







1.常见的设计模式
1.1单例模式
(1)单例模式的意思就是在一个类中的对象只有一个,那么这样的模式就叫做单例模式
(2)其中人为的规定是没有用的所以我们用一些代码操作编译器然后强制的对其进行搜索确保这个类中是只有一个对象。
(3)其中有两种来满足单例模式的模式
饱汉模式和饿汉模式。
前情提要

这时候就有一个问题既然我这样就可以只用一个实例了,那么我在类的里面进行实例化对象不就好了
这样其实是不行的因为这个代码是你自己写的那么你也不希望被人进行乱修改,你在工作中,其实是要求被审核才能被修改的.
1.1.1饿汉模式

1.1.2懒汉模式

这个模式可以理解为
我假如是一个勤快的人,我厕所上小便,一天我要上好多次
我假如我是一个懒逼,我一天攒好久的再小便,这就是懒汉模式,其中懒汉模式并不是代表效率很低而是非常的高。
其中饿汉模式有一个非常大的缺点饿汉模式是在程序的初期就直接创建实例,所以多个线程创建实例的时候会非常的卡
懒汉模式的化是只有你调用了这个类那么这个类才会来进行使用,并且这个类还会来判断是否需要创建实例,如果没有创建就会进行创建,如果创建完毕了就不会进行创建

1.2单例模式的线程是否是安全的。 (两种模式核心要点)
(1)饿汉模式的线程是安全的
(2)懒汉模式是线程不安全的
解析饿汉模式

在饿汉的线程中是在main方法之前就已经创建出来了实例,所以说在接下来的方法中其实读取的对象都是所以线程不会不安全。

解析懒汉模式

在懒汉模式中会发生线程不安全的主要原因图解

这样就会创建两个实例,并且线程也是不安全的。
其中,我在学习的过程中思考过创建实例不就多了几个,注意有一些实例其实是非常大的100个G都是有可能的。
1.3解决懒汉模式的线程不安全问题
(1)其中注意的就是只要上锁了那么这个程序的性能就会大大折扣,我们这个语言的性能方面和C++这个语言比不了,所以这是一个扩展点。
C++ 这个语言你在写的过程都要考虑i++和++i,还要考虑函数以及对象在拷贝过程中的一些东西,所以这个语言工具虽然它的库十分的不友好,你打开它的库源代码你会发现一堆奇奇怪怪的符号压根看不懂=》垃圾,但是它的性能是毋庸置疑的。
其中在两个if之间有非常小的概率可能会发生内存不可读的问题所以我们可能需要用到volatile

为了避免内存不可读这件事加一个volatile就能更好的避免

2.阻塞队列
(1)队列的种类
我们在学习队列的过程中已经学习了很多不同种类的队列。
普通队列 线程不安全
优先级队列 线程不安全
阻塞队列 线程安全
2.1阻塞队列的定义
阻塞队列是先进先出的,并且还是带有阻塞功能的。
如果这个队列已经空了,这时候尝试出队列就会阻塞
如果这个队列已经满了,这时候尝试入队列就会阻塞

2.2消息队列的定义
消息队列也是先进先出的,但是它会用topic这种数据类型来对数据进行归类,其中每个topic旗下的数据是先进先出的。
其中消息队列也是会阻塞的。
举例
你去医院只有一个医生这个医生只能在同一时刻接待一个病人

这个的好处就是能够使得两个需要进行交互的线程降低耦合性,而且还能保证线程的安全
3.生产者消费者模型
(1)我们可以通过上面的队列来实现这个模型,根据需求来选择哪一个队列来进行实习
(2)生产者消费者模型的简单讲解
这个模型可以理解为图解

(3)生产者消费者模型的好处介绍 、

(4)引入生产者消费者模型用来保护工作线程的好处
并且生产者消费者模型中的队列可以降低每个线程和每一个线程的耦合性,我们只需要将新的线程和队列相互有所联系就行了

这样还有一个缺点就是执行的效率不是特别的高。
(5)并且这个可以保证服务器与客户端的稳定性,不论客户端来多少,都不会影响到B这个线程来处理队列中数据的结果。
(6)图解

