







Solr使用-创建集合表、存储、查询
上一章我们讲到了Solr的安装和部署,最后的结果是能看到Solr服务器启动状态,如果我们要使用Solr进行开发,还需要在Solr上创建数据集合,然后使用数据集合存储我们业务数据,然后进行查询、排序等等。再下一步就是使用Java环境进行开发了。
(1)创建Solr数据集合
1: 添加数据集合文件
如果你看到了solr主界面,说明你完成了第一步。这一步只能说明你打好了solr的基础,下一步将是见证奇迹的时刻。
首先进入tomcat/webapps/solr/solr/目录,然后创建一个test目录,在test目录中再创建conf目录,
可以从solr源码获取elevate.xml、schema.xml、solrconfig.xml三个文件,拷贝到conf目录下,也可以通过下面的方式配置。
2. 增加数据集合
数据集合文件放置完成后,重启tomcat,然后创建名称为test的数据集合。如果提示Add Core错误,很重要的原因是配置目录错误或者冲突。添加成功后,会在侧面出现一个test的选项卡,在【Core Selecter】下拉菜单中可以找到test选项,选择Documents,可以向数据集合中添加JSON、XML、CVS、FILE等文件格式的数据,但是如果我们直接点击添加,会出现错误,因为demo中【{"id":"change.me","title":"change.me"}】这个数据内容不符合conf中schema.xml的格式要求。




3. schema.xml格式要求
回顾我们test目录,在conf目录下,有很多文件,其中最关键的就是 【schema.xml】,这个是test这个数据集合能存储数据类型和格式的定义文件,如果不符合,存储就会失败,我们来看看【schema.xml】的内容:
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="example" version="1.5">
<field name="_version_" type="long" indexed="true" stored="true"/>
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="name" type="string" indexed="true" stored="true" />
<field name="price" type="double" indexed="true" stored="true" />
<field name="display_picture" type="string" indexed="true" stored="true" />
<field name="release_time" type="long" indexed="true" stored="true" />
<field name="release_state" type="int" indexed="true" stored="true" />
<field name="deals" type="long" indexed="true" stored="true" />
<field name="hits" type="long" indexed="true" stored="true" />
<uniqueKey>id</uniqueKey>
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true" />
<fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0" />
<fieldType name="float" class="solr.TrieFloatField" precisionStep="0" positionIncrementGap="0" />
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0" />
<fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" positionIncrementGap="0" />
<fieldType name="date" class="solr.TrieDateField" precisionStep="0" positionIncrementGap="0" />
</schema><schema>标签下的<field>标签表示字段类型,其中_version_是系统自带的,类似于HBase中的时间字段。
<uniqueKey>标签定义那个字段是这个数据集合的主键,存储时是唯一的,类似Oralce、MySQL的主键,区别就是重复存储时,会覆盖,而Oracle、MySQL会报错。
<fieldType>标签是定义<field>标签 【type】字段数据类型的,上面的定义类型基本上都包括了java的基础类型,另外这个字段还可以用来定义中文分词器,这个是后话了,现在先了解一下。
所有出现在JSON、XML中提交的数据,字段名必须在这个里面能找到,刚才我们手动提交的那个demo中,由于【title】字段在这个schema中没有定义,所以存储失败了。
4. 数据存储。
根据上面的说明,我们可以按照要求进行数据存储了。提交存储数据时,主键是必选的,_version_字段不用填,系统会自动带上。也就是说,可以只提交主键一个字段,或者全部都提交,或者部分提交,没有硬性要求,但是不能没有主键字段。例如:{"id":"1","name":"test1","price":10000}; 返回状态中会返回状态和内容,responseHeader中的status就是返回状态,QTime表示耗时,单位毫秒。

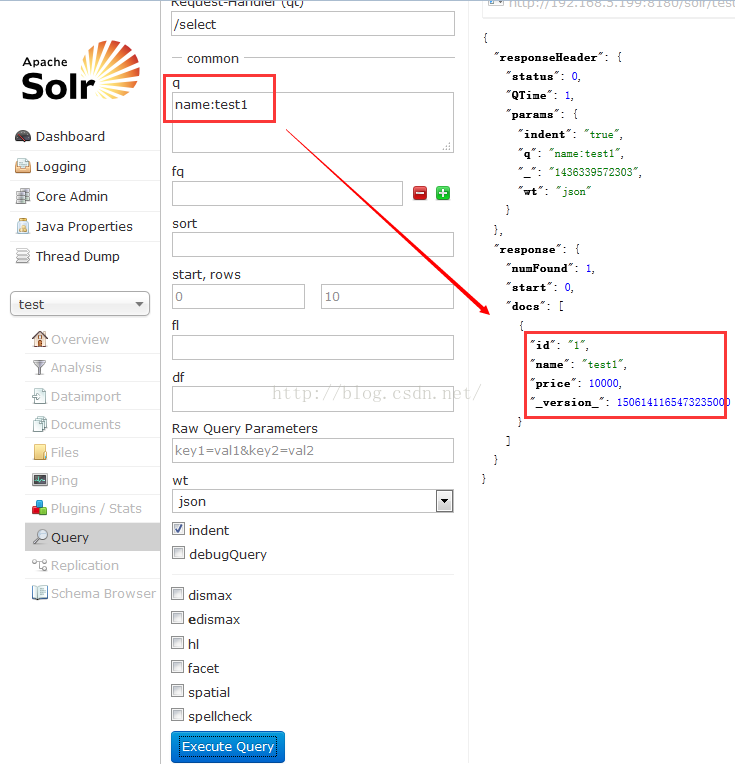
5. 数据查询(检索)
在【Query】菜单中,可以进行数据查询操作,主要是使用Solr的查询规矩语句就能将数据检索出来了。支持全量查询【*:*】和部分查询【name:test1】以及多条件查询【id:1 AND name:test1】,更详细的介绍可以百度。查询检索这个方式与关系型数据库有区别,但是很多思路是一样的,不过大数据量下,Solr支持复杂查询以及中文分词后查询的性能和效率会比传统关系型数据高很多。具体怎么玩,我们一步步来。
















 3989
3989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









