







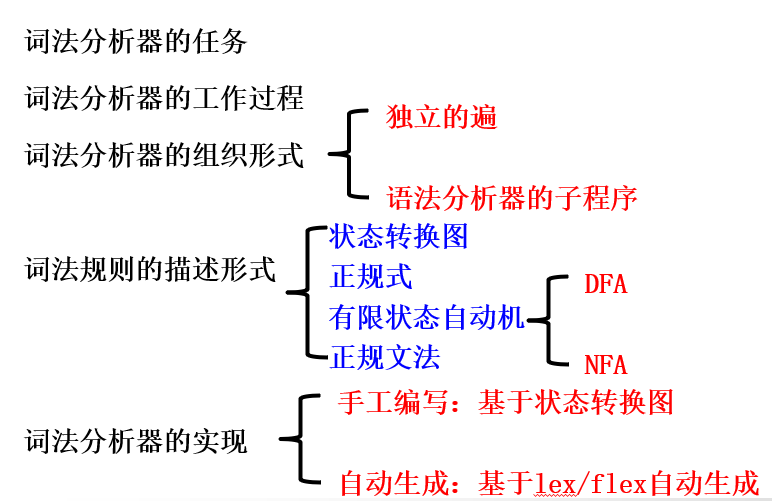
一、词法分析器的任务
功能(任务):用于检查单词是否正确。
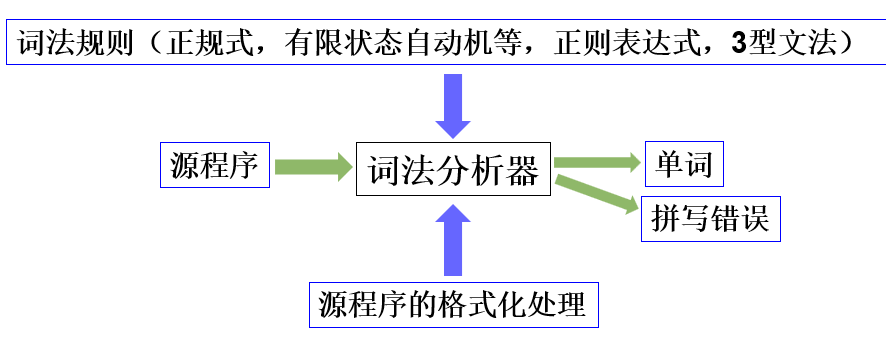
1、单词(用二元组表示{单词种类编号,单词属性值})
以二元组的形式,若存在文件中,形成源程序内码文件
| 单词类型 | 种类编号方式 | 属性值(单词的语义) |
| 关键字 | 一种编码/一符一种 | - |
| 标识符 | 一种编码(ID) | 符号表项指针 |
| 运算符 | 一符一种 | - |
| 常数 | 分别编码(整、实、布尔等) | 常数表项指针 |
| 界符 | 一符一种 | - |

一种编码:对一类的单词类型,使用一个编码进行标注。(例如:用ID表示一个单词的类型为标识符,属性值为单词在符号表的位置)
一符一种:对一类的单词类型中,每一个字符都有专属的编码。(例如:对于关键字类型,for的编码就是for;if的编码就是if)
分别编码:用于常数类型的编码方式,每一个常数类型都有一个编码。(例如:整数的编码为int,浮点数的编码为:float,布尔值的编码为Boolean,属性值为常数表的地址)
2、词法分析器的构造方式
- 词法分析器作为语法分析器的子程序。
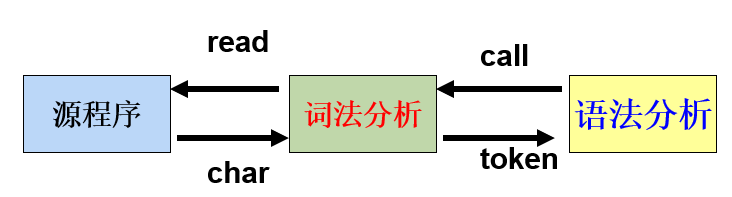
优点:编译器结构清晰,不生成内码文件。
- 词法分析器作为独立的遍。
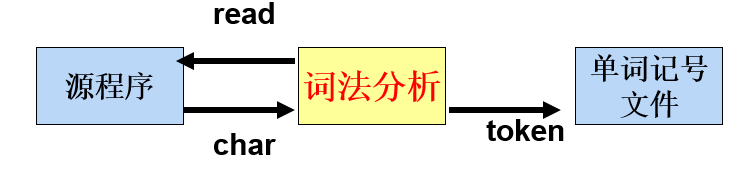
优点:不是任何程序的子程序,独立的完成一遍。
缺点:需要保存单词符号文件,会生成内码文件。
3、词法分析器的设计
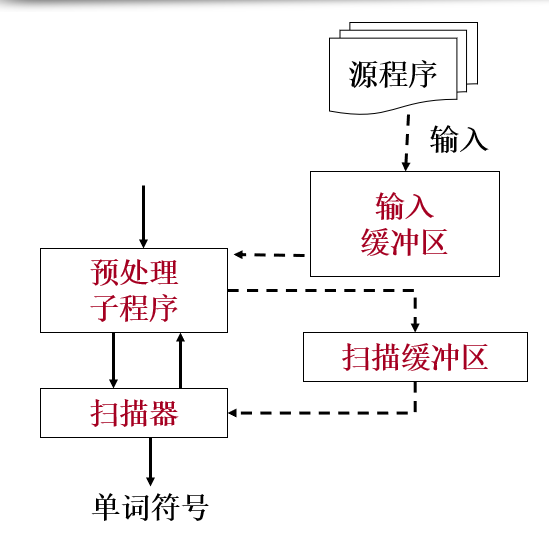
3.1 预处理器(输入、预处理)

