







目录
4、秃顶面试官:的确如此,能详细说下这几个哨兵独有配置的意思吗?
5、秃顶面试官:咳,说的非常好,那给我细说下哨兵故障转移的过程以及原理吧
6、秃顶面试官:niubility,讲的非常详细,我这里有一个故障转移的日志,你帮我分析下吧
面试官:说说Redis的持久化以及主从同步呗_cj_eryue的博客-CSDN博客
面试官:前面我们聊了主从和哨兵,那今天来聊一聊集群吧_cj_eryue的博客-CSDN博客
前言:本文redis基于6.2.4
1、秃顶面试官:Redis的哨兵模式知道吗,说一说呢
花花:啊,这我熟悉啊,说到哨兵,那不得不提到redis的主从模式啊,Redis的主从复制模式下,一旦主节点由于故障不能提供服务,需要人工将从节点晋升为主节点,同时还要通知应用方更新主节点地址,对于很多应用场景这种故障处理的方式是无法接受的,因此Redis从2.8开始正式提供了Redis Sentinel(哨兵)架构来解决这个问题。
2、秃顶面试官:嗯,不错,那哨兵模式到底是个什么呢?
花花:哨兵模式就是主从模式+一些哨兵节点,哨兵节点本身就是独立的Redis节点,只不过它们有一些特殊,它们不存储数据,只支持部分命令。
秃顶面试官:嗯,行,那哨兵节点在哨兵模式下的职责是什么呢?
花花:
- 监控功能:Sentinel节点会定期检测Redis的数据节点以及其余Sentinel节点是否可达。
- 通知功能:Sentinel节点会将故障转移的结果通知给应用方。
- 主节点故障转移:实现从节点晋升为主节点并维护后续正确的主从关系。
- 配置提供者:客户端在初始化的时候连接的是Sentinel节点集合,从中获取主节点信息。
3、秃顶面试官:不错不错~,搭建过哨兵模式吗,说说呢?
花花:那必须的啊,搭建哨兵模式非常的easy,比如我现在要搭建一个一主三从三哨兵的哨兵模式,那就先启一个主,两个从(这里不做赘述),接着再配置下哨兵节点,主要配置如下:
sentinel-16379.conf
# 基本配置,同主从节点一样
port 16379
daemonize yes
logfile "sentinel1.log"
dir "./"
sentinel monitor mymaster 127.0.0.1 6379 2
# sentinel auth-pass mymaster 111111
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
# sentinel notification-script <master-name> <script-path>
# sentinel client-reconfig-script <master-name> <script-path>这样的配置复制两份,修改下port和logfile,接着我们来依次启动哨兵节点即可
方法一,使用redis-sentinel命令:
./redis-sentinel sentinel-16379.conf
方法二,使用redis-server命令加--sentinel参数
redis-server sentinel-16379.conf --sentinel
是不是非常的简单那~,可以连接上任意哨兵节点执行info sentinel命令查看哨兵监控的信息
[root@localhost sentinel]# ../bin/redis-cli -h 127.0.0.1 -p 16379
127.0.0.1:16379> info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:6381,slaves=2,sentinels=34、秃顶面试官:的确如此,能详细说下这几个哨兵独有配置的意思吗?
