







1.目的
以
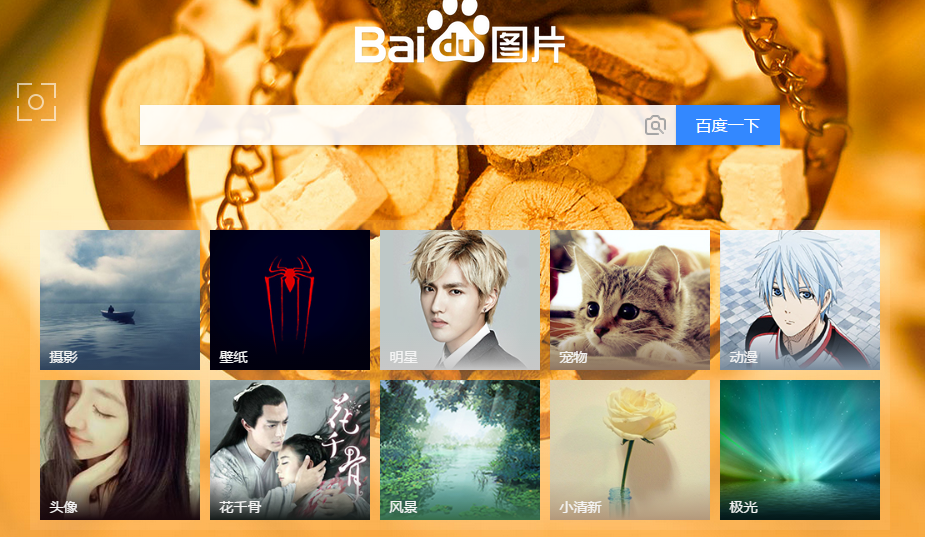
百度图片首页为例,首页如下图所示,网页上有一些图片,我们的目的就是将这些图片保存到本地。
2.源码
#coding=utf-8
#version: python 2.7
#author: Hao Chen
import urllib
import re
#step1.获取整个页面的数据
url="http://image.baidu.com/"
page = urllib.urlopen(url) #打开一个url地址
html = page.read() #读取url上的数据
#step2.删选页面中想要的数据
reg = r'src="(.+?\.jpg)" ' #构建正则表达式
imgre = re.compile(reg) #把正则表达式变异成一个对象
imgList = re.findall(imgre,html) #读取html中包含正则表达式的数据
#直接用以下方法也行,更简便
#imgList = re.findall('src="(.+?\.jpg)" ',html)
#step3.将页面筛选的数据保存到本地
x=0
for imgurl in imgList:
urllib.urlretrieve(imgurl,'%s.jpg'%x) #远程将数据下载到本地
x+=1
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