读入:read() ,>>
预处理:删除空白符、制表符、回车符,注释语句等。构造预处理程序。
3.2 扫描器
对预处理的结果进行扫描。其中,对常数、标识符、关键字、运算符的识别使用超前搜索技术。
超前搜索技术:多读几个符号形式,一旦确定识别到的单词之后,需要进行扫描指针回退。
二、词法规则描述工具
1、状态转换图

- 结点:代表一个状态,用圆圈表示。
- 弧:状态之间的关系。
- 弧上标记:代表输入的字符。
- 两个圆圈+* 的结点:代表这个状态转换图的终态,只有在终态允许退出。
2、递归下降分析法的代码编写
2.1)函数定义:


2.2)代码编写:


3、正规表达式与有限自动机
状态转换图,适用于手工编写词法分析器。
为了词法分析器的自动生成,需要将转换图概念化,即:正规表达式、有限自动机。
1)正规表达式
正规表达式,又称正规式。同状态转换图一样,是用来描述词法规则的。
正规集:基于某个正规式所描述的规则的语言的集合。


总结:一个属于字符表或者字母表的字符(包含 ɛ 和 ɸ )是正规式,通过连接运算、或运算、闭包运算组成的字符串也是正规式。
例子:

正规式的等价性:若两个正规式所表示的正规集相同,可以认为二者等价。
常见问题:1、给正规式,写出它的正规集,或描述这个语言。
2、给正规集,或者一个语言的描述,写出正规式。
2)有限自动机
2.1)确定有限自动机(DFA)
M =(S,∑,δ,S0 ,F)
- S:有限的状态集,包含了自动机中所以的状态。
- ∑:有穷的字符集,每一个元素对应一个输入字符。
- δ:一种单值映射,s状态,输入终结符a(不包含 空字),下一个状态为s'。即:δ(s,a) = s' 。
- S0 :初态,只有一个。
- F:终态集,允许为空。
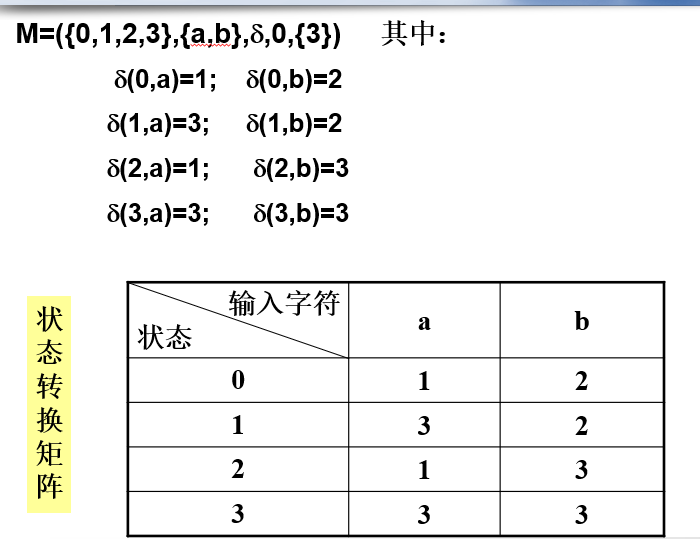
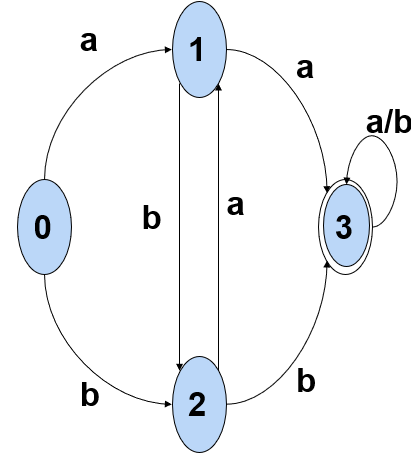
常见问题:状态转换图 与 DFA 的转换。
2.2)不确定有限自动机(NFA)
