







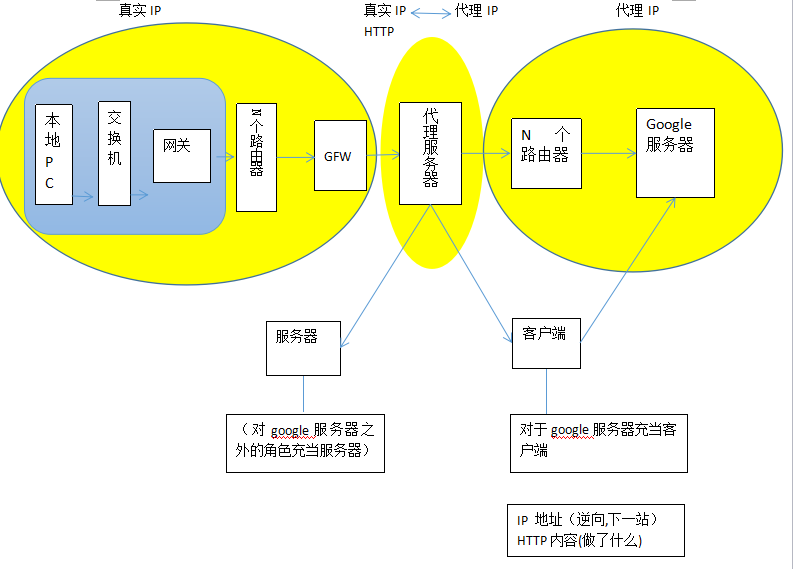
关于匿名详解的第一步,简单的翻墙模型
1.看图简单明了,知道每一步IP以及HTTP的流向
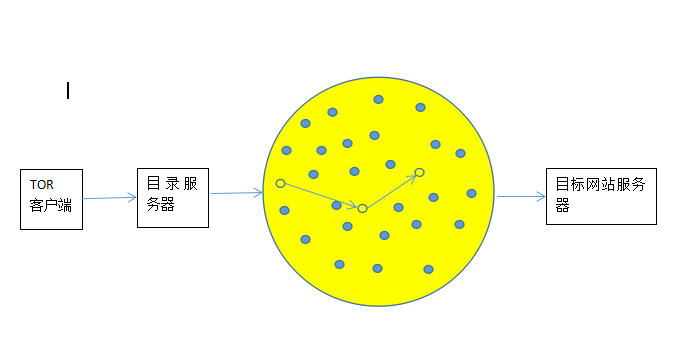
2.简单的TOR通信模型
TOR客户端先与目录服务器通信
获得全球节点信息,然后再随机选择三个节点(HOP)组成电路
之后到达目标网站服务器
3.预设参数模型。
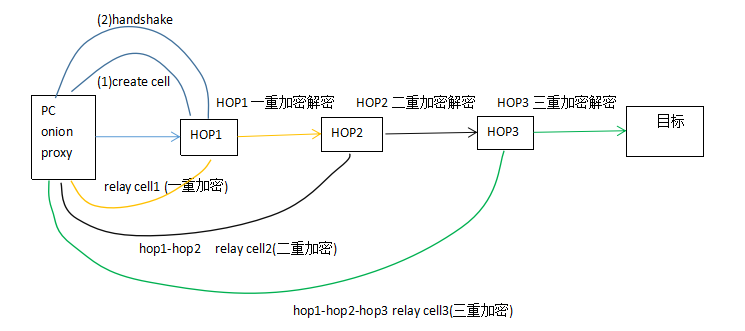
每个cell相当于与一个参数,是当前节点与下一跳节点建立连接关系的所需要的参数.
Relay cell1 被一重加密,到了入口节点后就被解密,再用来与中间节点完成握手;
Relay cell2 被两重加密,到了入口节点时第一重加密解除,到了中间节点时第二重加密解除,中间节点鞥看到明文,被用来与出口节点完成握手;
Relay cell3 被三重加密,同理,只有出口节点能看到明文(HTTP)。
这一过程中,只有入口节点知道用户的真实IP地址,出口节点知道用户的目的地和传输内容(HTTP),TOR电路的cell里没有其他任何关于任何用户真实身份的信息。
TOR 使用的是在传输层之上应用层之下的SOCKS代理,无法操纵修改上层协议。
既是预设那么就无法做到随机了,且密钥泄露也很危险。
4.半握手模型(diffie-hellman算法)
在diffie-hellman算法的帮助之下,onion proxy 和中间节点通过入口节点的中介交换了参数,然后各自算出私钥用于后续通信而不用担心被监听。入口节点虽然知道这两个参数,但也没有办法算出私钥来。
同理,也可以与出口节点安全通信,客户端最里面一层的加密只有出口节点才能解开,入口节点及中间节点都看不到只有出口节点才能看到的内容。
TOR 还有一个特性:将很多用户的流量整合到一个TLS连接里同时传输。看起来就像一个用户一样。同一个IP的大量流量同时指向一个网站,类似DDOS,会触发网站防御机制,输入验证码。
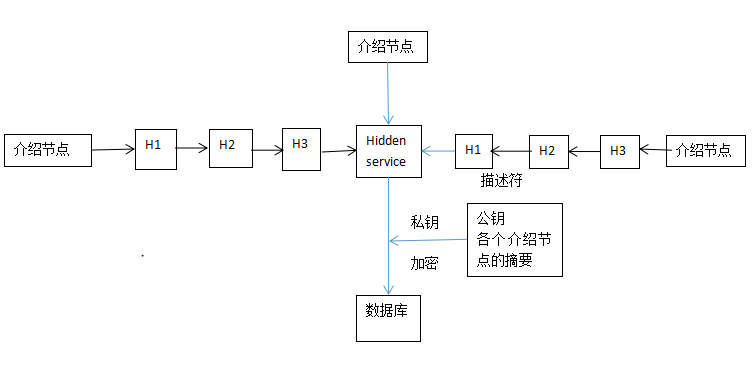
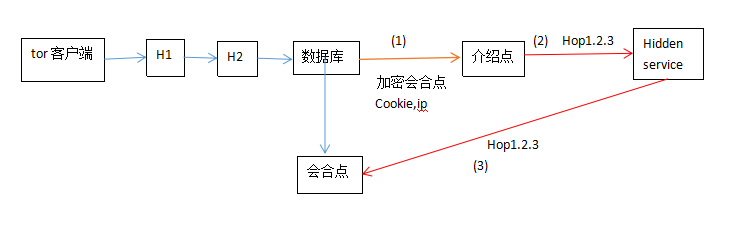
5.deep web 模型
建站模型
















 49
49

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