4.阻塞队列的详细讲解
(1)原本的队列是没有阻塞功能也就是Queue队列,所以编译器给我们写了一个阻塞队列其中,BlockQueue(阻塞队列)写了一个阻塞的功能,然后为了让这个BlockQueue这个类拥有Queue的poll等方法,我们继承了队列这样一个阻塞队列就完成了。
源代码

(2)扩展自己实现阻塞队列
其中需要注意的就是在多线程中,多个线程对有多个个count变量进行计数。也可以用一个,但是我们需要进行加锁。
上面的编译器给我们实现了阻塞队列我进行了讲解其实也就是一个引子

(3)队列中的take和put方法
实现take方法代码和put方法的讲解


其中我们继承了队列的put和take方法这两个方法可以的源码的原理就是我们的上图
其中我们要注意的就是wait这个方法不仅仅只会被notify()这个方法唤醒还可能被interrupt这个方法唤醒所以为了我们的线程安全我们可以用while循环来在这个方法执行完毕以后再确认一次来保证线程的安全。
也就是唤醒以后再确认一次来保证线程的安全性。

5.线程池
线程池是大佬帮我们写好的东西,我们直接拿过来用就行了,其中有常量池,数据库连接池,线程池,内存池,进程池。。。。。等等等等
5.1常量池
我们可以理解为我是个帅哥,然后我现在有一个男盆友,然后我现在微信里面有很多的小哥哥的微信,然后这些小哥哥都喜欢我,如果我现在分手了那么我们就可以立马无缝衔接,而这个有非常多喜欢我的小哥哥的鱼塘池,我们就可以称之为备胎池子,那么常量池同样的原理,在我们工作的时候,我们需要什么就到这个池子里面去找需要的东西。
其他的池的意思都是一样的。

5.2线程池的作用
线程池可以帮助我们提高编译的效率,并且还能更好的减少电脑资源的消耗(内核的开销),
打一个比方,我去银行去借钱,我要用 身份证的复印件,我把身份证交给银行柜台的小姐姐,
这时候他就要进行上报然后通过层层的审批然后才能通过经过非常繁琐的过程才能够给你把身份证的复印件给你其中这个过程不是你自己来进行控制的。所以不是特别可靠,没有使用线程池的效果
第二种的情况相当于你自己去打印店去打印身份证的复印件,然后交给柜台的小姐姐来处理,这样效率就是非常快的,这个就是线程池的意思。
(1)线程的销毁是需要用户态和服务器的内核进行配合的,所以会消耗服务器资源,在以前的时候服务器一秒钟处理1000个请求这是非常简单的,后面随着时代的发展,处理请求的数量变成了10000条甚至更多,这时候服务器不断的对线程进行创建销毁这时候就会使得内核资源消耗的非常的大,导致内核的不稳定。
(2)如果我们用线程池那么就是用户态一直在参与,这并不会消耗内核的资源,相当于我用完就把这个线程还到线程池当中去就行了,这个过程没有线程的销毁,所以不会有内核参与到其中来自然也就没有内核资源的消耗了。
5.3.协程
其中也有一个和线程池类似作用的东西也就是协程这个东西类似于
不是在内核中提前把线程给创建好
而是用一个内核来创建的线程来代替多个协程,这样就可以减轻内核的负担

5.3.线程池的用法
再java中大佬给我写了线程池。
ThreadPoolExecutor

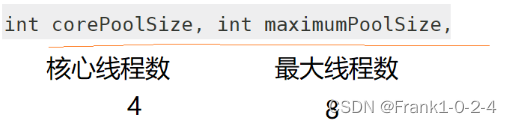
核心线程数相当于线程池的核心员工,如果这些线程不够用了就会新建线程,最大的线程数是8,
5.3.1一些奇怪的线程
在我们进行编程的时候,我们会想设置多少的线程是比较有利于开发的,网上有很多种的答案,但是只要是关于数量的其实都是有问题的,在实际的开发中,要根据电脑的性能CPU核心数量来定义,其中就有两种比较理想的情况,分别是全部交给CPU,还有一种是进行IO等待,其实最实际的可能性是程序是介于这两者之间的。


其实上面的两种情况都太理想化了,在实际的开发中其实是介于两者之间的,为了能够更好的测出线程的数量我们一般是通过测试来对线程的数量进行判断的。


















 705
705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











