







由于毕设做的是一个校园新闻手机客户端,所以思路是这样的:
1、获取到合肥工业大学主页的新闻数据,保存到本地数据库中。
2、编写服务器端提供http链接,返回JSON数据给客户端解析数据。
3、可能需要每天爬取新闻数据更新到数据库中,其次服务器端可能需要个管理员界面,可以发布新闻等操作。
今天要做的就是先用python爬虫爬取合肥工业大学新闻主页的新闻数据,并保存到MySQL数据库中去。工大新闻主页地址是http://news.hfut.edu.cn/,而且工大的新闻是分类的,我要爬取的是“工大要闻”、“通知公告”、“报告讲座”等等。
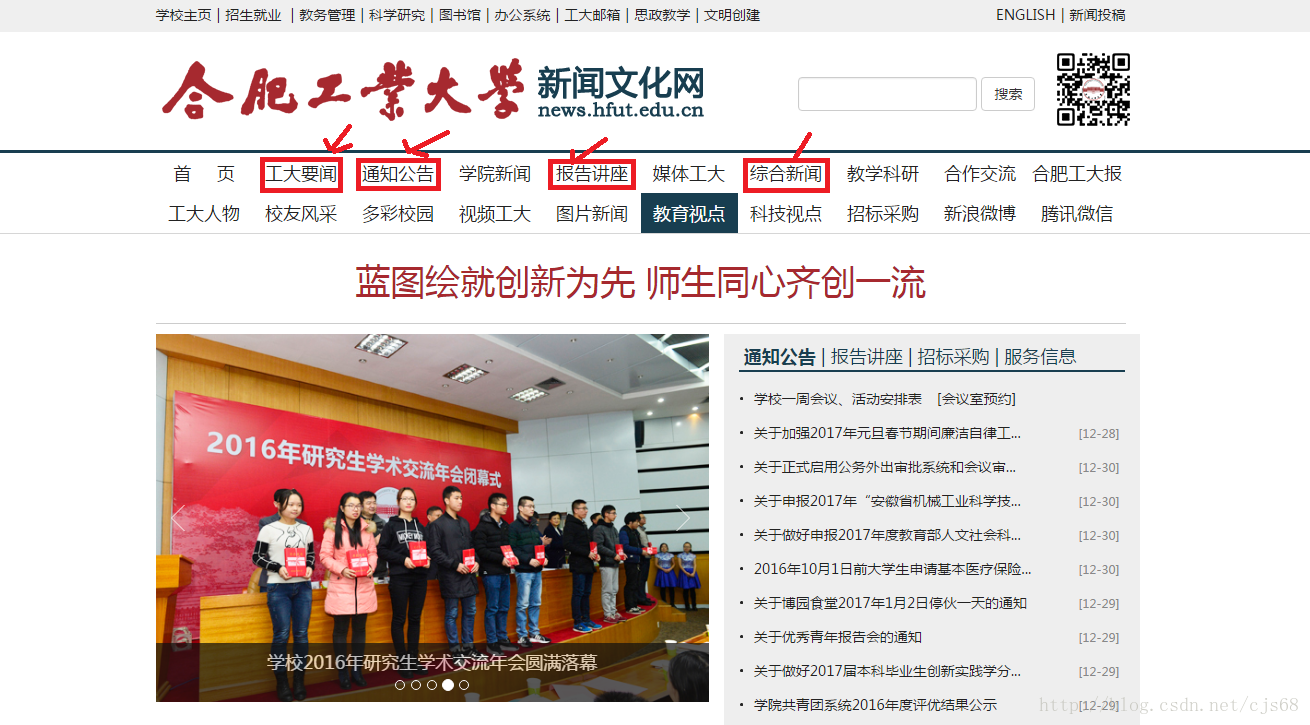
1、找到需要访问的目标地址
先从“工大要闻”爬取开始,打开工大要闻页面http://news.hfut.edu.cn/list-1-1.html,要爬取的是如下图所示的红色框中的内容:
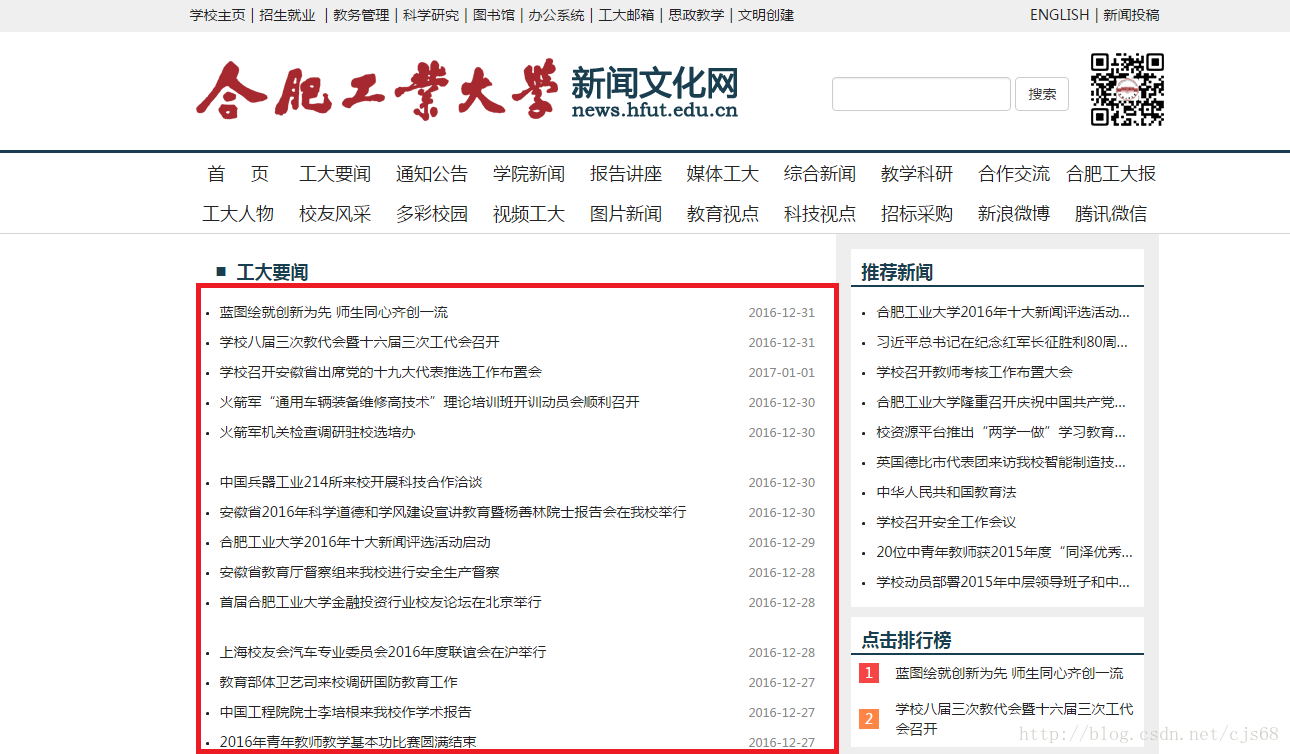
我使用的是Chrome浏览器,右键查看网页源代码,找到新闻列表所在的代码部分,找到对应的html标签,找到如下:
<!--main-->
<div class="container row main in2">
<div class=" col-lg-8 " style="padding-top: 15px;">
<h3 class="title-1"><span class="glyphicon glyphicon-stop" style="font-size: 10px; color:#183e50;text-indent: 0px;top: -1px;padding-right: 10px;"></span>工大要闻</h3>
<ul class="content list pushlist lh30 ">
<li><span class="rt">2016-12-31</span><a href="/show-1-45626-1.html" title="蓝图绘就创新为先 师生同心齐创一流" target="_blank" style="" >蓝图绘就创新为先 师生同心齐创一流</a></li>
<li><span class="rt">2016-12-31</span><a href="/show-1-45625-1.html" title="学校八届三次教代会暨十六届三次工代会召开" target="_blank" style="" >学校八届三次教代会暨十六届三次工代会召开</a></li>
<li><span class="rt">2017-01-01</span><a href="/show-1-45627-1.html" title="学校召开安徽省出席党的十九大代表推选工作布置会" target="_blank" style="" >学校召开安徽省出席党的十九大代表推选工作布置会</a></li>
<li><span class="rt">2016-12-30</span><a href="/show-1-45445-1.html" title="火箭军“通用车辆装备维修高技术”理论培训班开训动员会顺利召开" target="_blank" style="" >火箭军“通用车辆装备维修高技术”理论培训班开训动员会顺利召开</a></li>
<li><span class="rt">2016-12-30</span><a href="/show-1-45506-1.html" title="火箭军机关检查调研驻校选培办" target="_blank" style="" >火箭军机关检查调研驻校选培办</a></li>
<li class="bk20 hr"></li> <li><span class="rt">2016-12-30</span><a href="/show-1-45613-1.html" title="中国兵器工业214所来校开展科技合作洽谈" target="_blank" style="" >中国兵器工业214所来校开展科技合作洽谈</a></li>
<li><span class="rt">2016-12-30</span><a href="/show-1-45610-1.html" title="安徽省2016年科学道德和学风建设宣讲教育暨杨善林院士报告会在我校举行" target="_blank" style="" >安徽省2016年科学道德和学风建设宣讲教育暨杨善林院士报告会在我校举行</a></li>
<li><span class="rt">2016-12-29</span><a href="/show-1-45583-1.html" title="合肥工业大学2016年十大新闻评选活动启动" target="_blank" style="" >合肥工业大学2016年十大新闻评选活动启动</a></li>
<li><span class="rt">2016-12-28</span><a href="/show-1-45565-1.html" title="安徽省教育厅督察组来我校进行安全生产督察" target="_blank" style="" >安徽省教育厅督察组来我校进行安全生产督察</a></li>
