







1.数据结构定义
(1)数据结构是用来组织数据的结构。
2.初级数据结构(java大类)
1.Collection: 是一个接口包含大部分容器常用的一些方法。
2.List:是一个接口,规范了ArrayList和LinkedList中要实现的方法。
(1)ArrayList 实现List接口,底层为动态类型顺序表
(2)LinkList:实现了LIst接口,底层为双向链表
3.Stack:底层是栈,栈是一种特殊的顺序表。
4.Queue:底层是队列,队列是一种特殊的顺序表。
5.Deque:是一个接口。
6.Set:集合,是一个接口,里面放置的K模型
(1)HashSet:底层为哈希桶,查询的时间复杂度为O(1)
(2)TreeSet:底层为红黑树,查询的时间复杂度是O(log2N),关于Ket有序的
7.Map:映射,里面是K-V模型的键值对
(1)HashMap:底层是哈希桶,查询时间复杂度是O(1)
(2)TreeMap:底层是红黑树,查询的时间复杂度为O(log2N),关于Key有序
3.时间和空间复杂度
(1)衡量一个算法的好与坏就要用时间复杂度和空间复杂度
(2)算法的效率取决于时间和空间,时间复杂度衡量的是一个算法的运行速度,空间复杂度衡量的是一个算法所需要的额外的空间。
3.1时间复杂度(现在在乎的)
(1)时间复杂度的概念:算法的时间复杂度是一个数学函数,算法中的基本操作执行的次数,为算法的时间复杂度
(2)一个算法的运行时间和这个算法当中的语句执行次数有关系。语句执行次数越多运行时间越多,成正比。
(3).示例下列代码时间复杂度计算(大o)
func1可以理解为n*(1+2+3+....+n)+ 2N + 10=n^2+2N+10(随着n越来越大2N和10就可以忽略)
func1简化为f(n) = n^2(一个大概)
代码
void func1(int N){
int count = 0;
for (int i = 0; i < N ; i++) {
for (int j = 0; j < N ; j++) {
count++;
}
}
Func1 执行的基本操作次数 :
N = 10 F(N) = 130
N = 100 F(N) = 10210
N = 1000 F(N) = 1002010
实际中我们计算时间复杂度时,我们其实并不一定要计算精确的执行次数,而只需要大概执行次数,那么这里我们
使用大O的渐进表示法。
大O符号(Big O notation):是用于描述函数渐进行为的数学符号。
3.3 推导大O阶方法
1、用常数1取代运行时间中的所有加法常数。
2、在修改后的运行次数函数中,只保留最高阶项。
3、如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶。
使用大O的渐进表示法以后,Func1的时间复杂度为:
N = 10 F(N) = 100
N = 100 F(N) = 10000
N = 1000 F(N) = 1000000
通过上面我们会发现大O的渐进表示法去掉了那些对结果影响不大的项,简洁明了的表示出了执行次数。
另外有些算法的时间复杂度存在最好、平均和最坏情况:
最坏情况:任意输入规模的最大运行次数(上界)
平均情况:任意输入规模的期望运行次数
最好情况:任意输入规模的最小运行次数(下界)
例如:在一个长度为N数组中搜索一个数据x
最好情况:1次找到
最坏情况:N次找到
3.2大O的渐进表示法 (最常用的最坏复杂度)
1.用常数1取代运行时间中的所有的加法常数。
2.在修改的运行次数函数中,值保留最高阶项。
3.如果最高阶项存在且不是1,则去除与这个项目相乘的常数,得到的结果就是大O阶。
通过计算
// 计算func2的时间复杂度?
void func2(int N) {
int count = 0;
for (int k = 0; k < 2 * N ; k++) {
count++;
}
int M = 10;
while ((M--) > 0) {
count++;
}
System.out.println(count);
}
// 计算func3的时间复杂度?
