







介绍
我看了网上很多文章,MySQL的Double Write讲解的很清晰,但是Oracle处理这个问题的文章基本上没有讲解的特别明白清楚的,所以我详细讲解一下这部分内容,有问题欢迎指正。
Redo记录的是什么
要明白这个问题,首先就必须弄明白Redo记录的是什么,知道了Redo的格式才能明白为什么出现partial write的时候不能用Redo恢复,要不根本讲不清。
-
改变向量(change vector)
改变向量表示对数据库内某一个数据块所做的一次变更.改变向量(change vector)中包含了变更的数据块的版本号,事务操作代码,变更从属数据块的地址(DBA)以及更新后的数据.例如,一个update事务包含一系列的改变向量,对于数据块的修改是一个向量,对于回滚段的修改又是一处向量.
-
重做记录(redo record)
重做记录通常由一组改变向量组成,是一个改变向量的集合,代表一个数据库的变更(insert,update,delete等操作),构成数据库变更的最小恢复单位.例如,一个update的重做记录包括相应的回滚段的改变向量和相应的数据块的改变向量等.
假定发出了一个更新语句:
update A SET b = b+ 1;
看一下这个语句是怎么执行的
- 检查empno=7788记录在buffer cache中是否存在,如果不存在则读取到buffer cache中.
- 在回滚表空间的相应回滚段事务表上分配事务槽,这个操作需要记录redo信息.
- 从回滚段读入或者在buffer cache中创建sal=4000的前镜像,这需要产生redo信息并记入redo log buffer
- 修改sal=4000,这是update的数据变更,需要记入redo log buffer
- 当用户提交时,会在redo log buffer记录提交信息,并在回滚段标记该事务为非激活(Inactive)
下面我们演示一下如何查看Redo log内容
-
切换当前日志,主要目的是为了减小查看日志的内容,便于查看
alter system switch logfile; -
查看当前日志编号
select * from v$log; GROUP# THREAD# SEQUENCE# BYTES BLOCKSIZE MEMBERS ARCHIVED STATUS FIRST_CHANGE# FIRST_TIME NEXT_CHANGE# NEXT_TIME ---------- ---------- ---------- ---------- ---------- ---------- -------- ---------------- ------------- ----------- ------------ ----------- 1 1 29149 536870912 512 1 NO CURRENT 186309178371 2018/12/28 281474976710 2 1 29147 536870912 512 1 YES ACTIVE 186308063093 2018/12/28 186308463770 2018/12/28 3 1 29148 536870912 512 1 YES ACTIVE 186308463770 2018/12/28 186309178371 2018/12/28 -
更新并提交事务
update test set a = a + 1; commit; -
使用sys用户在另外的session转储日志文件
# 查找当前sessionid select userenv('sid') from dual; # 以下语句需要在同一个session中执行,并且在数据库本地以sys执行 alter system dump logfile '/app/oracle/oradata/dball/redo01.log '; select d.value || '/' || lower(rtrim(i.instance, chr(0))) || '_ora_' || p.spid || '.trc' trace_file_name from (select p.spid from sys.v_$mystat m, sys.v_$session s, sys.v_$process p where m.statistic# = 1 and s.sid = m.sid and p.addr = s.paddr) p, (select t.instance from sys.v_$thread t, sys.v_$parameter v where v.name = 'thread' and (v.value = 0 or t.thread# = to_number(v.value))) i, (select value from sys.v_$parameter where name = 'user_dump_dest') d /home/oracle/app/oracle/diag/rdbms/db1/db1/trace/db1_ora_9420.trc -
下载文件并查看