<li><span class="rt">2016-12-28</span><a href="/show-1-45571-1.html" title="首届合肥工业大学金融投资行业校友论坛在北京举行" target="_blank" style="" >首届合肥工业大学金融投资行业校友论坛在北京举行</a></li>
<li class="bk20 hr"></li> <li><span class="rt">2016-12-28</span><a href="/show-1-45560-1.html" title="上海校友会汽车专业委员会2016年度联谊会在沪举行" target="_blank" style="" >上海校友会汽车专业委员会2016年度联谊会在沪举行</a></li>
<li><span class="rt">2016-12-27</span><a href="/show-1-45558-1.html" title="教育部体卫艺司来校调研国防教育工作" target="_blank" style="" >教育部体卫艺司来校调研国防教育工作</a></li>
<li><span class="rt">2016-12-27</span><a href="/show-1-45552-1.html" title="中国工程院院士李培根来我校作学术报告" target="_blank" style="" >中国工程院院士李培根来我校作学术报告</a></li>
<li><span class="rt">2016-12-27</span><a href="/show-1-45548-1.html" title="2016年青年教师教学基本功比赛圆满结束" target="_blank" style="" >2016年青年教师教学基本功比赛圆满结束</a></li>
<li><span class="rt">2016-12-26</span><a href="/show-1-45525-1.html" title="学校召开安全生产大检查工作布置会" target="_blank" style="" >学校召开安全生产大检查工作布置会</a></li>
<li class="bk20 hr"></li> <li><span class="rt">2016-12-26</span><a href="/show-1-45519-1.html" title="我校 “可再生能源接入电网技术国家地方联合工程实验室” 获批" target="_blank" style="" >我校 “可再生能源接入电网技术国家地方联合工程实验室” 获批</a></li>
<li><span class="rt">2016-12-24</span><a href="/show-1-45513-1.html" title="国内首台“ 氦三极化靶”在我校研制成功" target="_blank" style="" >国内首台“ 氦三极化靶”在我校研制成功</a></li>
<li><span class="rt">2016-12-23</span><a href="/show-1-45486-1.html" title="学校召开2016年校情通报会" target="_blank" style="" >学校召开2016年校情通报会</a></li>
<li><span class="rt">2016-12-23</span><a href="/show-1-45497-1.html" title="学校2016年研究生学术交流年会圆满落幕" target="_blank" style="" >学校2016年研究生学术交流年会圆满落幕</a></li>
<li><span class="rt">2016-12-22</span><a href="/show-1-45453-1.html" title="我校在全国高校系列网络文化评比中获佳绩" target="_blank" style="" >我校在全国高校系列网络文化评比中获佳绩</a></li>
<li class="bk20 hr"></li> <li><span class="rt">2016-12-21</span><a href="/show-1-45425-1.html" title="学校召开2017年度国家自然科学基金申报动员大会" target="_blank" style="" >学校召开2017年度国家自然科学基金申报动员大会</a></li>
<li><span class="rt">2016-12-21</span><a href="/show-1-45286-1.html" title="资环学院一研究成果在南海岛屿生态地质学研究取得新进展" target="_blank" style="" >资环学院一研究成果在南海岛屿生态地质学研究取得新进展</a></li>
