的方法保存下来。但是截图所留存的图片分辨率普遍较低,就会导致图片不清晰。若文件内图片过多,一张张截图也十分麻烦。那么还有什么其它提取图片的方法吗?

2.在电脑当中安装个ps工具并打开,鼠标点击界面左上角的【文件】——【打开】,将PDF文件在ps当中打开。
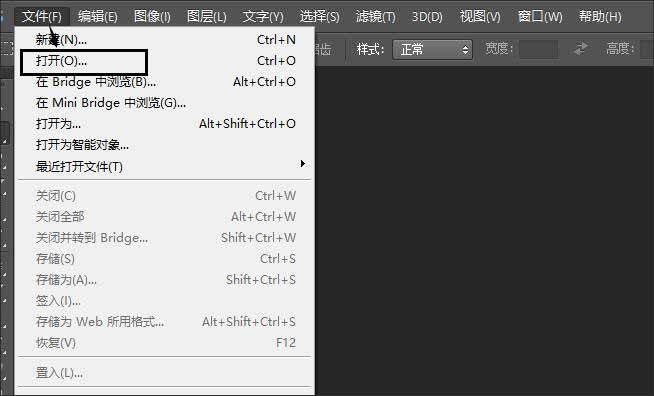
3.在弹出的导入PDF窗口中,鼠标点击选中【图像】选项,然后按住键盘上的crtl键,鼠标左击选中要提取的图片,然后点击右下角【确定】即可。
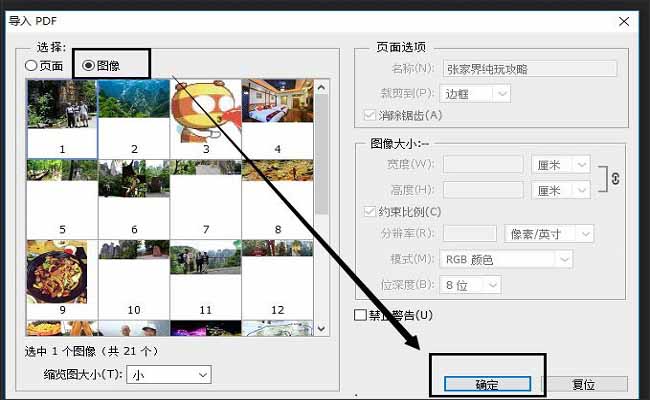
4.接下来在ps当中将选中的图片挨个保存到电脑当中。按下键盘中的ctrl+s,在跳出的窗口内为图片选择保存地址,然后将图片格式更改为所需格式,再点击右下角的【保存】,就成功将PDF文件中的图片提取到电脑当中了。
5.除了使用ps之外,小编还告诉大家操作更为简单,效率较高的提取方法。大家先需要在百度中搜索关键词迅捷PDF转换器,将具有提取PDF图片功能的转换器安装到电脑内。