花花:阔以的阔以的啊(花花:你不问我也要说的啊Q.Q)
①sentinel monitor mymaster 127.0.0.1 6379 2
代表本哨兵节点需要监控127.0.0.1:6379这个主节点,2(<quorum>)代表判断主节点失败至少需要2个哨兵节点同意,mymaster是主节点的别名;同时<quorum>还与Sentinel节点的领导者选举有关,至少要有max(quorum,num(sentinels)/2+1)个Sentinel节点参与选举,才能选出领导者Sentinel,从而完成故障转移。例如有5个Sentinel节点,quorum=4,那么至少要有
max(4,5/2+1)=4个在线Sentinel节点才可以进行领导者选举。
②sentinel down-after-milliseconds mymaster 30000
每个Sentinel节点都要通过定期发送ping命令来判断Redis数据节点和其余Sentinel节点是否可达,如果超过了down-after-milliseconds配置的时间且没有有效的回复,则判定节点不可达,<times>(单位为毫秒)就是超时时间。这个配置是对节点失败判定的重要依据。
注意:down-after-milliseconds虽然以<master-name>为参数,但实际上对Sentinel节点、主节点、从节点的失败判定同时有效。
③sentinel parallel-syncs mymaster 1
当Sentinel节点集合对主节点故障判定达成一致时,Sentinel领导者节点会做故障转移操作,选出新的主节点,原来的从节点会向新的主节点发起复制操作,parallel-syncs就是用来限制在一次故障转移之后,每次向新的主节点发起复制操作的从节点个数。如果这个参数配置的比较大,那么多个从节点会向新的主节点同时发起复制操作,尽管复制操作通常不会阻塞主节点,但是同时向主节点发起复制,必然会对主节点所在的机器造成一定的网络和磁盘IO开销。
④sentinel failover-timeout mymaster 180000
failover-timeout通常被解释成故障转移超时时间,但实际上它作用于故障转移的各个阶段:
a)选出合适从节点。
b)晋升选出的从节点为主节点。
c)命令其余从节点复制新的主节点。
d)等待原主节点恢复后命令它去复制新的主节点
failover-timeout的作用具体体现在四个方面:
1)如果Redis Sentinel对一个主节点故障转移失败,那么下次再对该主节点做故障转移的起始时间是failover-timeout的2倍。
2)在b)阶段时,如果Sentinel节点向a)阶段选出来的从节点执行slaveof-noone一直失败(例如该从节点此时出现故障),当此过程超过failover-timeout时,则故障转移失败。
3)在b)阶段如果执行成功,Sentinel节点还会执行info命令来确认a)阶段选出来的节点确实晋升为主节点,如果此过程执行时间超过failover-timeout时,则故障转移失败。
4)如果c)阶段执行时间超过了failover-timeout(不包含复制时间),则故障转移失败。注意即使超过了这个时间,Sentinel节点最后也会配置从节点去同步最新的主节点。
⑤ sentinel auth-pass mymaster 111111
不用解释了吧
⑥ sentinel notification-script <master-name> <script-path>
sentinel notification-script的作用是在故障转移期间,当一些警告级别的Sentinel事件发生(指重要事件,例如-sdown:客观下线、-odown:主观下线)时,会触发对应路径的脚本,并向脚本发送相应的事件参数。
⑦sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script的作用是在故障转移结束后,会触发对应路径的脚本,并向脚本发送故障转移结果的相关参数。和notification-script类似,该脚本会接收每个Sentinel节点传过来的故障转移结果参数,并触发类似短信和邮件报警。
___________________________________________________________________________
(秃顶面试官:这小子有点东西啊,让我再问问)
5、秃顶面试官:咳,说的非常好,那给我细说下哨兵故障转移的过程以及原理吧
(花花:这不小菜,看我怎么拿捏你)
花花:这个稍微有那么一丢丢复杂了啊,容我慢慢道来
三个定时监控任务
首先,Redis Sentinel通过三个定时监控任务完成对各个节点发现和监控:
1)每隔10秒,每个Sentinel节点会向主节点和从节点发送info命令获取最新的拓扑结构
如下为主节点上执行info replication的信息,就可以找到相应的从节点
127.0.0.1:6381> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=772979,lag=1
slave1:ip=127.0.0.1,port=6379,state=online,offset=772993,lag=1这个定时任务的作用具体可以表现在三个方面:
- 通过向主节点执行info命令,获取从节点的信息,这也是为什么Sentinel节点不需要显式配置监控从节点。
- 当有新的从节点加入时都可以立刻感知出来。
- 节点不可达或者故障转移后,可以通过info命令实时更新节点拓扑信息。
