






RuiJi.Net 的设计目标是一个可以分布式部署的 .Net 爬虫框架,项目的目的是对大量的网站进行更新检查及抓取,使用者可以设置新闻源的检查时间间隔,在检测到新闻源更新后,会将更新的地址发送给下载器(或下载节点),再由抽取器(或抽取节点)对数据提取及清洗。
项目地址
https://github.com/zhupingqi/RuiJi.Net
https://gitee.com/zhupingqi/RuiJi.Net
文档
http://www.ruijihg.com/archives/ruijinet/getting-started
RuiJi.Net 爬虫框架 讨论群 545931923
beta 版的演示地址 ,********** ,可以进群看 :)
再者希望对这个项目感兴趣的朋友,请到项目 点亮 Star 谢谢
------------------------------------------------------------------------------------
这篇文章主要介绍RuiJi.Net 的提取模型。
首先 RuiJi.Net 将提取目标页划分为以下模型 分别为 Block Tile Meta
如下图所示

Block为一个提取块,Selectors为Block区域选择器,Tile为Block下重复的块,Meta为Block中重复块外需要提取的元数据。Tile还包含自身选择器及Meta。一个Block可以再包含多个Block,在Block中表现为Blocks。
假设以开源中国博客专区为例,下图红框所示区域,就可以为一个block
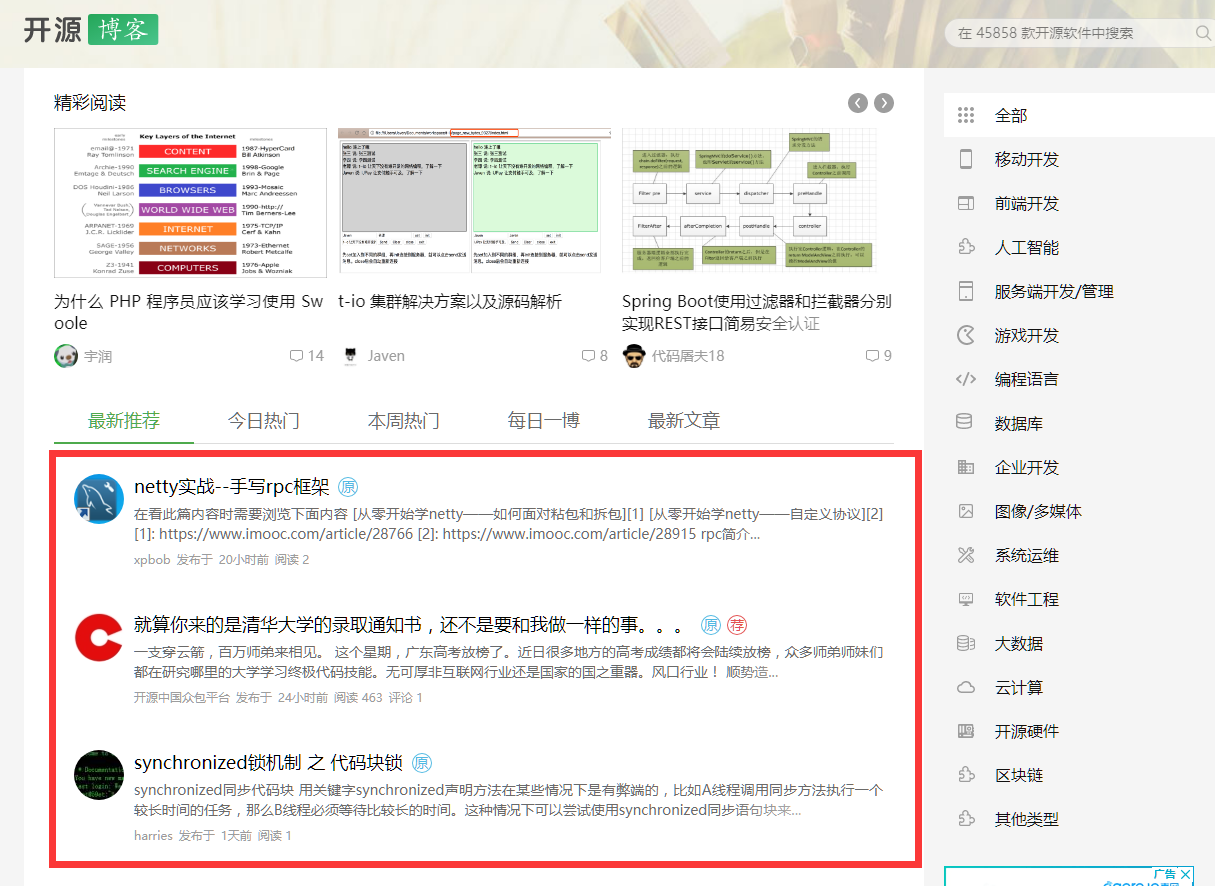
如果需要对这个区域进行提取的话,首先需要定义Block
[Block]
#BlockName
css #topsOfRecommend:ohtml如果直接执行该表达式运行抽取器的话,可以得到该区域的源代码
<div class="blog-list" id="topsOfRecommend"> <!--源创会--> <div class="box item" data-traceid="blog_area_list_ad_1" data-tracepid="blog_area_list"> <div class="box-fl"> <a style="display:block;" href="http://clickc.admaster.com.cn/c/a109734,b2619653,c3159,i0,m101,8a1,8b3,h" target="_blank"> <img class="blog-author" data-delay="https://static.oschina.net/uploads/space/2018/0620/105306_peUw_2663968.jpg"> </a> </div> <div class="box-aw"> <header class="box vertical blog-title-box"> <a class="sc overh blog-title-link" href="http://clickc.admaster.com.cn/c/a109734,b2619653,c3159,i0,m101,8a1,8b3,h" target="_blank" title="huawei"> <h2 class="blog-name sc text-ellipsis">「华为云」云中优选惠,全场低至2折,6.19-6.30开抢,签到抽P20</h2> </a> <div class="box-fr"> <!--<span style="line-height: 20px;display: block;width: 36px;text-align: center;color: #fff;border-radius: 2px;background: #cecece;font-size: .75rem;">广告</span>--> </div> </header> <section class="blog-brief text-gradient">华为云年中钜惠,注册抽免费高配(2核4G)云服务器,单人成团2折起抢购热销云产品;云服务器、数据库、安全防护、大数据等150+云产品,更有精彩好礼送不停!</section> <footer class="box vertical blog-footer-box">
......
<div class="box-aw"> <header class="box vertical blog-title-box"> <a class="sc overh blog-title-link" href="https://my.oschina.net/u/3868959/blog/1835366" target="_blank" title="阿里分布式服务框架Dubbo的架构总结"> <h2 class="blog-name sc text-ellipsis">阿里分布式服务框架Dubbo的架构总结</h2> </a> <span class="blog-tag yuan">原</span> <span class="blog-tag jian">荐</span> </header> <section class="blog-brief text-gradient">Dubbo是Alibaba开源的分布式服务框架,它最大的特点是按照分层的方式来架构,使用这种方式可以使各个层之间解耦合(或者最大限度地松耦合)。