<li><span class="rt">2016-12-20</span><a href="/show-1-45418-1.html" title="我校举行“家风建设”名家书法邀请展暨第30届师生书法展" target="_blank" style="" >我校举行“家风建设”名家书法邀请展暨第30届师生书法展</a></li>
<li><span class="rt">2016-12-20</span><a href="/show-1-45396-1.html" title="我校在第十一届安徽省大学生职业规划设计大赛暨大学生创业大赛中获得佳绩" target="_blank" style="" >我校在第十一届安徽省大学生职业规划设计大赛暨大学生创业大赛中获得佳绩</a></li>
<li><span class="rt">2016-12-20</span><a href="/show-1-45392-1.html" title="我校新增国家“智慧养老国际科技合作基地”" target="_blank" style="" >我校新增国家“智慧养老国际科技合作基地”</a></li>
<li class="bk20 hr"></li>
<div class="bk15 "></div>
</ul>2、如何获取网页源代码
浏览器上面我们可以右键查看网页源代码,在python中我们可以模拟网页请求访问网页,获取源代码。
加上headers到请求中去可以伪装成浏览器去访问网页,否则爬虫访问的太快,网页会认为这不是正常的访问,你的访问速度会很慢或者你的访问被禁止等等。
# 得到页面全部内容
def askURL(url):
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
try:
request = urllib2.Request(url, headers=headers) # 发送请求
response = urllib2.urlopen(request) # 取得响应
html = response.read() # 获取网页内容
# print html
html = html.encode('utf-8', 'ignore') # 将unicode编码转为utf-8编码
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
html = ""
if hasattr(e, "reason"):
print e.reason
html = ""
return html3、找到一页中所有的新闻链接
每一个新闻都保存在一个标签中,如下:
<li><span class="rt">2016-12-31</span><a href="/show-1-45626-1.html" title="蓝图绘就创新为先 师生同心齐创一流" target="_blank" style="" >蓝图绘就创新为先 师生同心齐创一流</a></li>获取所有的新闻链接的方式如下:
# 得到正文的URL,读取正文,并保存
def getURL(nurl):
text = ''
html = askURL(nurl)
# print html
findDiv = re.compile(r'<li><span class="rt">(.*?) target="_blank" style="" >', re.S)
findTime = re.compile(r'(.*)</span>')
findTitle = re.compile(r'title="(.*)"')
findURL = re.compile(r'<a href="(.*)" title')
# findLabel = re.compile(r'<h3.*?</span>(.*?)</h3>')
# fileNum = 0
# list = re.findall(findDiv, html)
# print list[0]x
# labelName = re.findall(findLabel, html)[0]
for info in re.findall(findDiv, html):
# print info
time = re.findall(findTime, info)[0]
# print time
title = re.findall(findTitle, info)[0]
url = re.findall(findURL, info)[0] # 获取新闻正文的链接
url = 'http://news.hfut.edu.cn' + url
print time + ' ' + title + ' ' + url
try:
text = getContent(url)
insertData(text['date'], text['title'], text['newsContent'], text['writer'], text['photoer'],
text['editor'], url)