void func3(int N, int M) {
int count = 0;
for (int k = 0; k < M; k++) {
count++;
}
for (int k = 0; k < N ; k++) {
count++;
}
System.out.println(count);
}
// 计算func4的时间复杂度?
void func4(int N) {
int count = 0;
for (int k = 0; k < 100; k++) {
count++;
}
System.out.println(count);
}
// 计算bubbleSort的时间复杂度?(冒泡排序)
void bubbleSort(int[] array) {
for (int end = array.length; end > 0; end--) {
boolean sorted = true;
for (int i = 1; i < end; i++) {
if (array[i - 1] > array[i]) {
Swap(array, i - 1, i);
sorted = false;
}
}
if (sorted == true) {
break;
}
}
}
// 计算binarySearch的时间复杂度?(二分查找)
int binarySearch(int[] array, int value) {
int begin = 0;
int end = array.length - 1;
while (begin <= end) {
int mid = begin + ((end-begin) / 2);
if (array[mid] < value)
begin = mid + 1;
else if (array[mid] > value)
end = mid - 1;
else
return mid;
}
return -1;
}
// 计算阶乘递归factorial的时间复杂度?(阶乘)
long factorial(int N) {
return N < 2 ? N : factorial(N-1) * N;
}
// 计算斐波那契递归fibonacci的时间复杂度?