通过以下语句查询表的OBJECT_ID,然后在文件中搜索相关内容
select * from dba_objects where OBJECT_NAME = 'TEST'更新记录
REDO RECORD - Thread:1 RBA: 0x000bae.00000002.0010 LEN: 0x034c VLD: 0x0d SCN: 0x001c.649b62b0 SUBSCN: 1 07/02/2019 16:53:29 (LWN RBA: 0x000bae.00000002.0010 LEN: 0002 NST: 0001 SCN: 0x001c.649b62ae) CHANGE #1 TYP:2 CLS:1 AFN:72 DBA:0x121f44fb OBJ:113974 SCN:0x001c.649b627a SEQ:2 OP:11.19 ENC:0 RBL:0 KTB Redo op: 0x11 ver: 0x01 compat bit: 4 (post-11) padding: 1 op: F xid: 0x0002.01e.0000bcea uba: 0x00c00ec0.2380.03 Block cleanout record, scn: 0x001c.649b62af ver: 0x01 opt: 0x02, entries follow... itli: 2 flg: 2 scn: 0x001c.649b627a Array Update of 4 rows: tabn: 0 slot: 0(0x0) flag: 0x2c lock: 1 ckix: 0 ncol: 1 nnew: 1 size: 0 KDO Op code: 21 row dependencies Disabled xtype: XAxtype KDO_KDOM2 flags: 0x00000080 bdba: 0x121f44fb hdba: 0x121f44fa itli: 1 ispac: 0 maxfr: 4858 vect = 0 col 0: [ 2] c1 05 tabn: 0 slot: 1(0x1) flag: 0x2c lock: 1 ckix: 0 ncol: 1 nnew: 1 size: 0 KDO Op code: 21 row dependencies Disabled xtype: XAxtype KDO_KDOM2 flags: 0x00000080 bdba: 0x121f44fb hdba: 0x121f44fa itli: 1 ispac: 0 maxfr: 4858 vect = 0 col 0: [ 2] c1 06 tabn: 0 slot: 2(0x2) flag: 0x2c lock: 1 ckix: 0 ncol: 1 nnew: 1 size: 0 KDO Op code: 21 row dependencies Disabled xtype: XAxtype KDO_KDOM2 flags: 0x00000080 bdba: 0x121f44fb hdba: 0x121f44fa itli: 1 ispac: 0 maxfr: 4858 vect = 0 col 0: [ 2] c1 07 tabn: 0 slot: 3(0x3) flag: 0x2c lock: 1 ckix: 0 ncol: 1 nnew: 1 size: 0 KDO Op code: 21 row dependencies Disabled xtype: XAxtype KDO_KDOM2 flags: 0x00000080 bdba: 0x121f44fb hdba: 0x121f44fa itli: 1 ispac: 0 maxfr: 4858 vect = 0 col 0: [ 2] c1 08 CHANGE #2 TYP:0 CLS:19 AFN:3 DBA:0x00c00090 OBJ:4294967295 SCN:0x001c.649b6290 SEQ:1 OP:5.2 ENC:0 RBL:0 ktudh redo: slt: 0x001e sqn: 0x0000bcea flg: 0x0012 siz: 308 fbi: 0 uba: 0x00c00ec0.2380.03 pxid: 0x0000.000.00000000 