# text = {'title': '', 'date': '', 'writer': '', 'photoer': '', 'editor': '', 'newsContent': ''}
except urllib2.URLError, e:
if hasattr(e, "reason"):
print "抓取错误" + url, e.reason
except Exception, e:
print "抓取错误" + url, e传入的参数nurl是每一页新闻的网页地址,每一页的地址都有如下规律:
第一页:http://news.hfut.edu.cn/list-1-1.html
第二页:http://news.hfut.edu.cn/list-1-2.html
……
所以我们要提取所有的页面的工大要闻的地址就在“http://news.hfut.edu.cn/list-1-”后面加上n.html就可以了,而上面也获取到了每一页新闻的所有新闻的链接和新闻标题。
4、获取一个新闻的主要内容,包括标题、正文、作者、编辑等
另外编写一个方法获取一个新闻的详细内容,举个例子以下面这个新闻为例:http://news.hfut.edu.cn/show-1-45408-1.html
需要获取红色框中的内容:
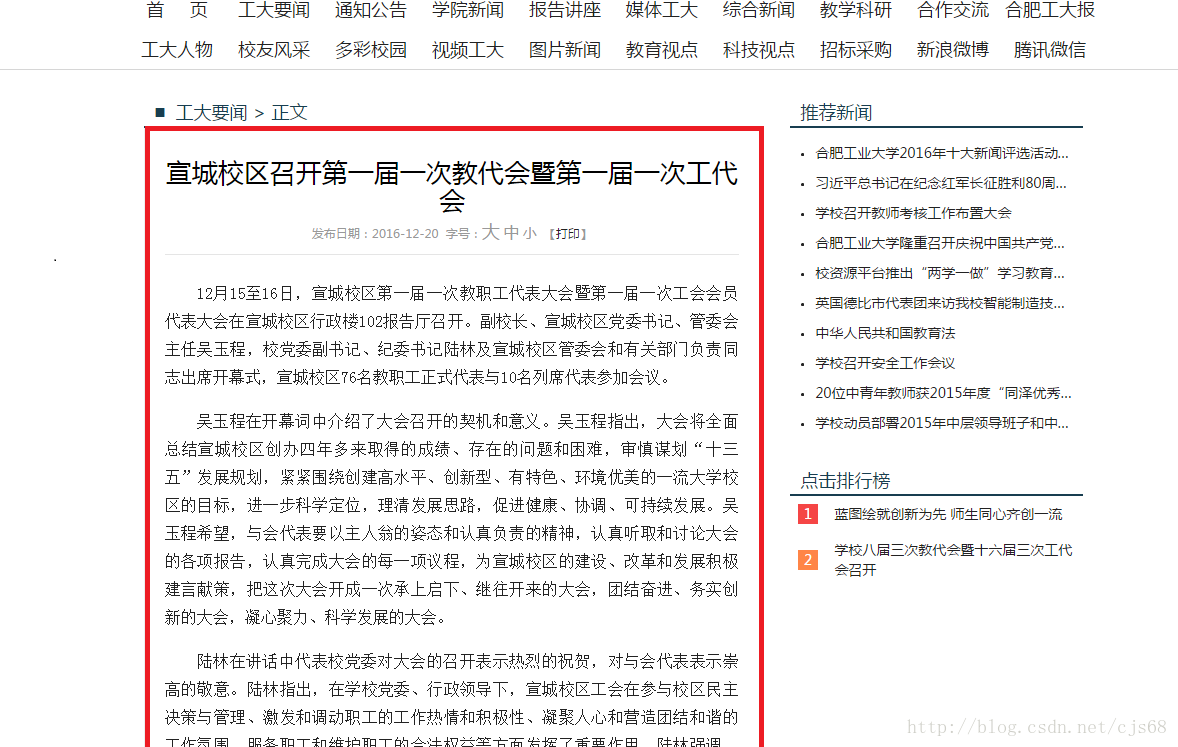
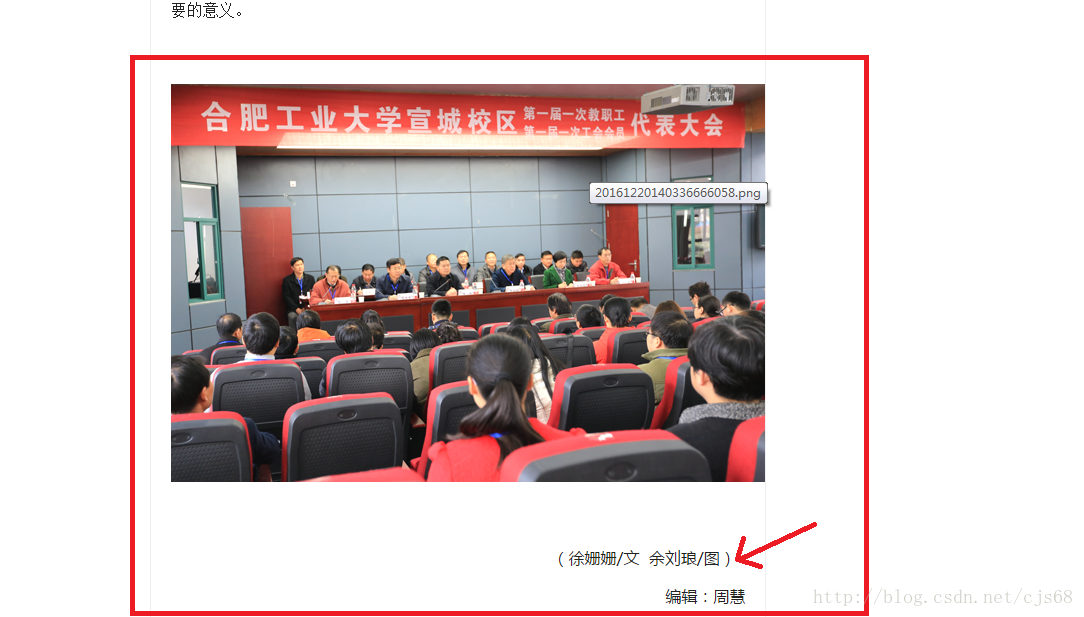
以及最后面的新闻照片和作者、编辑等信息。右键查看网页源代码,找到正文内容,提取关键的html标签。
找到源码如下:
<div id="Article">
<h2>宣城校区召开第一届一次教代会暨第一届一次工代会<br />
<span class="t">发布日期:2016-12-20 字号:<a href="javascript:doZoom(18)"><span class="f18">大</span></a> <a href="javascript:doZoom(16)"><span class="f16">中</span></a> <a href="javascript:doZoom(14)"><span class="f14">小</span></a> 【<a href="/print-1-45408-1.html" target="_blank">打印</a>】</span></h2>
<div id="artibody" class="content f16">
<p style="TEXT-ALIGN: justify; TEXT-INDENT: 2em">12月15至16日,宣城校区第一届一次教职工代表大会暨第一届一次工会会员代表大会在宣城校区行政楼102报告厅召开。副校长、宣城校区党委书记、管委会主任吴玉程,校党委副书记、纪委书记陆林及宣城校区管委会和有关部门负责同志出席开幕式,宣城校区76名教职工正式代表与10名列席代表参加会议。</p><p style="TEXT-ALIGN: justify; TEXT-INDENT: 2em">吴玉程在开幕词中介绍了大会召开的契机和意义。吴玉程指出,大会将全面总结宣城校区创办四年多来取得的成绩、存在的问题和困难,审慎谋划“十三五”发展规划,紧紧围绕创建高水平、创新型、有特色、环境优美的一流大学校区的目标,进一步科学定位,理清发展思路,促进健康、协调、可持续发展。吴玉程希望,与会代表要以主人翁的姿态和认真负责的精神,认真听取和讨论大会的各项报告,认真完成大会的每一项议程,为宣城校区的建设、改革和发展积极建言献策,把这次大会开成一次承上启下、继往开来的大会,团结奋进、务实创新的大会,凝心聚力、科学发展的大会。</p><p style="TEXT-ALIGN: justify; TEXT-INDENT: 2em">陆林在讲话中代表校党委对大会的召开表示热烈的祝贺,对与会代表表示崇高的敬意。陆林指出,在学校党委、行政领导下,宣城校区工会在参与校区民主决策与管理、激发和调动职工的工作热情和积极性、凝聚人心和营造团结和谐的工作氛围、服务职工和维护职工的合法权益等方面发挥了重要作用。陆林强调,宣城校区学生精神面貌好,学习劲头足,在各类学科竞赛中成绩喜人,希望宣城校区能够以此次大会为起点和契机,发挥好二级教代会的智力支持和民主监督的重要作用,团结带领校区教职工进一步凝心聚力、团结拼搏,力争使宣城校区的各项工作再上一个新台阶。</p><p style="TEXT-ALIGN: justify; TEXT-INDENT: 2em">宣城校区党委副书记、管委会常务副主任蒋传东作了题为《增强信心、凝心聚力、攻坚克难、改革创新,为建设高水平、创新型、有特色、环境优美的一流校区而奋斗》的工作报告。报告总结回顾了宣城校区管委会四年多来取得的成绩与存在的问题,强调了“十三五”发展规划的主要目标。</p><p style="TEXT-ALIGN: justify; TEXT-INDENT: 2em">大会听取了《宣城校区工会工作报告》《宣城校区财务工作报告》《宣城校区教职工代表大会实施细则》《宣城校区教职代会执委会规程》《宣城校区2016年度考核工作的实施办法》。