2)每隔2秒,每个Sentinel节点会向Redis数据节点的__sentinel__:hello频道上发送该Sentinel节点对于主节点的判断以及当前Sentinel节点的信息(如图9-27所示),同时每个Sentinel节点也会订阅该频道,来了解其他Sentinel节点以及它们对主节点的判断,所以这个定时任务可以完成以下两个工作:
- 发现新的Sentinel节点:通过订阅主节点的__sentinel__:hello了解其他的Sentinel节点信息,如果是新加入的Sentinel节点,将该Sentinel节点信息保存起来,并与该Sentinel节点创建连接。
- Sentinel节点之间交换主节点的状态,作为后面客观下线以及领导者选举的依据。
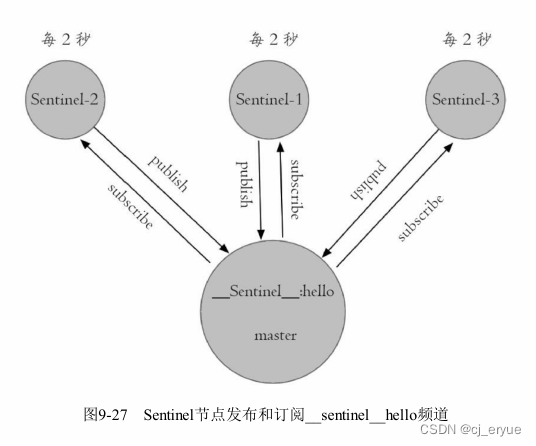
Sentinel节点publish的消息格式如下:
<Sentinel 节点 IP> <Sentinel 节点端口 > <Sentinel 节点 runId> <Sentinel 节点配置版本 >
< 主节点名字 > < 主节点 Ip> < 主节点端口 > < 主节点配置版本 >
3)每隔1秒,每个Sentinel节点会向主节点、从节点、其余Sentinel节点发送一条ping命令做一次心跳检测,来确认这些节点当前是否可达。如图9-28所示。通过上面的定时任务,Sentinel节点对主节点、从节点、其余Sentinel节点都建立起连接,实现了对每个节点的监控,这个定时任务是节点失败判定的重要依据。

主观下线和客观下线
上面3)的定时任务每个Sentinel节点会每隔1秒对主节点、从节点、其他Sentinel节点发送ping命令做心跳检测,当这些节点超过down-after-milliseconds没有进行有效回复,Sentinel节点就会对该节点做失败判定,这个行为叫做主观下线。从字面意思也可以很容易看出主观下线是当前Sentinel节点的一家之言,存在误判的可能,如下图所示

客观下线
当Sentinel主观下线的节点是主节点时,该Sentinel节点会通过sentinel is-master-down-by-addr命令向其他Sentinel节点询问对主节点的判断,当超过<quorum>个数,Sentinel节点认为主节点确实有问题,这时该Sentinel节点会做出客观下线的决定,这样客观下线的含义是比较明显了,也就是大部分Sentinel节点都对主节点的下线做了同意的判定,那么这个判定就是客观的,如下图所示

领导者Sentinel节点选举
当Sentinel节点对于主节点已经做了客观下线,Sentinel节点之间会做一个领导者选举的工作,选出一个Sentinel节点作为领导者进行故障转移的工作。Redis使用了Raft算法实现领导者选举,因为Raft算法相对比较抽象和复杂,以及篇幅所限,所以这里给出一个Redis Sentinel进行领导者选举的大致思路:
1)每个在线的Sentinel节点都有资格成为领导者,当它确认主节点主观下线时候,会向其他Sentinel节点发送sentinel is-master-down-by-addr命令,要求将自己设置为领导者。
2)收到命令的Sentinel节点,如果没有同意过其他Sentinel节点的sentinel is-master-down-by-addr命令,将同意该请求,否则拒绝。
3)如果该Sentinel节点发现自己的票数已经大于等于max(quorum,num(sentinels)/2+1),那么它将成为领导者。
4)如果此过程没有选举出领导者,将进入下一次选举。
故障转移
领导者选举出的Sentinel节点负责故障转移,具体步骤如下:
1)在从节点列表中选出一个节点作为新的主节点,选择方法如下:
a)过滤:“不健康”(主观下线、断线)、5秒内没有回复过Sentinel节点的ping响应、与主节点失联超过down-after-milliseconds*10秒。
b)选择slave-priority(从节点优先级)最高的从节点列表,如果存在则返回,不存在则续。
c)选择复制偏移量最大的从节点(复制的最完整),如果存在则返回,不存在则继续。
d)选择runid最小的从节点。
2)Sentinel领导者节点会对第一步选出来的从节点执行slaveof no one命令让其成为主节点。
3)Sentinel领导者节点会向剩余的从节点发送命令,让它们成为新主节点的从节点,复制规则和parallel-syncs参数有关。
4)Sentinel节点集合会将原来的主节点更新为从节点,并保持着对其关注,当其恢复后命令它去复制新的主节点。
6、秃顶面试官:niubility,讲的非常详细,我这里有一个故障转移的日志,你帮我分析下吧
花花:行,我给你注释下
10378:X 10 Jul 2023 14:07:41.182 # +monitor master mymaster 127.0.0.1 6379 quorum 2
// +sdown:主观down机
10378:X 10 Jul 2023 14:09:34.718 # +sdown master mymaster 127.0.0.1 6379
// +odown:客观down机
10378:X 10 Jul 2023 14:09:34.810 # +odown master mymaster 127.0.0.1 6379 #quorum 2/2
// +new-epoch:集群递增版本号
10378:X 10 Jul 2023 14:09:34.810 # +new-epoch 1
// +try-failover:开始对某ip进行故障转移
10378:X 10 Jul 2023 14:09:34.810 # +try-failover master mymaster 127.0.0.1 6379
// voted for:进行leader投票