CHANGE #3 TYP:0 CLS:19 AFN:3 DBA:0x00c00090 OBJ:4294967295 SCN:0x001c.649b62b0 SEQ:1 OP:5.4 ENC:0 RBL:0 ktucm redo: slt: 0x001e sqn: 0x0000bcea srt: 0 sta: 9 flg: 0x2 ktucf redo: uba: 0x00c00ec0.2380.03 ext: 15 spc: 7608 fbi: 0 CHANGE #4 TYP:0 CLS:20 AFN:3 DBA:0x00c00ec0 OBJ:4294967295 SCN:0x001c.649b628e SEQ:3 OP:5.1 ENC:0 RBL:0 ktudb redo: siz: 308 spc: 7918 flg: 0x0012 seq: 0x2380 rec: 0x03 xid: 0x0002.01e.0000bcea ktubl redo: slt: 30 rci: 0 opc: 11.1 [objn: 113974 objd: 113974 tsn: 7] Undo type: Regular undo Begin trans Last buffer split: No Temp Object: No Tablespace Undo: No 0x00000000 prev ctl uba: 0x00c00ec0.2380.01 prev ctl max cmt scn: 0x001c.649b5ec7 prev tx cmt scn: 0x001c.649b5ed1 txn start scn: 0x001c.649b626d logon user: 84 prev brb: 12586686 prev bcl: 0 BuExt idx: 0 flg2: 0 KDO undo record: KTB Redo op: 0x04 ver: 0x01 compat bit: 4 (post-11) padding: 1 op: L itl: xid: 0x000a.001.0001719b uba: 0x00c00321.312a.02 flg: C--- lkc: 0 scn: 0x001c.649b5334 Array Update of 4 rows: tabn: 0 slot: 0(0x0) flag: 0x2c lock: 0 ckix: 0 ncol: 1 nnew: 1 size: 0 KDO Op code: 21 row dependencies Disabled xtype: XAxtype KDO_KDOM2 flags: 0x00000080 bdba: 0x121f44fb hdba: 0x121f44fa itli: 1 ispac: 0 maxfr: 4858 vect = 0 col 0: [ 2] c1 04 tabn: 0 slot: 1(0x1) flag: 0x2c lock: 0 ckix: 0 ncol: 1 nnew: 1 size: 0 KDO Op code: 21 row dependencies Disabled xtype: XAxtype KDO_KDOM2 flags: 0x00000080 bdba: 0x121f44fb hdba: 0x121f44fa itli: 1 ispac: 0 maxfr: 4858 vect = 0 col 0: [ 2] c1 05 tabn: 0 slot: 2(0x2) flag: 0x2c lock: 0 ckix: 0 ncol: 1 nnew: 1 size: 0 KDO Op code: 21 row dependencies Disabled xtype: XAxtype KDO_KDOM2 flags: 0x00000080 bdba: 0x121f44fb hdba: 0x121f44fa itli: 1 ispac: 0 maxfr: 4858 vect = 0 col 0: [ 2] c1 06 tabn: 0 slot: 3(0x3) flag: 0x2c lock: 0 ckix: 0 ncol: 1 nnew: 1 size: 0 KDO Op code: 21 row dependencies Disabled xtype: XAxtype KDO_KDOM2 flags: 0x00000080 bdba: 0x121f44fb hdba: 0x121f44fa itli: 1 ispac: 0 maxfr: 4858 vect = 0 col 0: [ 2] c1 07以下是各个字段的意义