int fibonacci(int N) {
return N < 2 ? N : fibonacci(N-1)+fibonacci(N-2);
}
func1是O(n^2)
func2是O(M+N)
func3是O(1)
bubbkeSort是O(n^2)(冒泡排序)
binarySearch是O(log2^n)(二分查找)
factoeial是(递归的次数乘递归后执行的次数(不一定全是这个公式用递归))是O(N)
fibonacci是O(2^n)计算过程{递归的所有次数加起来,执行次数是1,因为是?这个符号一次就行所以算的是递归次数的总和就是时间复杂度
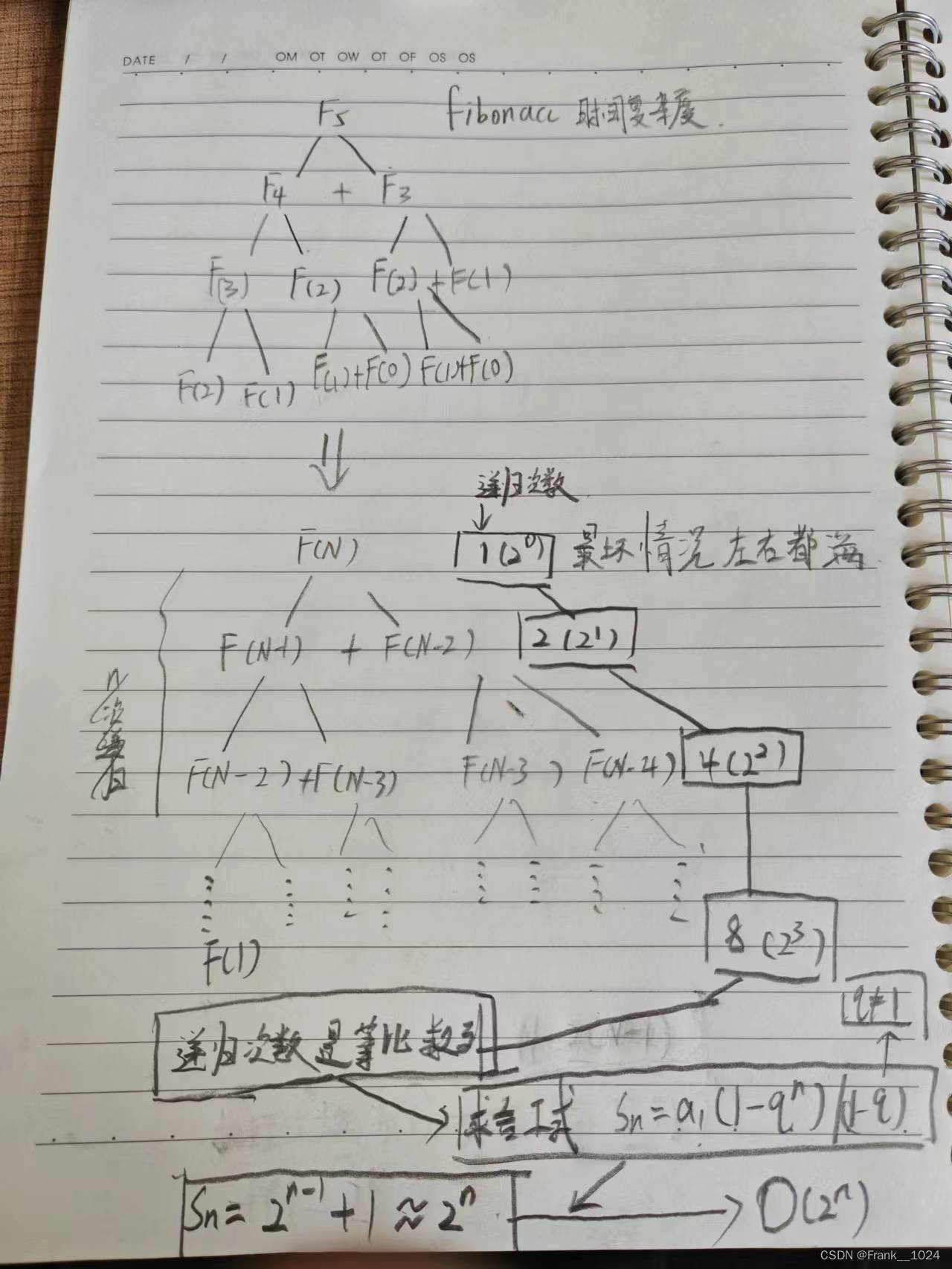
}
3.2空间复杂度(以前在乎的现在内存很便宜)
(1)临时占用空间的量度
(2)也可以使用大O算法表示空间复杂度的计算的方式和时间复杂的的计算方式是相同的。
看有没有重复利用一个相同的空间利用多少次那么空间复杂度就是多少
用的时间复杂的的案例进行讲解
(3)fibonacci的空间复杂度就是O(N)
(4)factoeial的空间复杂度是O(N)(阶乘的时候每一次递归就要重新开辟一个内存所以就是N)
4.包装类
4.1基本数据类型和对应的包装类
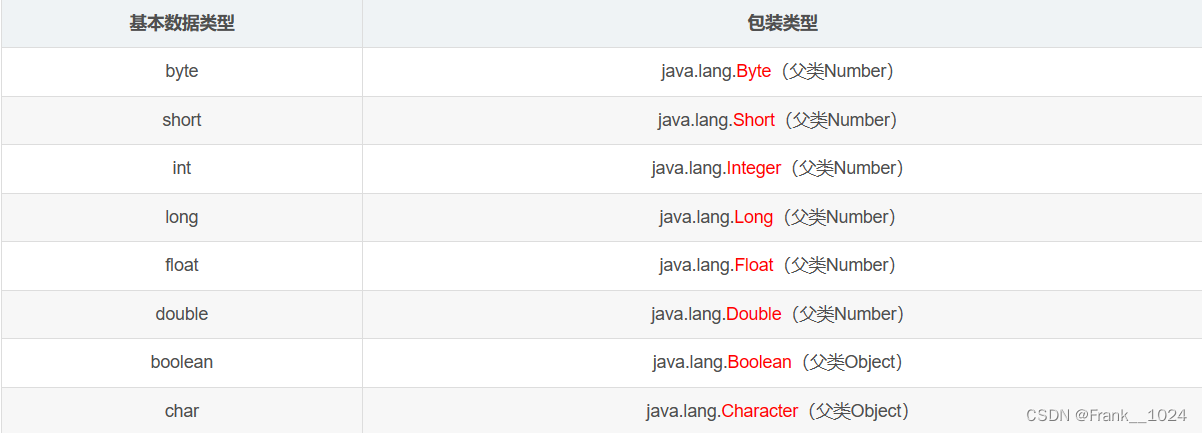
除了 Integer 和 Character, 其余基本类型的包装类都是首字母大写。
4.2装箱拆箱
1.装箱
(1)把一个基本类型转变为包装类型
2.拆箱
(1)把一个包装种类型转变成基本类型
3.如何做到装箱拆箱的?(隐式)
代码
public class Frank {
public static void main(String[] args) {
int a = 10;
Integer ii = a ;//自动装箱
Integer ii2 = new Integer(10);
int b = ii2;//自动拆箱
System.out.println(ii);
System.out.println(ii2);
}
}
(1)进入源码(进入源文件cmd进行反汇编输入javap -c (....))