10378:X 10 Jul 2023 14:09:34.814 # +vote-for-leader 7fb650c142d0b66520488fc57162ac8451fa5c5a 1
10378:X 10 Jul 2023 14:09:34.824 # bd8c5e8abe740f8664bb3b2aac7b3427883aa925 voted for 7fb650c142d0b66520488fc57162ac8451fa5c5a 1
10378:X 10 Jul 2023 14:09:34.825 # 5471c6df43471c5d912809b4285b51e431796425 voted for 7fb650c142d0b66520488fc57162ac8451fa5c5a 1
// +elected-leader:再次确认进行即将执行故障转移的leader是哪一个哨兵
10378:X 10 Jul 2023 14:09:34.905 # +elected-leader master mymaster 127.0.0.1 6379
10378:X 10 Jul 2023 14:09:34.905 # +failover-state-select-slave master mymaster 127.0.0.1 6379
// +selected-slave slave:选出一个从来升级为主
10378:X 10 Jul 2023 14:09:34.989 # +selected-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
// +failover-state-send-slaveof-noone slaveLeader:向目标slave发送"slaveof-noone"指令,令其不要再做其它任何节点的slave了,从现在开始,它就是老大,完成从slave到master的转换
10378:X 10 Jul 2023 14:09:34.989 * +failover-state-send-slaveof-noone slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
// +failover-state-wait-promotion slave:等待其它的sentinel确认slave
10378:X 10 Jul 2023 14:09:35.074 * +failover-state-wait-promotion slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
// +promoted-slave slave:其它的sentinel全部确认成功
10378:X 10 Jul 2023 14:09:35.464 # +promoted-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
// +failover-state-reconf-slaves:开始对所有slave做reconf操作(更新配置信息)
10378:X 10 Jul 2023 14:09:35.464 # +failover-state-reconf-slaves master mymaster 127.0.0.1 6379
// +slave-reconf-sent:向指定的slave发送"slaveof"指令,令其跟随新的master
10378:X 10 Jul 2023 14:09:35.519 * +slave-reconf-sent slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
10378:X 10 Jul 2023 14:09:35.883 # -odown master mymaster 127.0.0.1 6379
10378:X 10 Jul 2023 14:09:36.522 * +slave-reconf-inprog slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
10378:X 10 Jul 2023 14:09:36.522 * +slave-reconf-done slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
10378:X 10 Jul 2023 14:09:36.581 # +failover-end master mymaster 127.0.0.1 6379
// +switch-master:故障转移完毕后,各个sentinel开始监控新的master
10378:X 10 Jul 2023 14:09:36.581 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6381
10378:X 10 Jul 2023 14:09:36.581 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381
10378:X 10 Jul 2023 14:09:36.581 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
10378:X 10 Jul 2023 14:10:06.585 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
面试官:唔……不错不错,今天不早了,下次我们再聊
花花:okey!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