change #1 改变数 TYP:0 改变类型 CLS:1 参照X$BH class 1表示数据块 AFN:绝对数据文件号 DBA:更改数据块地址 OBJ: object id SCN:0x001c.638effe3 seq:2:序列号 OP:11.2 Insert Row Piece KTB REDO op: 01 F xid: 0x0006.01a.00000313 transaction ID uba: 0x00c002e7.28bc.2f 回滚段改变地址,序列号,块记录号 KDO: IRP(Insert Row Piece) row dependencies Disabled (默认创建表示非依赖,启动特性,ORA_ROWSCN伪列新特性) bdba:block address hdba:segment header address itli:事务slot 1 tabn: 0 表示非群集表 slot: 0(0x0) slot number size/delt: 19 块改变大小,增加19 bytes fb: --H-FL-- lb: 0x1 被锁住事务itil 1(与上面相符) cc: 3 插入列的数量然后看两行比数据,这两行表示了数据的变迁
col 0: [ 2] c1 04
col 0: [ 2] c1 05
col 0: [ 2] c1 06
col 0: [ 2] c1 07
和
col 0: [ 2] c1 05
col 0: [ 2] c1 06
col 0: [ 2] c1 07
col 0: [ 2] c1 08
由于我定义的字段类型是varcha2,所以可以通过如下SQL查询
select utl_raw.cast_to_varchar2('31') from dual;
select utl_raw.cast_to_varchar2('33') from dual;
可以看出来值由1变成了3
日志种类的区别
- 逻辑日志:简单理解记录的是sql语句
- 物理日志:记录的是4元组数据,哪个表空间,哪个文件,哪个页,哪个偏移位置,插入的字节内容
- 逻辑物理日志:页面内的操作记录的是逻辑日志,页间的操作记录的是物理日志,physical to a page,logical within a page
在MySQL中有一句这样的话,binlog是逻辑日志,redo log是逻辑物理日志,因为不是纯物理日志,所以partial page时需要Double Write介入才能恢复数据。然后引入了Double Write,然后就引入了上面的问题,为什么Oracle在不需要呢,网上大部分文章讲解的都不是很详细。
逻辑物理日志的意义
咱们先来看为什么redo log是逻辑物理日志,由于上面我已经详细列举了Redo保存的内容,所以我直接说,AFN(绝对数据文件号)和DBA(更改数据块地址)这两个地址可以看出来他确实包含了部分物理地址信息,但是OBJ(object id)和col 0: [ 1] 31这类的说明,是逻辑层的东西,明显不是物理地址,所以redo log是逻辑物理日志。
Double Write
那我先简单描述一下MySQL的double write,下面这部分内容截取自网上。
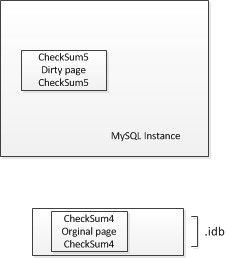
更新数据后,会将dirty page放到innodb buffer cache中。此时页的checksum值会发生变化。页的头部fileheader部分有checksum项,名为file_page_space_or_checksum。页的尾部filetailer部分也有用来比较checksum的项,名为file_page_end_lsn。它们使用特殊的checksum函数来比较,以此来验证页的完整性。这里我们简单的理解为等值比较。
[外链图片转存失败(img-MzqoFGc8-1562053595111)(https://raw.githubusercontent.com/ciqingloveless/doublewirte/master/20181223163801.jpg)]
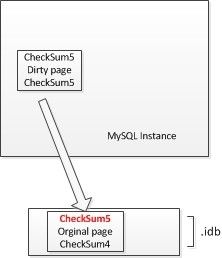
这个时候执行刷新磁盘操作,16KB的页,如果只写了其中的8KB,这时候发生了意外状况,服务器掉电、MySQL示例突然停掉。这时候就会发生partial page write的问题,即只有页的部分数据同步到了磁盘上面。checksum无法通过。
[外链图片转存失败(img-pwBh5ps4-1562053595111)(https://raw.githubusercontent.com/ciqingloveless/doublewirte/master/20181223163802.jpg)]