(2)可以看到bipush存的a是10
可以看到valueof使用了装箱
可以看到inValue使用了拆箱
所以可以用底层代码的思路来进行显示拆箱和显示装箱
代码如下
(装箱)底层相当于(显示装箱)
//Integer ii = a ;//自动装箱
Integer ii = Integer.valueOf(a);(拆箱)底层相当于 (显示拆箱)
Integer ii2 = new Integer(10);
//int b = ii2;//自动拆箱
int b =ii2.intValue();
这两个隐式和显示都是一样的
拆箱可以拆成其他类型
装箱不可以装成其他类型
代码如下
Integer ii2 = new Integer(10);
//int b = ii2;//自动拆箱
double b = ii2.doubleValue();4.2.1问题的引出(阿里巴巴面试题)
定义两个Integer类型的包装类,分别都是100,用sout语句判断是否相等可以发现输出为true
定义两个Interger类型的包装类,分别都是200,用sout语句判断是否相等可以发现输出为False
为什么会出现这种情况?
解答:在这两个过程中发生的是一个装箱的过程,把int类型的装箱成Interger,装箱使用的是Valueo的这个方法进入Valueof这个方法的源码

如果这个i的值在一定得到区间范围内会返回一个新的东西也就是retur IntegerCache,cache(缓存数组)一个数组,
如果不满足就新建了一个对象
说明100在这个范围内
Interger的范围是-128到127,一共有256个数字
图解
当你的i在-128到127这个范围内,会将这个i放入缓存数组中
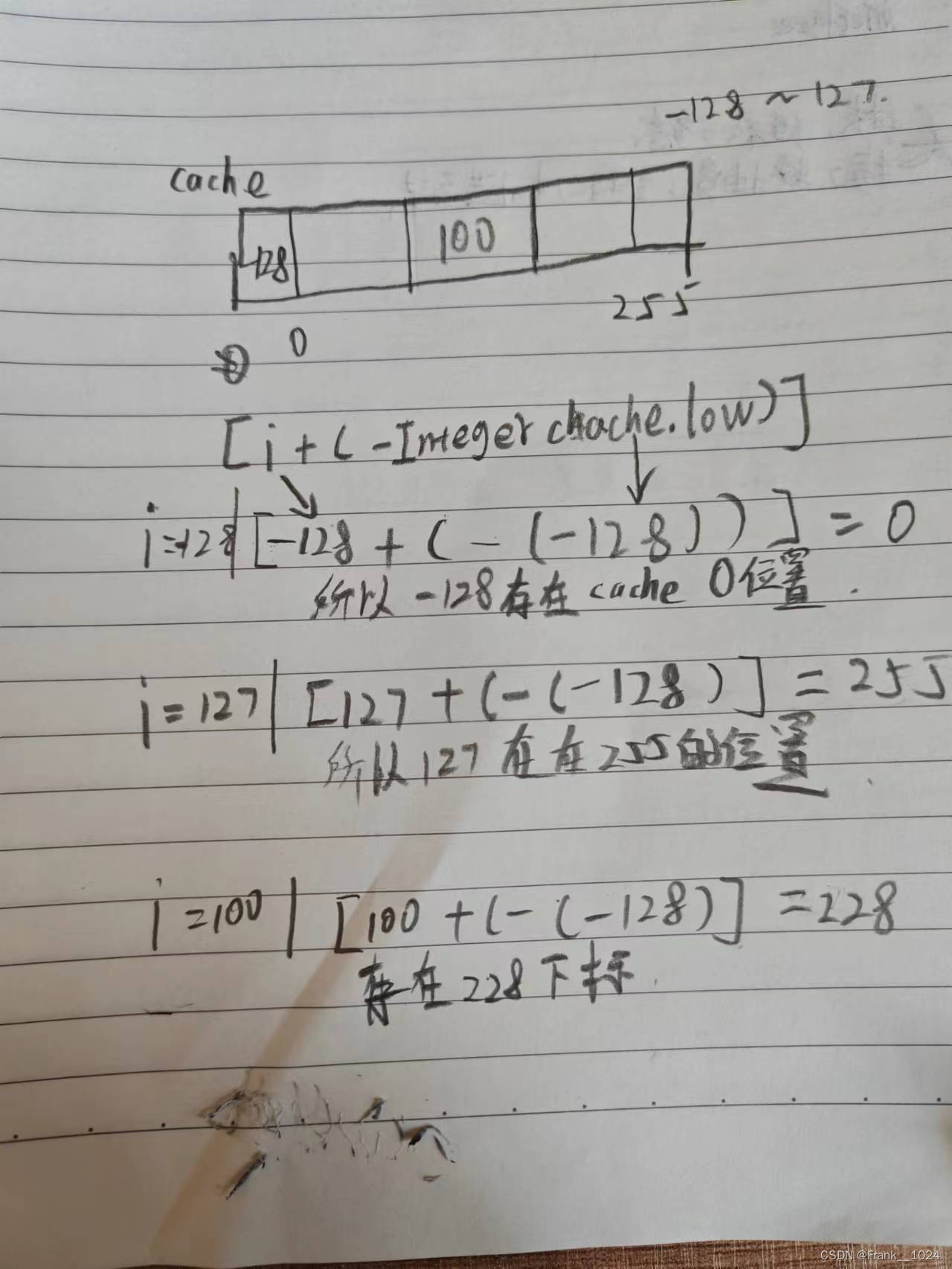
而超过这个范围以后就会新建一个对象所以就会不一样所以就会出现虽然值一样但是计算机判断出来不一样。
5.泛型(C++中叫做模板但是很难)
(只要会用就行,后续数据结构文章会更新完整)
1.泛型就是使用于许多许多类型(可以将一共类型作为参数进行传递)
5.1引出泛型
实现一共类,类中包含一共数组成员使得数组能够存储任何一中类型的数据,也可以更具成员方法返回数组中莫个下标的值?
