






前言
前段时间利用OCR进行了一些图片识别工作,发现还是出现了很多形近字的错误,一个个校对太麻烦了,所以就自己找了一些资源,写了代码来改,但还是有一些无法判断的情况,发出来和各位大佬交流~
参考
ocr识别错误判定工具:
github/pycorrecter
形近字资源:
GitHub - contr4l/SimilarCharacter: 对常用的6700个汉字进行音、形比较,输出音近字、形近字的列表。 # 相近字
具体思路
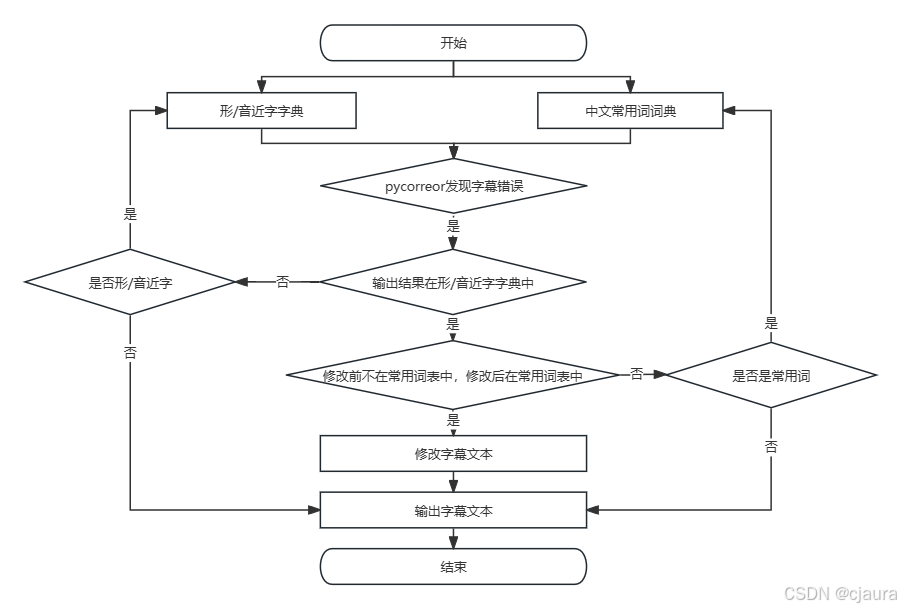
第一步:
整理形近字字典和中文常用词词典
第二步:
利用pycorrector对ocr识别结果进行判断,pycorrector会提供它识别出错误的词汇和它纠正后的词汇。
from pycorrector import MacBertCorrector
m = MacBertCorrector("model/macbert4csc-base-chinese")
errolist = []
batch_size = 50
f_out = open('erros.jsonl','w',encoding='utf-8')
for i in tqdm(range(0,len(zimulist),batch_size)):
j = i +10 if i <len(zimulist)-batch_size else len(zimulist)
inp = zimulist[i:j]
for res in m.correct_batch(inp):
if res['errors'] and not res in errolist:
errolist.append(res)
f_out.write(json.dumps(res,ensure_ascii=False)+'\n')
# {"source": "你们千什么的", "target": "你们干什么的", "errors": [["千", "干", 2]]}对识别出的错误的字,如果它不在中文常用词典中,但是它纠正的结果在中文的常用词典中,那么就接受修改的结果,否则就不接受它修改的结果(因为pycorrecter本身也会判断错误)
或者不用pycorrector,直接用jieba分词,判定分词结果是否都在中文常用词典中,如没有,就词中的每个字逐个替换,如果有在中文常见词典中,则判定这个词存在ocr错误的可能。但也要考虑jieba分词不准的情况。
第三步
可以输入第二部判定的结果,如果有补充的形近字,就可以在文件中加上。
参考代码
# 常用词表读取、建立索引
word_ref = '../词表/userdict.txt'
wordict = {}
with open(word_ref,'r',encoding='utf-8') as file:
for line in file:
line = line.strip()
word = line.split('--')[0]
if not len(word)>1:
continue
for char in word:
if not char in wordict.keys():
wordict[char] = {}
if not len(word) in wordict[char].keys():
wordict[char][len(word)] = []
if not word in wordict[char][len(word)]:
wordict[char][len(word)].append(word)# 确认输入词是否在常用词表中
def check(char,text,wordict):
if not char in wordict.keys():
return False ,False
for length in wordict[char].keys():
if int(length)> len(text):
continue
for word in wordict[char][length]:
pre_len = word.index(char)
suf_len = int(length) - word.index(char)
# print(text,char)
i = text.index(char)-pre_len
j = text.index(char)+suf_len
if i<0 or j>len(text):
continue
# print(text,i,j,text[i:j] ,word)
# exit()
if text[i:j] == word:
# print(text,word)
return 1 ,word
return 0 ,False# 对pycorrecter分析结果进行判断
out1 = open('check1.txt','w',encoding='gb18030')
out2 = open('check2.txt','w',encoding='gb18030')
out3 = open('check3.txt','w',encoding='gb18030')
out4 = open('check4.txt','w',encoding='gb18030')
# checklis = [["你们千什么的" , "你们干什么的",["千", "干", 2]]]
for pair in checklist
text = pair[0]
target = pair[1]
errolist = pair[2]
erro_char = errolist[0]
target_char = errolist[1]
word_idx = errolist[2]
erro_res,erro_word = check(erro_char,text,wordict)
target_res,target_word = check(target_char,target,wordict)
if erro_res ==1:
if target_res ==False and target_res ==0:
# 改错了
out1.write(f'改错:{text}'+str(errolist)+'\n')
continue
else:
# out2.write(f'无法判断:{erro_word}<-->{target_word}\t'+text+'\n')
continue
else:
if target_res == 1:
erro_word = target_word.replace(target_char,erro_char)
out3.write(f'{erro_word}-->{target_word}\t{target}'+str(errolist)+'\n')
else:
# out4.write(f'无法判断:{erro_char}<-->{target_char}\t'+text+'\n')
continue

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