</p><p style="TEXT-ALIGN: justify; TEXT-INDENT: 2em">16日上午,11个代表团围绕工作报告进行了分组讨论,大家坦诚交流,各抒己见。随后,主席团会议在宣城校区行政楼221会议室召开。各代表团分别向主席团汇报了讨论、审议情况。主席团会议研讨了《关于宣城校区管委会工作报告的决议(草案)》等。</p><p style="TEXT-ALIGN: justify; TEXT-INDENT: 2em">在当天下午举行的大会闭幕式上,与会代表表决通过了《关于宣城校区管委会工作报告的决议》《关于宣城校区工会工作报告的决议》《关于宣城校区财务工作报告的决议》《关于批准<宣城校区教职工代表大会实施细则><宣城校区教职工代表大会执行委员会工作规程>的决议》《关于批准<宣城校区2016年度考核工作的实施办法>的决议》。会议通过了《宣城校区教职代会执委会选举产生办法》《宣城校区工会委员会选举产生办法》,通过总监票人、监票人和计票人名单。随后,与会代表选举产生了宣城校区教职代会执委会,换届选举产生了宣城校区工会委员会。</p><p style="TEXT-ALIGN: justify; TEXT-INDENT: 2em">蒋传东在闭幕词中表示,校区党委将致力把握校区建设发展和稳定的大局,把每一个教职员工的利益维护好,改善办学条件,努力营造和谐氛围,不断提高服务师生水平,促进宣城校区向更高水平发展。希望各位代表不仅要把代表当作一种身份,更要当成一种责任,做好各项规章、制度、政策的建设者、完善者和宣传者、维护者;希望新当选的工会委员会努力工作,创造业绩,心系教职员工,切实做好服务工作,创新教职工文体活动方式,办好校区“职工之家”,使宣城校区永葆生机和活力;希望校区全体教职工群策群力、与时俱进、开拓创新,为宣城校区更加美好的明天而努力奋斗。</p><p style="TEXT-ALIGN: justify; TEXT-INDENT: 2em">宣城校区第一届一次教职工代表大会暨第一届一次工会会员代表大会的召开,不仅标志着校区向规范办学制度迈出了重要一步,同时也是校区在推进民主办学、民主管理进程中的历史性跨越,对于宣城校区未来的发展建设具有十分重要的意义。</p><p style="TEXT-ALIGN: justify; TEXT-INDENT: 2em"> </p><p style="TEXT-ALIGN: center"><img title="20161220140336666058.png" alt="宣城校区教代会.png" src="/uploadfile/image/20161220/20161220140336666058.png"/></p><p><?xml:namespace prefix="o" ns="urn:schemas-microsoft-com:office:office"><o:p> </o:p></?xml:namespace></p> <div class="bk10"></div>
<div style=" text-align:right;">
(徐姗姗/文 余刘琅/图) <br />
</div>
<div class="bk10"></div>
<div class="content_editors" style="text-align:right;">编辑:周慧</div>
<!--内容关联投票-->
</div>获取新闻主体内容的方法如下,参数url传入新闻的链接,使用键值对的方式存储获取到的标题、日期、作者、摄影、编辑以及新闻内容,由于有的时候这些可能不存在摄影或者其他的,所以做一下判空处理。
def getContent(url):
html = askURL(url)
if (html != ""):
newsContent = ''
output = {'title': '', 'date': '', 'writer': '', 'photoer': '', 'editor': '', 'newsContent': ''}
# 找到新闻标题
title = re.compile(r'<h2>'r'(.*)<br />')
titleList = re.findall(title, html)
if (titleList > 0):
output['title'] = titleList[0]
# 找到新闻发布日期
date = re.compile(r'<span class="t">发布日期:'r'(.*) 字号:')
output['date'] = re.findall(date, html)[0]
# 找到新闻作者
writer = re.compile(r'('r'(.*)/文')
writerList = re.findall(writer, html)
if (len(writerList) > 0):
output['writer'] = writerList[0]
# 拍照作者
photoer = re.compile(r' 'r'(.*)/图)')
photoerList = re.findall(photoer, html)
if (len(photoerList) > 0):