其实MySQL的Innodb以及Oracle数据库的redo log,不是记录纯物理的操作,而是物理和逻辑结合的日志。(这样可以减少redo的生成)
物理到page,也就是page具体在硬盘上的具体位置。后面对于page的操作,则是根据自己的格式逻辑存储的(应用的时候需要通过特定的解析函数),比如说向page里面插入一条记录。当然Oracle数据库也是类似的,物理,只到block级别。所以说,当page 损坏之后,其实应用redo是没有意义的。这时候无法使用redo来恢复,因为原始页已经损坏了.会发生数据丢失。
大部分文章讲到这里就结束了,所以我一直比较困惑,为什么page页损坏了就不能应用Redo了,然后我查了一下Redo信息,按照我的理解说一下,假如不对可以在评论里回复。
为什么page坏了就不能用Redo了呢,咱们考虑一个问题,假如我写完了两个块,另两个块没写,在恢复的时候需要对写完的两个块也进行重写,那就会有个问题,由于是逻辑日志,所以操作不一定是幂等的,对于MLOG_PAGE_REORGANIZE类型的重做日志其是幂等的,但是对于INSERT产生的日志其不是幂等的,因为INSERT重做日志记录的不是插入的记录,而是待插入记录的前一条记录的位置,以及与该记录的二进制diff信息(这样做是为了进行压缩,从而使得重做日志更小)。mysql在恢复的时候是通过检查page的checksum来决定这个page是否需要恢复的, checksum就是当前这个page最后一个事务的事务号,如果系统找不到checksum, mysql也就无法对这行数据执行写入操作,那么这个时候数据就错误了,所以没办法应用Redo了。这句话的意思就是,利用Redo恢复,首先要找到当前Page页所完成的最后一个事务,然后将当前事务编号之后的事务重新执行一遍,但是由于出现问题,所以结尾部分的事务编号丢失了,而由于MySQL是写入是16K,所以不知道写到哪个事务块中,所以MySQL引入了Double Write。这部分没什么问题。
为什么Redo不需要处理Double Write问题
这个也得提前说一下,否则后面也会有疑问,这个得从磁盘说起,以前的老磁盘最小写入单位是512,而Redo的大小就是512,所以Redo写入不是成功就是失败,不会产生文件split,而现代磁盘写入的最小单位已经是4K(需要操作系统支持),在写Redo的时候是先将整个4K区域读入到内存,修改之后再整体复写到内存,所以也只能是成功或者失败,所以不存在page损坏问题。
Oracle为什么不需要Double Write
毫无疑问,Oracle中也是存在这种情况的,不过情况会有一些差别,处理方式不同。这点先强调一下,这个确实是存在的,因为有的文章说Oracle不存在,所以特别强调一下。
Oracle不需要Double Write需要分几部分说:
- Oracle中的DBWR写数据
- 热备的写数据
- Rman写数据
Oracle里面有一种备份方式是热备份(hot backup),就是在数据库open状态可以直接拷贝数据文件做备份,备份开始使用begin backup声明,备份结束使用end backup结束。这个过程中很可能出现拷贝的文件发生数据变化,导致不一致的情况,被称为split block。这一类数据块也叫fractured block,在官方文档11g中是这么解释的,而在10g的官方文档描述是错误的。
fractured block
简单来说就是在数据块头部和尾部的SCN不一致导致。在用户管理方式的备份中,操作系统工具(比如cp命令)在DBWR正在更新文件的同时备份数据文件。
操作系统工具可能以一种半更新的状态读取块,结果上半部分更新复制到了备份介质的块,而下半部分仍包含较旧的数据。在这种情况下,这个块就是断裂的。
对于非RMAN备份的方式,ALTER TABLESPACE … BEGIN BACKUP或ALTER DATABASE BEGIN BACKUP命令是断裂块问题的解决方案。当表空间处于热备模式,并且对数据块进行更改时,数据库将在更改之前记录整个块镜像的副本,以便数据库可以在介质恢复发现该块被破坏时重建该块。
当表空间处于热备模式,并且每次对数据块进行更改时,数据库将在更改之前记录整个块镜像的副本,以便数据库可以在介质恢复发现该块被破坏时重建该块。
Jonathan Lewis这位大师对此做了进一步的阐释,把话说得更明确了。
简单翻译一下就是:
官方文档如果这么说就错了,在检查点完成之后,将块加载到缓存之后的第一次变更(或者缓存中任意块的第一次更改),当前版本的块信息会全量写入redo,而数据块在缓冲区中后续的变更不会重复写。
文档描述问题在10g文档存在,在11g中做了修正。而实际应用中使用cp命令进行拷贝是因为写入磁盘的是操作会使用文件系统块大小作为最小IO,但是RMAN写入磁盘的时候使用Oracle block size作为最小IO,所以不会出现split block。