M =(S,∑,δ,S0 ,F)
- S:有限的状态集,包含了自动机中所以的状态。
- ∑:有穷的字符集,每一个元素对应一个输入字符。
- δ:一种多值映射,s状态,输入终结符a(包含 空字),s'为S的子集。即:δ(s,a) = s' 。(不同于DFA)
- S0 :初态集,非空。(不同于DFA)
- F:终态集,允许为空。
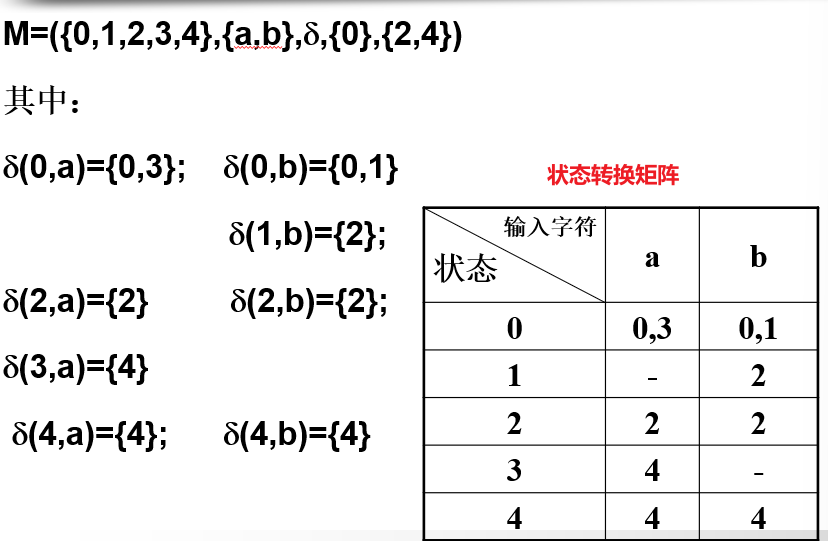
2.3)DFA与NFA的区别
- 初态区别S:DFA只有一个初态,NFA至少有一个初态。
- 转换函数δ:DFA中,一个状态的后继状态只有一个,而NFA允许有多个;
DFA中,输入符号只能是符号集的元素;而NFA是符合集闭包的元素。
2.4)DFA和NFA的等价性(NFA => DFA的方法)
- 引入新的 初态X和终态Y。(保证初态的唯一性)
- 解弧,利用替换规则将DFA中弧上标记字改为输入表中的符号。
- 子集法确定化,利用子集法对NFA进行确定化。(此时已经转换为 DFA)
- 化简,将DFA的状态最简化。
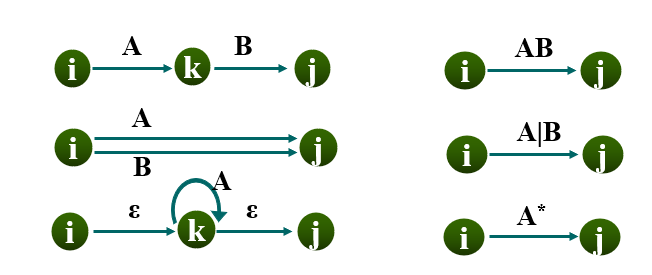
替换规则:
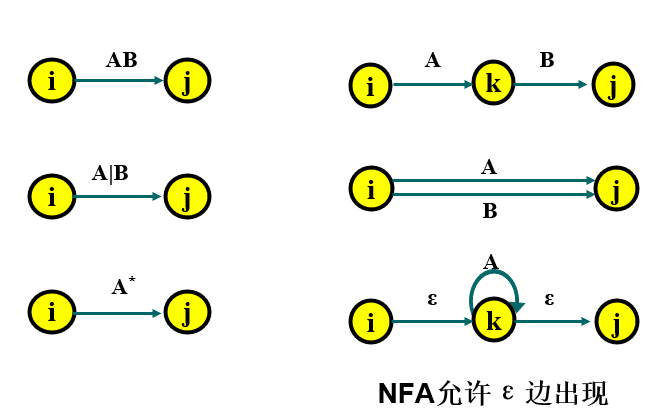
子集法:
两个计算:集合 I 的 ɛ 闭包: ɛ_clousure(I); 自身状态 + 每一个状态的 ɛ 后继状态。
集合 I 的 a 后继状态集 J 的 ɛ 闭包:Ia = ɛ_closure(J);
步骤:
- 构造状态转换矩阵。(K+1列,K为输入符号表的大小)
| I | Ia | Ib | ....... |
| 初态的ɛ 闭包 即:ɛ_clousure(X) | 计算得到状态集 | 计算 | ....... |
| 若有新的状态集,则添加 | 计算 | 计算 | ....... |
| 重复,直到无新添加的集合。 |
- 将状态转换矩阵视为状态转换表,重新编号构造DFA。首行首列为DFA的初态,含有原终态的子集为DFA的终态。

