







思路的来源
上面讲了一大堆Redis的原理,其实目的就是为了说清楚,Reids为什么快,既然知道了Redis为什么快我们是不是能用相同的思路来优化MySQL和Oracle呢,下面我就来给大家分析一下
MySQL
- 完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。
- 数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的。
- 采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗。
- 使用多路I/O复用模型,非阻塞IO;
- 使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
这里是上一节讲的Redis为什么快,那么咱们考虑一下MySQL是不是可以按照这个思路解决查询效率问题。
MySQL NDB Cluster
1 内存数据库
NDB Cluster是一种在无共享系统中实现内存数据库集群的技术。无共享架构使系统能够以非常便宜的硬件工作,并且对硬件或软件的特定要求最低。
NDB群集的设计不会出现任何单点故障。在无共享系统中,每个组件都应具有自己的内存和磁盘,并且不建议或不支持使用共享存储机制,如网络共享,网络文件系统和SAN。
NDB Cluster将标准MySQL服务器与内存中的集群存储引擎NDB (代表“ Network Data Base ”)集成在一起 。在我们的文档中,该术语NDB指的是特定于存储引擎的设置部分,而“ MySQL NDB Cluster ”指的是一个或多个MySQL服务器与 NDB存储引擎的组合。
NDB群集由一组称为主机的计算机组成,每台计算机 运行一个或多个进程。这些称为节点的过程 可以包括MySQL服务器(用于访问NDB数据),数据节点(用于存储数据),一个或多个管理服务器,以及可能的其他专用数据访问程序。这里显示了NDB集群中这些组件的关系:
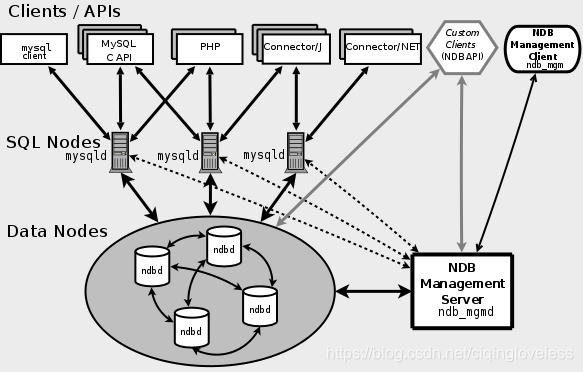
- NDB Management Server:管理服务器主要用于管理cluster中的其他类型节点(Data Node和SQL Node),通过它可以配置Node信息,启动和停止Node。
- SQL Node:在MySQL Cluster中,一个SQL Node就是一个使用NDB引擎的mysql server进程,用于供外部应用提供集群数据的访问入口。
- Data Node:用于存储集群数据;系统会尽量将数据放在内存中。
优点:
-
通过自动分片实现高水平的写入扩展能力
MySQL Cluster 自动将表分片(或分区)到不同节点上,使数据库可以在低成本的商用硬件上横向扩展,同时保持对应用程序完全应用透明。
-
99.999%的可用性
凭借其分布式、无共享架构,MySQL Cluster 可提供 99.999% 的可用性,确保了较强的故障恢复能力和在不停机的情况下执行预定维护的能力。
-
SQL 和NoSQL API
MySQL Cluster 让用户可以在解决方案中整合关系数据库技术和NoSQL技术中的最佳部分,从而降低成本、风险和复杂性。
-
实时性能
MySQL Cluster 提供实时的响应时间和吞吐量,能满足最苛刻的 Web、电信及企业应用程序的需求。
-
具有跨地域复制功能的多站点集群
跨地域复制使多个集群可以分布在不同的地点,从而提高了灾难恢复能力和全球 Web 服务的扩展能力。
-
联机扩展和模式升级
为支持持续运营,MySQL Cluster 允许向正在运行的数据库模式中联机添加节点和更新内容,因而能支持快速变化和高度动态的负载。
2 Hash索引
我们来看看MySQL各个版本支持的索引类型
| Storage Engine | Permissible Index Types |
|---|---|
| InnoDB | BTREE |
| MyISAM | BTREE |
| MEMORY/HEAP | BTREE |
| NDB | HASH, BTREE |
既然这里写了BTREE,那么我在这里描述一下BTREE和HASH索引最大的区别就是,HASH不支持范围查找。
批处理
mysql ndb支持多次操作,一次性执行
Several operations can be defined on the same NdbTransaction object, in which case they are executed in parallel. When all operations are defined, the execute() method sends them to the NDB kernel for execution.
可以通过多次调用NdbTransaction::getNdbOperation()获取多个NdbOperation,针对NdbOperation的增删改只修改本地的数据,当执行NdbTransaction::execute()时,NdbTransaction下的多个NdbOperation被同时发到服务器端,并行执行。
总结
我这里说的是用Redis的思路优化MySQL,不是说用MySQL替换Redis,这点我强调一下,就是在你需要MySQL的时候某些表可以采用这种优化方式加速查询,当然也可以用MySQL当缓存服务器,但是我这里不是说Redis不好MySQL好,这里没有进行这种比较。
Oracle
1 LRU与MRU算法
由于Oracle的源代码无法获取,所以只能从原理上讲讲这两个东西,这两个东西就是计算热区的算法。
1 Cache Hit and Cache Miss
当使用者第一次向数据库发出查询数据的请求的时候,数据库会先在缓冲区中查找该数据,如果要访问的数据恰好已经在缓冲区中(我们称之为Cache Hit)那么就直接用缓冲区中读取该数据.
反之如果缓冲区中没有使用者要查询的数据那么这种情况称之为Cache Miss,在这种情况下数据库就会先从磁盘上读取使用者要的数据放入缓冲区,使用者再从缓冲区读取该数据.
很显然从感觉上来说Cache Hit会比Cache Miss时存取速度快.
LRU(最近最少使用算法) and MRU(最近最常使用算法)
2 LRU链
任何缓存的大小都是有限制的,并且总不如被缓存的数据多。就像Buffer cache用来缓存数据文件,数据文件的大小远远超过Buffer cache。因此,缓存总有被占满的时候。当缓存中已经没有空闲内存块时,如果新的数据要求进入缓存,就只有从缓存中原来的数据中选出一个牺牲者,用新进入缓存的数据覆盖这个牺牲者。这一点我们在共享池中曾提及过,这个牺牲者的选择,是很重要的。缓存是为了数据可以重用,因此,通常应该挑选缓存中最没有可能被重用的块当作牺牲者。牺牲者的选择,从CPU的L1、L2缓存,到共享池、Buffer cache池,绝大多数的缓存池都是采用著名的LRU算法,不过在Oracle中,Oracle采用了经过改进的LRU算法。具体的算法它没有公布,不过LRU算法总的宗旨就是――“最近最少”,其意义是将最后被访问的时间距现在最远的内存块作为牺牲者。比如说,现在有三个内存块,分别是A、B、C,A被访问过10次,最后一次访问是在10:20,B被访问过15次,最后一次访问是10:18,C也被访问10次,最后一次被访问是在10:22。当需要选择牺牲者时,B访问次数最多,牺牲者肯定不是它。A、C访问次数一样,但A在10:20被访问,而C在10:22被访问,A最后被访问的更早些,牺牲者就是A。注意,这就是LRU的宗旨,“将最后访问时间距现在最远的块作为牺牲者”。
为了实现LRU的功能,Oracle在Buffer cache中创建了一个LRU链表,Oracle将Buffer cache中所有内存块,按照访问次数、访问时间排序串在链表中。链表的两头我们分别叫做热端与冷端, 如下图