output['photoer'] = photoerList[0]
# 文章编辑
editor = re.compile(r'编辑:'r'(.*)</div>')
editorList = re.findall(editor, html)
# print 'editor大小='+editorList
if (len(editorList) > 0):
output['editor'] = editorList[0]
# 找到新闻主体所在的标签
findDiv = re.compile(r'<div id="artibody" class="content f16">'
r'(.*)<div style=" text-align:right;">', re.S)
div = re.findall(findDiv, html)
if len(div) != 0:
content = div[0]
# print content
newsContent = re.sub(r'<p.*?>', '', content) # 去掉段落开头的<p>标签
if newsContent.find('<img') > 0:
newsContent = re.sub(r'<img.*?src="', '', newsContent)
newsContent = re.sub(r'jpg".*?/>', 'jpg', newsContent)
newsContent = re.sub(r'</p>', '\n', newsContent) # 取出掉段落末尾的</p>标签
labels = re.compile(r'<.*?>', re.S) # 去除文章中的标签
newsContent = re.sub(labels, '', newsContent)
newsContent = re.sub(r' ', '', newsContent)
# print newsContent
output['newsContent'] = newsContent
return output
return ""5、最后数据拿到了就是存放在数据库了
# 保存数据到数据库
# SQL 插入语句
def insertData(date, title, content, writer, photoer, editor, url):
sql = """INSERT INTO mainNews(date, title, content, writer, photoer, editor, url)
VALUES (%s, %s, %s, %s, %s, %s, %s)"""
print '准备插入数据'
try:
# 执行sql语句
cursor.execute(sql, (date, title, content, writer, photoer, editor, url))
# 提交到数据库执行
db.commit()
print '插入成功'
except: # Rollback in case there is any error
print '插入失败'
db.rollback() # 关闭数据库连接注意一定要统一编码方式“utf-8”,python最头痛的就是乱码问题了,加上现在网页编写有的还是“gb2312”,所以做好入坑准备吧。
最后附上“工大要闻”共100页的数据截图
附上源代码:
# -*- coding: utf-8 -*-
import os
import re
import urllib2
import sys
import MySQLdb
reload(sys)
sys.setdefaultencoding('utf8')
# 打开数据库连接
db = MySQLdb.connect("localhost", "root", "", "hfutnews", charset='utf8')
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# 得到页面全部内容
def askURL(url):
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
try:
request = urllib2.Request(url, headers=headers) # 发送请求
response = urllib2.urlopen(request) # 取得响应
html = response.read() # 获取网页内容
# print html
html = html.encode('utf-8', 'ignore') # 将unicode编码转为utf-8编码
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
html = ""
if hasattr(e, "reason"):
print e.reason
html = ""
return html
# 得到正文
def getContent(url):
html = askURL(url)