从服务模型的角度来看,Dubbo采用的是一种非常简单的模型,要么是提供...</section> <footer class="box vertical blog-footer-box"> <span>OSC_cnhwTY</span> <span>发布于</span> <span>3天前</span> <span>阅读 246</span> </footer> </div> </div> <a class="hide" href="/action/ajax/get_more_recommend_blog?classification=0&p=2"></a> </div>下一步我们尝试提取Tile,如图所示,Tile为Block中每个重复的块
如下图所示
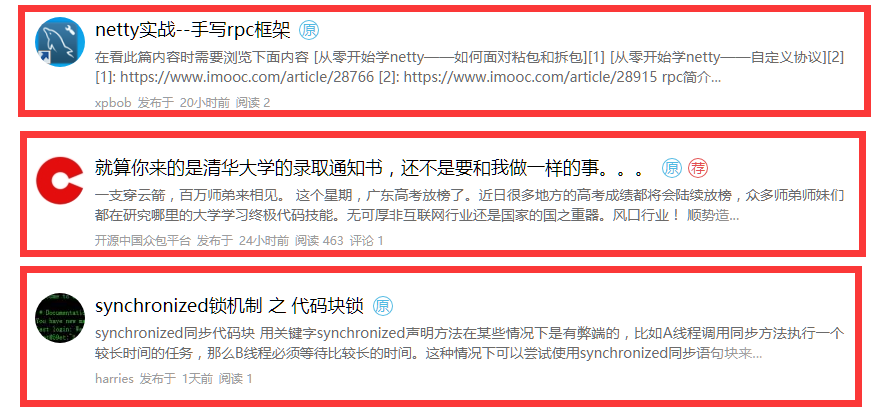
如果我们继续需要对Tile进行抽取,RuiJi Expression 如下
[block]
#BlockName
css #topsOfRecommend:ohtml
[tile]
#titlename
css .box-aw结果用Json格式表示的话,如下
"tiles": [
{
"name": "tile",
"content": "<div class="box-aw"> <header class="box vertical blog-title-box"> <a class="sc overh blog-title-link" href="https://my.oschina.net/xpbob/blog/1836282" target="_blank" title="netty实战--手写rpc框架"> <h2 class="blog-name sc text-ellipsis">netty实战--手写rpc框架</h2> </a> <span class="blog-tag yuan">原</span> </header> <section class="blog-brief text-gradient">在看此篇内容时需要浏览下面内容 [从零开始学netty——如何面对粘包和拆包][1] [从零开始学netty——自定义协议][2] [1]: https://www.imooc.com/article/28766 [2]: https://www.imooc.com/article/28915 rpc简介...</section> <footer class="box vertical blog-footer-box"> <span>xpbob</span> <span>发布于</span> <span>21小时前</span> <span>阅读 2</span> </footer> </div>"
},
{
"name": "tile",
"content": "<div class="box-aw"> <header class="box vertical blog-title-box"> <a class="sc overh blog-title-link" href="http://clickc.admaster.com.cn/c/a109734,b2619653,c3159,i0,m101,8a1,8b3,h" target="_blank" title=" "> <h2 class="blog-name sc text-ellipsis">华为云」云中优选惠,全场低至2折,6.19-6.30开抢,签到抽P20</h2> </a> <div class="box-fr"> <!-- <span style="line-height: 20px;display: block;width: 36px;text-align: center;color: #fff;border-radius: 2px;background: #cecece;font-size: .75rem;">广告</span>--> </div> </header> <section class="blog-brief text-gradient">华为云年中钜惠,注册抽免费高配(2核4G)云服务器,单人成团2折起抢购热销云产品;云服务器、数据库、安全防护、大数据等150+云产品,更有精彩好礼送不停!</section> <footer class="box vertical blog-footer-box"> <span>华为云</span> </footer> </div>"
},
...]那么我们开始提取元数据
* 因为Block和Tile都包含Meta,所以作为Tile的Meta需要每行以\t(1个制表符)开始 *
[block]
#BlockName
css #topsOfRecommend:ohtml
[tile]
#titlename
css .box-aw
[meta]
#title
css .blog-title-link[title]
#author
css .blog-footer-box > span:first:text
#postdate
css .blog-footer-box > span:eq(2):text