6.将转换器打开进入到操作界面,首先选择相应的功能。鼠标点击【PDF的其他操作】——【PDF图片提取】。
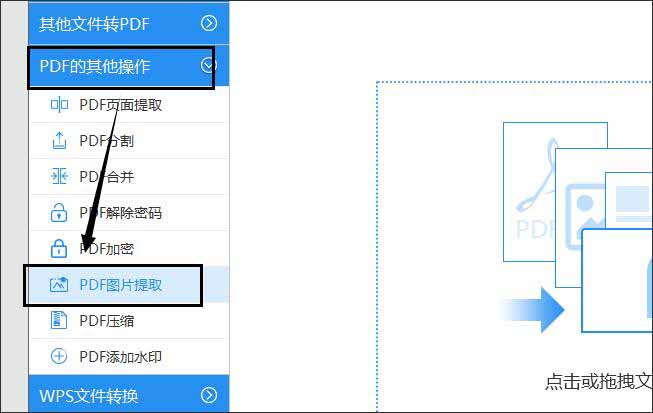
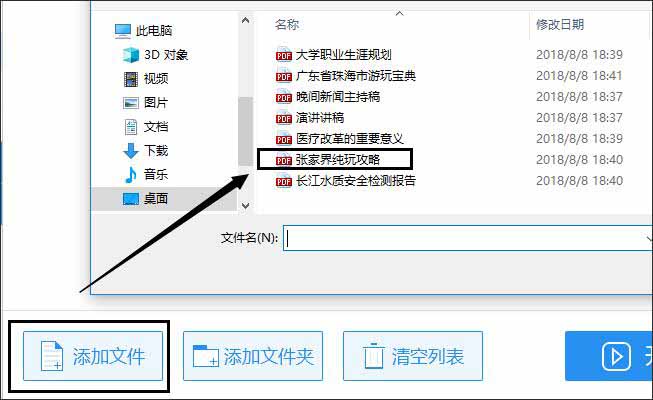
7.点击界面中的【添加文件】——在窗口中鼠标双击要提取图片的PDF文件,就能将其添加到转换器中。
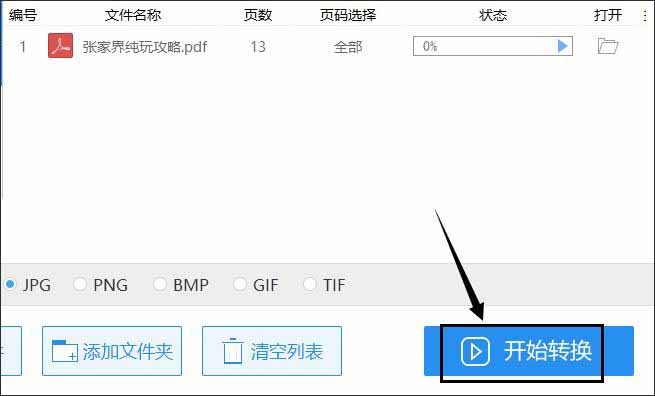
8.大家都知道图片的格式有很多种,在转换器中根据自己的需求设置好提取出的图片格式。

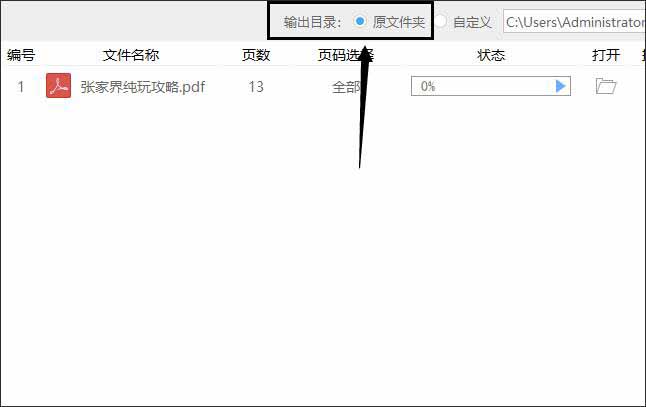
9.在提取图片之前,要为提取出的图片设置保存地址便于查找。鼠标点击转换器内的【原文件夹】,就可将提取出的图片存放在存储原PDF文件的文件夹当中。
10.设置完保存地址后,鼠标点击界面内右下角的【开始转换】,转换器就会开始提取PDF文件当中的图片了。
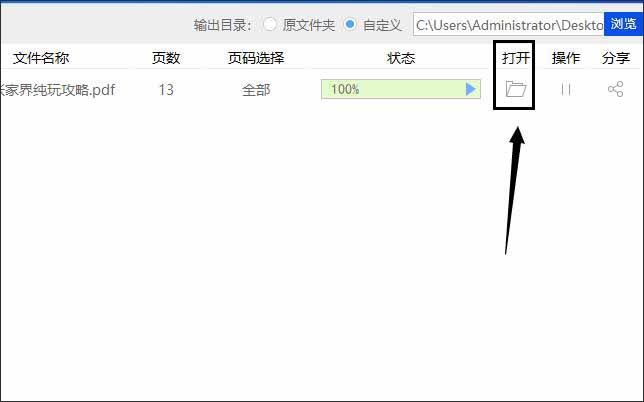
11.图片提取完成后,鼠标点击界面只【打开】选项下的小文件夹图标,就会将提取的图片自动打开供大家查看了。
在这篇文章当中小编告诉大家三种如何提取PDF文件中的高清图片的方法。每一种方法都可以成功将PDF文件当中的图片提取出来,大家可选择自己喜欢的操作方法。希望这次地分享能使大家有所收获,也十分感谢支持小编的小伙伴。今后小编还会教给大家其它的实用干货技巧。















 234
234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