if (html != ""):
newsContent = ''
output = {'title': '', 'date': '', 'writer': '', 'photoer': '', 'editor': '', 'newsContent': ''}
# 找到新闻标题
title = re.compile(r'<h2>'r'(.*)<br />')
titleList = re.findall(title, html)
if (titleList > 0):
output['title'] = titleList[0]
# 找到新闻发布日期
date = re.compile(r'<span class="t">发布日期:'r'(.*) 字号:')
output['date'] = re.findall(date, html)[0]
# 找到新闻作者
writer = re.compile(r'('r'(.*)/文')
writerList = re.findall(writer, html)
if (len(writerList) > 0):
output['writer'] = writerList[0]
# 拍照作者
photoer = re.compile(r' 'r'(.*)/图)')
photoerList = re.findall(photoer, html)
if (len(photoerList) > 0):
output['photoer'] = photoerList[0]
# 文章编辑
editor = re.compile(r'编辑:'r'(.*)</div>')
editorList = re.findall(editor, html)
# print 'editor大小='+editorList
if (len(editorList) > 0):
output['editor'] = editorList[0]
# 找到新闻主体所在的标签
findDiv = re.compile(r'<div id="artibody" class="content f16">'
r'(.*)<div style=" text-align:right;">', re.S)
div = re.findall(findDiv, html)
if len(div) != 0:
content = div[0]
# print content
newsContent = re.sub(r'<p.*?>', '', content) # 去掉段落开头的<p>标签
if newsContent.find('<img') > 0:
newsContent = re.sub(r'<img.*?src="', '', newsContent)
newsContent = re.sub(r'jpg".*?/>', 'jpg', newsContent)
newsContent = re.sub(r'</p>', '\n', newsContent) # 取出掉段落末尾的</p>标签
labels = re.compile(r'<.*?>', re.S) # 去除文章中的标签
newsContent = re.sub(labels, '', newsContent)
newsContent = re.sub(r' ', '', newsContent)
# print newsContent
output['newsContent'] = newsContent
return output
return ""
# 根据类别按顺序命名文件
def saveFile(labelName, date, fileNum):
dirname = "news"
# 若目录不存在,就新建
if (not os.path.exists(dirname)):
os.mkdir(dirname)
labelName1 = labelName.encode('gbk', 'ignore')
labelpath = dirname + '\\' + labelName1
if (not os.path.exists(labelpath)):
os.mkdir(labelpath)
path = labelpath + "\\" + date + "-0" + str(fileNum) + ".txt" # w文本保存路径
printPath = dirname + "\\" + labelName.encode('utf-8', 'ignore') + "\\" + date + "-0" + str(
fileNum) + ".txt" # w文本保存路径
print "正在下载" + printPath
# path=path.encode('gbk','utf-8')#转换编码
f = open(path, 'w+')
return f
# 保存数据到数据库
# SQL 插入语句
def insertData(date, title, content, writer, photoer, editor, url):