代码
class MyArray {
public Object[] array = new Object[10];
public void setValue(int pos, int val) {
array[pos] = val;
}
public Object getValue(int pos) {
return array[pos];
}
}
public class Frank {
public static void main(String[] args) {
MyArray myArray = new MyArray();
myArray.setValue(0, 1);
myArray.setValue(1, 19);
myArray.setValue(2, "c");
String str = (String) myArray.getValue(2);
}
}在这段代码中,定义了一个Myarry类,类中实现了一个Object类型的数组,有两个方法分别添加数组和获取数组中的元素,在Frank大类中,分别添加了三个元素,类型分别是两个整数类型和一个字符串类型,而当我们输出的时候,会发现我进行了强制转换,这个的目的是为了安全,但是有种脱裤子放屁的感觉。
那么为了专一的存储一个数据,使得数组更加安全我们就需要一个标准,这个标准就是泛型
5.2泛型
尖括号的就是泛型,泛型可以理解为多种类型的规范
格式
泛型类<类型实参> 变量名; // 定义一个泛型类引用
new 泛型类<类型实参>(构造方法实参); // 实例化一个泛型类对象应用
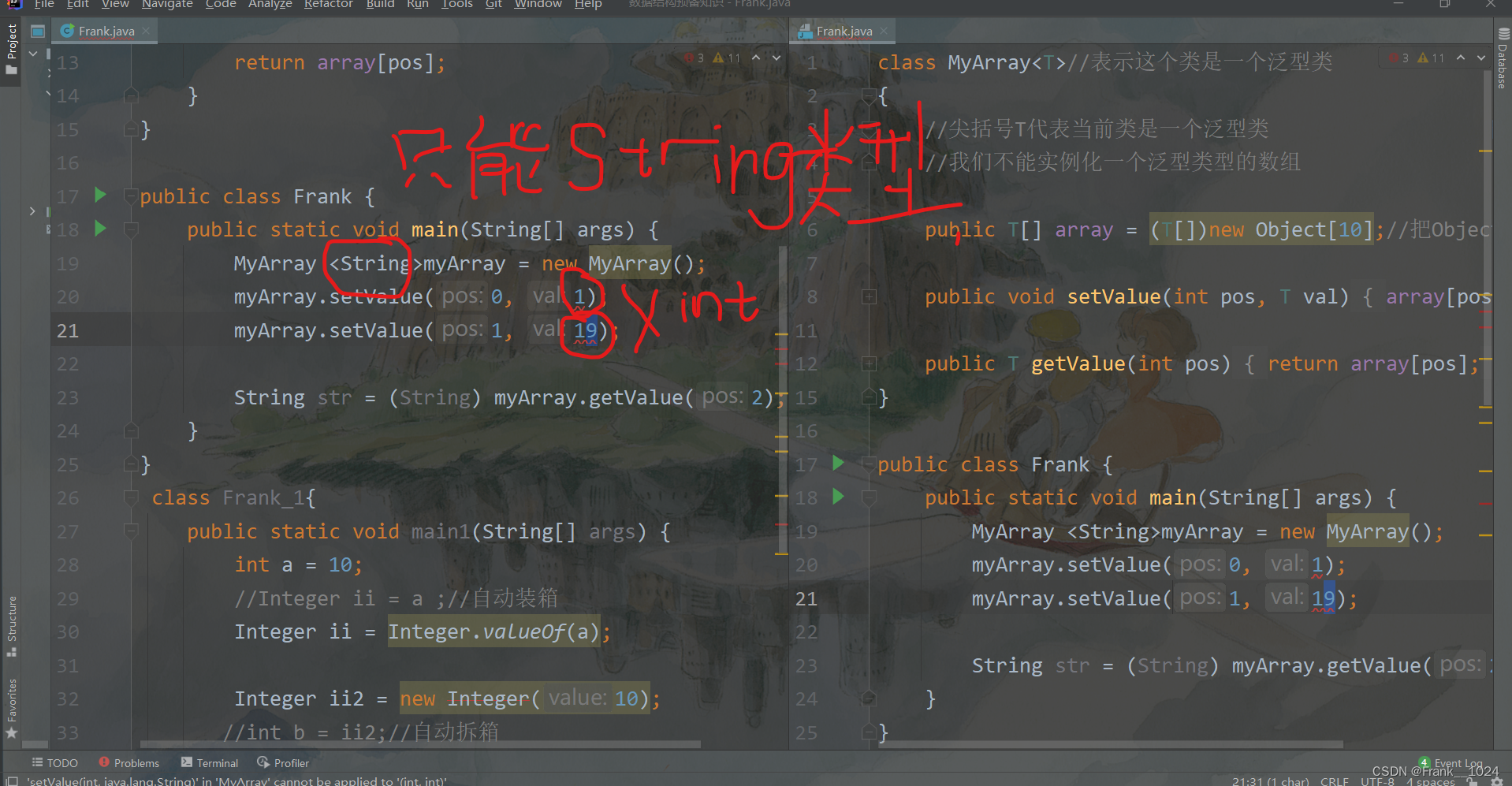
那么想存int类型的数组可以像规定String一样规定一个只存int类型的数组,这样就不用强转了。
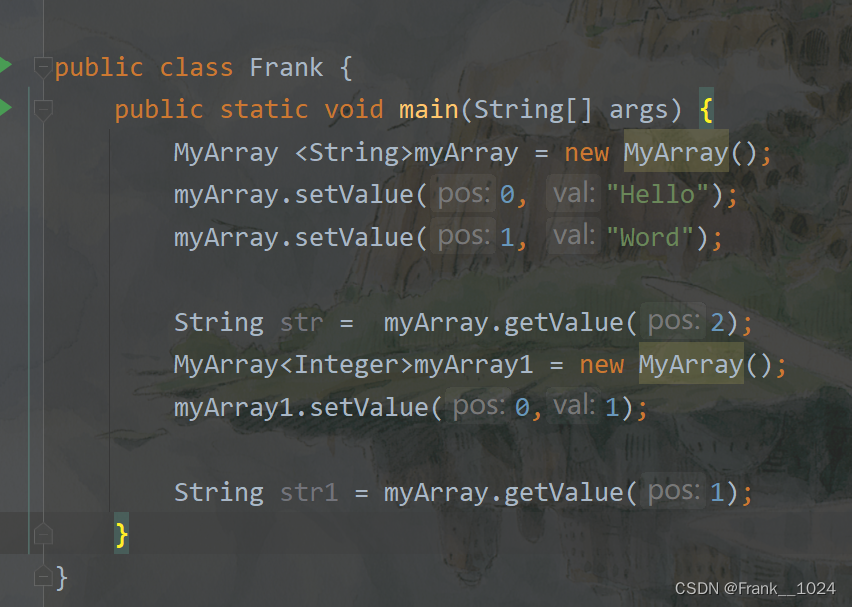
可以看到非常的方便。(尖括号就是帮助你使用什么类型的来对参数进行绑定),你还可以有一个MyArray<person>类型的数组,这样就可以达到通用。