当你第一次访问某个块时,如果这个块不在Buffer cache中,Oracle要选将它读进Buffer cache。在Buffer cache中选择牺牲者时,Oracle将从冷端头开始选择,在上图的例子中,内存块U将是牺牲者。

如上图,新块将会被读入U,覆盖U原来的内容。这里,我们假设新块是V。但是块V不会被放在冷端头,因为冷端头的块,会很快被当作牺牲者权覆盖的。这不符合“将最后访问时间距现在最远的块作为牺牲者”的宗旨。块V是最后时间距当前时刻最近的,它不应该作为下一个牺牲者。Oracle是如何实验LRU的,我们继续看。

Oracle将LRU链从中间分为两半,一半记录热端块、一半记录冷端块。如上图,而刚刚被访问的块V,如下图:

如过再有新的块进入Buffer cache,比如块X被读入Buffer cache,它将覆盖T,并且会被移至块V的前面,如下图:

大家可以想像一下,如果按照这面的方式继续下去,最右边冷端头处的块,一定是最后一次访问时间距现在最远的块。那么,访问次数多的块是不会被选做牺牲者的,这一点Oracle是如何实现的?这很简单,Oracle一般以2次为准,块被访问2次以上了,它就有机会进入热端。
Oracle为内存中的每个块都添加了一个记录访问次数的标志位,假设图中每个块的访问次数如下:

如果现在又有新块要被读入Buffer cache,Oracle开始从冷端头寻找牺牲者,冷端头第一个块S,它的访问次数是2,那么,它不能被覆盖,只要访问次数大于等于2的块,Oracle会认为它可能会被经常访问到,Oracle要把它移到热端,它会选择R做为本次的牺牲者:
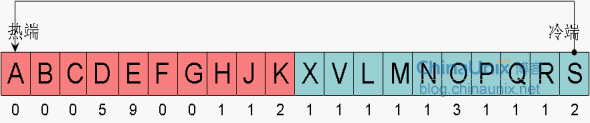
块S会被从冷端移到热端,并且它的访问次数会被清零。此时,块R就是牺牲者了,因为它的访问次数不到两次。

新块Y覆盖了块R,并被移到了冷端块开始处,它的访问次数是1。如果块Y再被访问了一次,它的访问次数变为了2:

虽然Y的访问次数达到了两次,但它不会马上被移到热端,它仍然留在原来的位置,随着不断有新块加入,被插入到它的前面,它会不断的被向后推移。

如上图,又加入了很多的新块,Y又被推到了冷端头,当再有新块进入Buffer cache时,Y不会是牺牲者,它会被移到热端头S的前面,Y后面的Z,它的访问次数没有达到2,它将会是牺牲者。
好了,这就是Oracle中Buffer cache管理LRU的原理。按照这种方式运作,Oracle可以把常用的块尽量长的保持在Buffer cache中。而且,每有新块进入Buffer cache,Oracle都会从冷端头处,从右向左搜索牺牲块。因为越靠近冷端,块的访问次数有可能越少、最后的访问时间离现在最远。
3 Oracle HASH Cluster
Oracle中没有普通的Hash索引,这个事情我们改变不了,但是我们可以出个变通方案,Oracle虽然没有Hash索引,但是他有Oracle HASH Cluster。
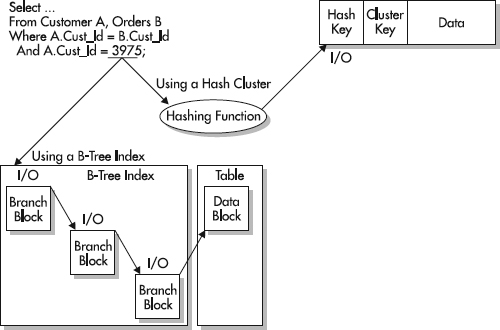
使用哈希索引需要使用hash clusters。创建集群或散列集群时,需要定义cluster key。cluster key告诉Oracle如何在群集中存储表。存储数据时,与cluster key钥相关的所有行都存储在相同的数据库块中,而不管它们属于哪个表。将数据存储在相同的数据库块中,使用哈希索引在WHERE子句中进行精确匹配,Oracle可以通过执行一个哈希函数和一个I / O来访问数据,而不是使用b访问数据-tree索引。
4 Oracle缓冲池
KeepBuffer Pool 的作用是缓存那些需要经常查询的对象但又容易被默认缓冲区置换出去的对象,按惯例,Keep pool设置为合理的大小,以使其中存储的对象不再age out,也就是查询这个对象的操作不会引起磁盘IO操作,可以极大地提高查询性能。
注意一点,不是设置了keep pool 之后,热点表就一定能够缓存在 keep pool ,keep pool 同样也是由LRU 链表管理的,当keep pool 不够的时候,最先缓存到 keep pool 的对象会被挤出,不过与default pool 中的 LRU 的管理方式不同,在keep pool 中表永远是从MRU 移动到LRU,不会由于你做了FTS(全表扫描)而将表缓存到LRU端,在keep pool中对象永远是先进先出。
因为这个原因,如果keep pool 空间比table 小,导致不能完全把table keep下,那么在keep pool 中最早使用的数据还是有可能被清洗出去的。还是会产生大量的逻辑读,这样就起不到作用,所以,如果采用keep,就必须全部keep下,要么就不用keep。
关于altertable cache, 全表扫描数据在正常情况下是放到LRU的冷端,使其尽快page out(这是default pool的默认策略), 而指定了alter table cache后,该表的全表扫描数据就不是放到LRU的冷端, 而是放到热端(MRU)了,从而使该得数据老化较慢,即保留的时间长.
但对于keep pool来说, 默认策略并不相同,所有数据总是放到热端的, 包括全表扫描数据。
5 使用
create cluster cluster_test (id number) hashkeys 1000 size 8192;
create table hashed_table(id number,data1 varchar2(4000),data2 varchar2(4000))cluster hash_cluster(id);
alter cluster cluster_test storage(buffer_pool keep);














 2044
2044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