#reads_i
css .blog-footer-box > span:last:text
regS / / 1这时候你将得到如下结果
......
{
"name": "tile",
"metas": {
"title": "[译] D3.js 嵌套选择集 (Nested Selection)",
"author": "ssthouse_hust",
"postdate": "2天前",
"reads": 9
}
},
{
"name": "tile",
"metas": {
"title": "GameHollywood 面试笔记",
"author": "uniqptr",
"postdate": "2天前",
"reads": 42
}
},
{
"name": "tile",
"metas": {
"title": "Spring核心——设计模式与IoC",
"author": "随风溜达的向日葵",
"postdate": "2天前",
"reads": 76
}
}
......不知道你有没有注意到Reads,提取结果为数字,这是因为在定义meta的时候 reads 使用了后缀 _i
这将让抽取器将抽取结果转换为数字类型
目前RuiJi Expression 支持以下格式转换
| *_i | int |
| *_s | string |
| *_l | long |
| *_b | bool |
| *_f | float |
| *_d | double |
| *_dt | datetime |
细心的小伙伴们,应该也注意到了日期,postdate所返回的数据并不是我们期待的日期格式,这个在将来会通过选择器的后续处理器来完成(还没有制作),既然提到了选择器,这里先简要给大家个列表,回头我会单写篇文章来介绍
Css 选择器
| css a[href] | select attr |
| css a:text | select text |
| css a:ohtml | select outer html |
| css a:html | select inner html |
| css dd[class=’f12 balck02 yh’] + dd:text | select dd with class = “f12 balck01 yh” next dd text |
Exclude 排除选择器
| ex /abc/ -b | exclude regex with /abc/ at text begin |
| ex /abc/ -a | exclude regex with /abc/ in text |
| ex /abc/ -e | exclude regex with /abc/ at text end |
Expresssion 通配符选择器(仅适用于网址提取)
| exp http://www.ruijihg.com/* | Use wildcards to get the results |
| exp http://www.ruijihg.com/??? | Use wildcards to get the results |
Regex 正则选择器
| reg /稿件来源: .*/ | regex match result |
| reg /稿件来源: (.*)/ 1 | regex matches group 1 |
RegexSplit 分割选择器
| regS /abc/ 3 | regex split with /abc/ and take group 3 |
RegexReplace 替换选择器
| regR /abc/ 123 | regex replace /abc/ with 123 |
TextRange 文本区域选择器
| text /abc/ /123/ | cut text start with /abc/ and end with /123/ |
XPath
| xpath /bookstore/book[1] | xpath… |
JsonPath
| jpath $..url | all url |
最后补充下Block中包含Block的表达式写法,供大家参考
[block]
#name
css .entry-content:html
[blocks]
@block1
@block2
[tile]
#aa
css a:ohtml
[meta]
#time
css time:text
[meta]
#time
css time:text
#author
css .author:text
#title
css .entry-title:text
#content
css .entry-content:html
#link
css h4 a[href] -r
[block]
#block1
css .list1
[block]
#block2
css .list2Block中还有一个 Paging ,在一些具有分页导航的页面进行分页抓取和正文合并使用,这个标记不适合在新闻列表页使用,目前他会自动进行分页提取,直到找不到新的分页为止
[paging]
css .a-page
css a[href]















 180
180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