上图的这段代码其实是骗过了编译器,这擦除机制后续会进行讲解。(伏笔) <>(不建议这么写)
5.3泛型总结
1.泛型的意义是在编译的时候检查数据类型是否正确
2.在编译的时候帮助进行类型的转化(自动进行强制转换)
3.在实例化泛型对象的时候不可以是基本数据类型。只能是引用类型。
在后续的数据结构学习中会出现大量的泛型应用,所以我把泛型加入到了数据结构中而不是语法中。
5.4泛型<>中可以放的符号代表什么含义?
【规范】类型形参一般使用一个大写字母表示,常用的名称有:
1.E 表示 Element
2.K 表示 Key
3.V 表示 Value
4.N 表示 Number
5.T 表示 Type S, U, V 等等 - 第二、第三、第四个类型
5.5泛型的一些注意事项
泛型是编译时期的一种机制,所以我们不建议这样写
![]()
数组有一个特点,实例化的数组必须是一个具体类型的数组,而此时的T我们不知道是什么类型,所以是不对的
这样写也是骗过了编译器看似数组有了类型但是也是不建议这样写后续会详细讲解。
5.6裸类型(Raw Type)
裸类型是一个泛型类但没有带着类型实参,例如 MyArrayList 就是一个裸类型
MyArray list = new MyArray();
注意: 我们不要自己去使用裸类型,裸类型是为了兼容老版本的 API 保留的机制 下面的类型擦除部分,我们也会讲到编译器是如何使用裸类型的。
小结: 1. 泛型是将数据类型参数化,进行传递 2. 使用 表示当前类是一个泛型类。 3. 泛型目前为止的优点:数据类型参数化,编译时自动进行类型检查和转换
5.7 泛型的擦除机制
那么,泛型到底是怎么编译的?这个问题,也是曾经的一个面试问题。泛型本质是一个非常难的语法,要理解好他 还是需要一定的时间打磨。
通过命令:javap -c 查看字节码文件,所有的T都是Object。

虽然在编译器中是我们定义的<>类型,可以是Interger或者String类型,但是在最后字节码文件中,其实都是Object类型的,所以引出了擦除机制,最后的泛型类型都会擦成Object类型
5.7.1疑问?
