







使用encoding/xml 对内容进行xml生成的时候,遇到2个问题
一个是 给中文添加 CDATA 标签 另外一个就是 添加完cdata后,有些特殊的ascii字符导致xml解析失败的问题
CDATA的方法通过使用innerxml的tag标签可以解决,方案
给chardata结构给定一个innerxml的tag
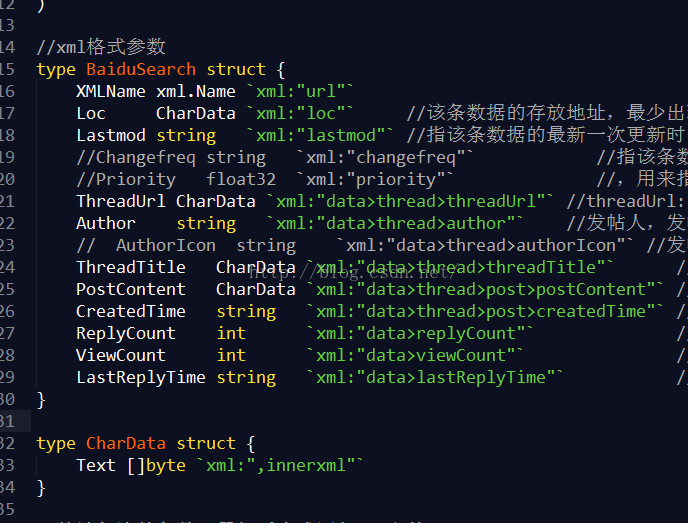
xml结构体的chardata结构,里设置了innerxml tag, 表示不作任何处理,进行数据直接展示,
然后写个func 给字符串增加上CDATA 就可以了
func NewCharData(s string) CharData {
// s = url.QueryEscape(s)
return CharData{[]byte("<![CDATA[" + s + "]]>")}
}
<img src="https://img-blog.csdn.net/20160127235550827?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQv/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center" alt="" style="font-family: Arial, Helvetica, sans-serif; background-color: rgb(255, 255, 255);" />如图, 上面的 us so 这种内容,导致解析xml报错, 因为是ascii字符集里 ,有几个范围的内容,不被xml确认 ,所以需要把这堆内容通过正则匹配删除掉,
其实下午就在用正则匹配,但是死活不好用。。回家以后写了个测试,然后竟然又好用了,无言了 。代码贴出来明天去公司再试试
import (
"fmt"
"regexp"
//"strconv"
)
re, _ := regexp.Compile("[\x00\x01\x02\x03\x04\x05\x06\x07\x08\x0b\x0c\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f]")
src = re.ReplaceAllString(src, "")















 9600
9600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