sql = """INSERT INTO mainNews(date, title, content, writer, photoer, editor, url)
VALUES (%s, %s, %s, %s, %s, %s, %s)"""
print '准备插入数据'
try:
# 执行sql语句
cursor.execute(sql, (date, title, content, writer, photoer, editor, url))
# 提交到数据库执行
db.commit()
print '插入成功'
except: # Rollback in case there is any error
print '插入失败'
db.rollback() # 关闭数据库连接
# 得到正文的URL,读取正文,并保存
def getURL(nurl):
text = ''
html = askURL(nurl)
# print html
findDiv = re.compile(r'<li><span class="rt">(.*?) target="_blank" style="" >', re.S)
findTime = re.compile(r'(.*)</span>')
findTitle = re.compile(r'title="(.*)"')
findURL = re.compile(r'<a href="(.*)" title')
# findLabel = re.compile(r'<h3.*?</span>(.*?)</h3>')
# fileNum = 0
# list = re.findall(findDiv, html)
# print list[0]x
# labelName = re.findall(findLabel, html)[0]
for info in re.findall(findDiv, html):
# print info
time = re.findall(findTime, info)[0]
# print time
title = re.findall(findTitle, info)[0]
url = re.findall(findURL, info)[0] # 获取新闻正文的链接
url = 'http://news.hfut.edu.cn' + url
print time + ' ' + title + ' ' + url
try:
text = getContent(url)
insertData(text['date'], text['title'], text['newsContent'], text['writer'], text['photoer'],
text['editor'], url)
# text = {'title': '', 'date': '', 'writer': '', 'photoer': '', 'editor': '', 'newsContent': ''}
except urllib2.URLError, e:
if hasattr(e, "reason"):
print "抓取错误" + url, e.reason
except Exception, e:
print "抓取错误" + url, e
# print labelName + '...' + text['date'], text['title'], text['newsContent'], text['writer'], text['photoer'],text['editor']
# 如果新闻内容长度大于100,保存新闻标题和正文
# fileNum = fileNum + 1
# f = saveFile(labelName, time, fileNum)
# f.write(text)
# f.close() # 抓取新闻标题、类别、发布时间、url,并建立相应的文件,存到相应的类别文件夹中
def getNews(url, begin_page, end_page):
for i in range(begin_page, end_page + 1):
nurl = url + str(i) + ".html"
print '----------开始打印第' + str(i) + '页---------------'
# 获取网页内容
getURL(nurl)
db.close()
# 接收输入类别、起始页数、终止页数
def main():
url = 'http://news.hfut.edu.cn/list-1-'
begin_page = int(raw_input(u'请输入开始的页数(1,):\n'))
end_page = int(raw_input(u'请输入终点的页数(1,):\n'))
getNews(url, begin_page, end_page)
main()















 1101
1101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