既然都擦除成了Object那么数组类型都是一样的为什么还要泛型?
因为数组是一个非常复杂的东西,在java中要像了解他我们还要对jvm中进行分析了解 !
示例:
class MyArray<T>
{
public T[] array = (T[])new Object[10];
public void setValue(int pos, T val) {
array[pos] = val;
}
public T getValue(int pos) {
return array[pos];
}
public T[] getArray(){
return array;
}
}
public class Frank {
public static void main(String[] args) {
MyArray <String>myArray = new MyArray();
myArray.setValue(0,"Hello");
String str = MyArray.getArray();
}
}
在这段代码中虽然我们可以通过编译器,但当我们进行运行是会发生异常是
因为在擦除成Object这个类型的数组以后,数组的整体强转是不能够进行的,上面的这段代码相当于将Object这个类型转化成为了String类型的数组.所以我们不能 用String类型进行接收,我们要用Object进行接收(String str = MyArray.getArray()产生错误的主要原因)所以这样写在逻辑上不是严谨的。
![]()
所以上图我说是骗过了编译器,=建议下方代码的写法
class MyArray<T>
{
public Object [] array = new Object[10];
public void setValue(int pos, T val) {
array[pos] = val;
}
public T getValue(int pos) {
return(T)array[pos];
}
}上面的这段代码的getValue方法中使用了强制转换,将它强制转换为了(T)类型,这样就可以让我们检查这个类型是不是我们满足的类型。
在setvalue方法中的传递参数的T相当于规范了传入的参数是你指定的类型。
总的来说泛型是编译时的机制,它只是为了帮助你编译而不是运行。
5.8泛型的上界
1.在定义泛型类的时侯,又是需要对传入的变量做一定的约束,可以通过类型边界来约束。
(1)数组是一种单独的数据类型,数组和数组之间是没有继承关系的
int【】,String【】,,,,,,,,、
2.泛型上界。
class 泛型类名称<类型形参 extends 类型边界> {
...
}类型形参一定是类型边界的子类。也就是>=的关系number = number也可以
3.格式
public class MyArray<E extends Number> {
...
}
E必须是Number的子类或者是Number
泛型没有下界
4.具体应用
要求:写一个泛型类,让你求一个数组当中的最大值。
其中还要注意的一点就是,Arg后面的T一定是实现了Compareable接口的大类。
class Arg <T extends Comparable<T>>//在Object这个大类是没有实现Comparable这个接口的这个的意思就是让传入的参数都实现了Compareable接口
{
public T MaxFirst(T[] array){
T max = array[0];
for (int i = 1; i < array.length; i++) {
if (array[i].compareTo(max)>0){
max = array[i];
}
}
return max;
}
}5.8.1泛型方法
(1)在类中定义方法,方法中含有泛型
继续使用Arg方法举例
class Arg3{
public static<T extends Comparable<T>>T MaxFirst(T[] array){
T max = array[0];
for (int i = 1; i < array.length; i++) {
if (array[i].compareTo(max)>0){
max = array[i];
}
}
return max;
}(2)定义一个Arg3类,定义一个静态方法然后的步骤就和Arg一样,这样做的好处就是可以不用实例化对象,只要直接调用就行了。
最后这不是全部的泛型还有通配符,讲到这里是完全够用了,在数据结构的结尾,我会详细讲解,只有在学习完二叉树,红黑树等数据结构才能更好的融汇贯通
















 314
314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