为此我们来提一提Oracle中的数据块。Oracle中block的大小大体有这几类,分别是数据块、重做日志数据块和控制文件数据块。
所以上面后两种问题解决了,我这里详细讲解一下。
我们说double write解决的是一次写入的时候数据库的块与系统块不匹配发生的,就是数据库的块未完全写入系统块,所以有两种方案保证这个情况不会发生,第一种就是由数据库层进程保证,不管数据库的块多大,多要求他进行原子操作,就是一个坏了整体回退重写,另一种就是保证数据库的块比系统块小。
我在解释一下第二种,第二种的意思就是Redo每次写入的是512,而老硬盘也是512,所以每次写入不是成功就是失败,不存在割裂问题。而现代硬盘最小写入是4K(需操作系统支持),那么每写入512,都是先将系统的整个4K数据读入到内存然后修改,然后4K内存一起写入到硬盘,所以也不会有页断裂。
Rman是第一种,热备是第二种,所以现在就剩下第一种了。
Oracle可以很自信地确认,如果数据做了commit而且成功返回,那么下一秒断电后数据是肯定能恢复的。这个是结论,下面是相关原理。
Oracle如何通过redo进行恢复
我们假设redo写的时候也是存在问题,即partial write。
在MySQL中有这样的一个梗:因为page已经损坏,所以就无法定位到page中的事务号,所以这个时候redo就无法直接恢复。
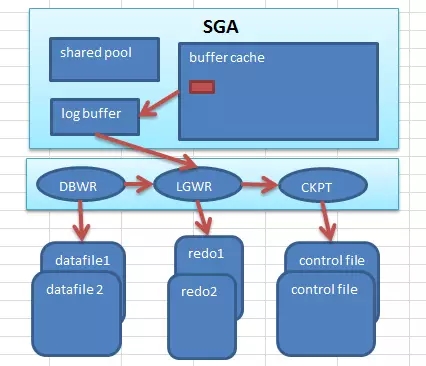
Oracle怎么做呢?看看下面的图,其实细看有一个文件很有意思,那就是控制文件。Oracle是有控制文件来做数据的检查点,对控制文件描述得更形象一些,它就是数据库的大脑,由此可见它的地位,尽管它的功能相对会比较单一,但是很重要。
[外链图片转存失败(img-Q8UntmxU-1562053595112)(https://raw.githubusercontent.com/ciqingloveless/doublewirte/master/20181223163803.jpg)]
用户提交数据的变更之后,在Oracle写入到数据文件中,这是一个异步的过程,但是同时从数据安全性方面又需要保证数据不会丢失,在数据变更后会在redo log buffer中构造重做数据条目(redo entry),描述了修改前和修改后的数据变化。Lgwr会把重做条目刷入redo日志,当然这个过程还要细分一下,分为后台写和同步写。
后台写的触发条件会多一些,比如3秒的间隔;或者数据还没有刷新到redo日志时,DBWR会触发LGWR去写,直至写完;或者是达到日志缓冲区1/3时触发LGWR;或者是达到1M时触发,还有其它更多的细节,可以移步官方文档看看。
同步写的触发条件相对简单,就是用户commit时触发LGWR去写,所以说如果出现over commit的情况时,总是会有很明显的log file sync的等待事件。
这个过程和CKPT有什么关系呢?简单来说,Oracle不断地定位这个起点,这样在不可预期的实例崩溃中能够有效地保护并恢复数据,这也是CKPT的使命所在。这个起点如果太靠近日志文件头部就意味着要处理很多redo条目,恢复效率会很差;其次,这个起点不能太靠近日志文件尾部,太靠近日志文件尾部则说明只有很少的脏数据块没有写入数据,也就需要DBWR频繁去刷数据。所以Oracle中会存在检查点队列的概念,就是一个LRU链表,上面都是数据块头(buffer header),同时如果一个数据块被修改了多次的话,在该链表上也只出现一次,和Jonathan Lewis的解读如出一辙。
而在MySQL中也是LRU的方式,控制方式更加清晰,可以通过参数innodb_lru_scan_depth控制LRU列表中可用页数量,通过参数innodb_max_dirty_pages_pact来控制刷脏页的频率(默认是75,谷歌的压测推荐是80)。
小结一下:就是CKPT是一个关键,会有检查点队列和增量检查点来提高数据恢复的效率和减少DBWR频繁刷盘。而这个所谓检查点不光在redo、数据文件、数据文件头,关键的是控制文件中也还会持续跟踪记录。这个就是我们数据恢复的基石SCN,在MySQL里面叫做LSN。
以上是一篇博文的内容,连接地址如下:
https://yq.aliyun.com/articles/80423
但是我看完并不是太明白,所以我下面按照我的理解说一下。
下面介绍一下几个概念
-
RBA(Redo Byte Address), Low RBA(LRBA), High RBA(HRBA)
RBA就是重做日志块(redo log block)的地址,相当与数据文件中的ROWID,通过这个地址来定位重做日志块。RBA由三个部分组成:
日志文件序列号(4字节)
日志文件块编号(4字节)
重做日志记录在日志块中的起始偏移字节数(2字节)
通常使用RBA的形式有:
-
LRBA
数据缓存(buffer cache)中一个脏块第一次被更新的时候产生的重做日志记录在重做日志文件中所对应的位置就称为LRBA。
-
HRBA
数据缓存(buffer cache)中一个脏块最近一次被更新的时候产生的重做日志记录在重做日志文件中所对应的位置就称为HRBA。
-
checkpoint RBA
当一个checkpoint事件发生的时候,checkpoint进程会记录下当时所写的重做日志块的地址即RBA,此时记录的RBA被称为checkpoint RBA。从上一个checkpoint RBA到当前的checkpoint RBA之间的日志所保护的buffer cache中的脏块接下来将会被写入到数据文件当中去。
-
topBuffer checkpoint Queues (BCQ)
Oracle将所有在数据缓存中被修改的脏块按照LRBA顺序的组成一个checkpoint队列,这个队列主要记录了buffer cache第一次发生变化的时间顺序,然后有DBWn进程根据checkpoint队列顺序将脏块写入到数据文件中,这样保证了先发生变更的buffer能先被写入到数据文件中。BCQ的引入是为了支持增量checkpoint的。
topActive checkpoint Queue (ACQ)ACQ中包含了所有活动的checkpoint请求。每次有新checkpoint请求是都会在ACQ中增加一条记录,ACQ记录中包含了相应的checkpoint RBA。checkpoint完成以后相应的记录将被移出队列。
所以数据恢复时,从控制文件中发现数据文件的检查点为空(这个就解决了MySQL不知道当前Page事务号的问题,同时也是为什么MySQL有LSN同时也必须要有Double Write的原因,因为Oracle是在服务层处理,可以获取事务ID,而InnoDB是在存储层,获取不到当前事务ID),意味着这是异常宕机,就会启动crash recovery。这个检查点在控制文件中会抓取到最近的SCN,然后就是应用redo,达到一个奔溃前的状态,就是常说的前滚,然后为了保证事务一致性,回滚那些未提交的事务,所以控制文件的设计就很有意义。以上就是一个较为粗略的恢复过程。
CKPT进程(检查点进程):用来减少执行实例恢复所需的时间,检查点使DBWR将自上一个检查点之后的全部已修改的数据块写入数据文件,并更新数据文件头和控制文件以记录该检查点.当一个联机重做日志文件被填满时,检查点进程会自动出现,可以使用实例的初始化参数文件中的 LOG_CHECKPOINT_INTERVAL 参数设置让一个更频繁的检查点出现。
这里SCN与恢复的关系大概是如下
//在数据库正常运行期间,Stop SCN(通过视图v$datafile的字段last_change#可以查询)是一个无穷大的数字或者说是NULL。
if (数据文件检查点SCN <数据文件头SCN)
then "控制文件来自备份,需要进行不完全恢复,恢复之后得用resetlog方式打开”
else if (数据文件检查点SCN > 数据文件头SCN)
then “数据文件来自备份,需要log进行完全或不完全恢复”
else if (数据文件检查点SCN = 数据文件头SCN)
then “数据库能正常open,还需要判断是否需要实例恢复”
if (数据文件终止SCN = 数据文件检查点SCN)
then "数据库打开时不需要实例恢复“
else if (数据文件终止SCN = NULL)
then “数据库需要实例恢复”
所以说当数据库异常宕机启动的时候终止SCN为NULL就需要Redo恢复。
而恢复的过程就是上面的checkpoint,他会检查当前控制文件中各个数据文件的SCN号,上面的数据文件的SCN号,然后根据控制文件的SCN读取Redo中那个SCN号之后的日志,由于Redo上面包含数据原值,然后推进Redo就可以进行恢复。
这个就是为什么Oracle不需要Double Write的原因。
而为什么MySQL也有LSN确必须有Double Write呢,问题的本质,那就是这些都是InnoDB层面去做的检查点,所以就会出现我们开始所说的情况。因为page已经损坏,所以就无法定位到page中的事务号,所以这个时候redo就无法直接恢复。而Oracle有控制文件这一层级,数据恢复都是在mount状态下,挂载控制文件后开始的。















 960
960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}