化简:
- 将终态和非终态分开,划分成两个集合。
- 对每一个子集进行检查,若其某个输入字符的后继集合中的元素 分属于两个子集,则这个子集可以进行再划分。
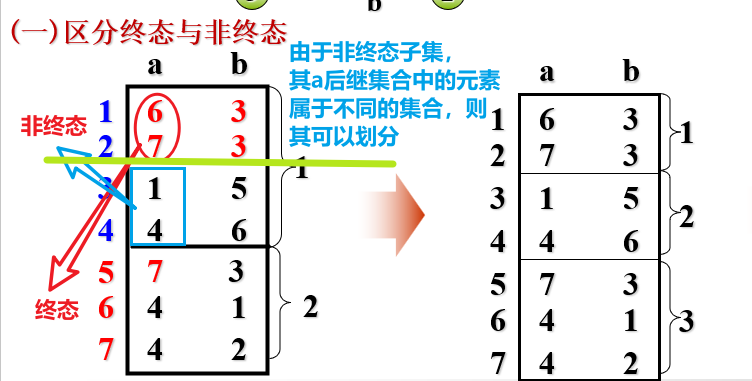
常见问题:NFA => DFA
3)正规式与FA的等价
- 引入新的初态X 和 终态Y,并用标有 ɛ 的弧连接原来的初态与终态。
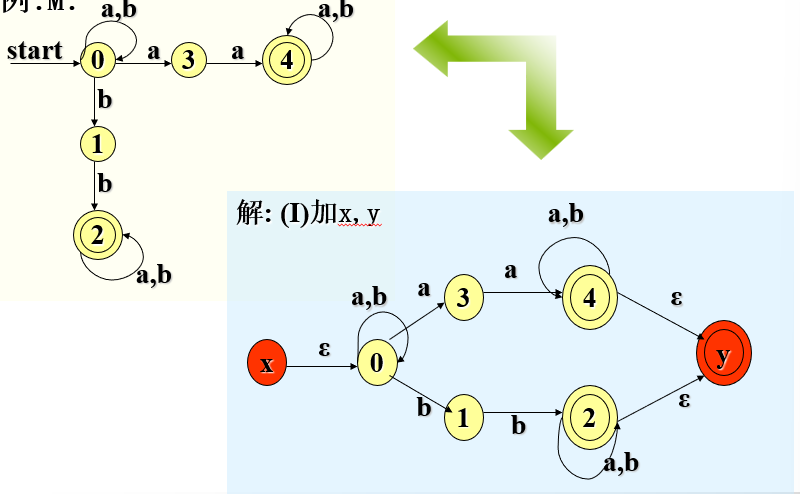
- 按照规则消弧。
- 直到状态图只剩下X和Y状态,二者之间的标注即为正规式。

3、正规文法(左线性文法、右线性文法)
等价性:无论是正规式、正规文法还是自动机,只要满足其描述的词法规则的语言集合相等,则称它们是等价的。
正规文法:3型文法,产生式右部只能有一个非终结符。非终结符要么在终结符串的右部(右线性文法),要么在终结符串的左部(左线性文法)。
FA与正规文法之间的转化:重点是起始符对应的是初态(右线性文法)还是终态(左线性文法)。
1)右线性文法 -> NFA
- 引入一个终态。 F={ f } (区别)
- 初态,对应文法的起始符。 S0 = S
- 输入字符集,对应文法的终结符集。 ∑ = Vt
- 状态集,对应文法的非终结符集。S = Vn ∪ { f }
- 映射函数δ:(区别)
- 若 A -> a, a ∈ Vt ∪ { ɛ }, 则 δ(A,a) = f
- 若 A -> aA1| aA2 | ......| aAk , 则 δ(A,a) = { A1,A2,A3,...... ,Ak }

例题:
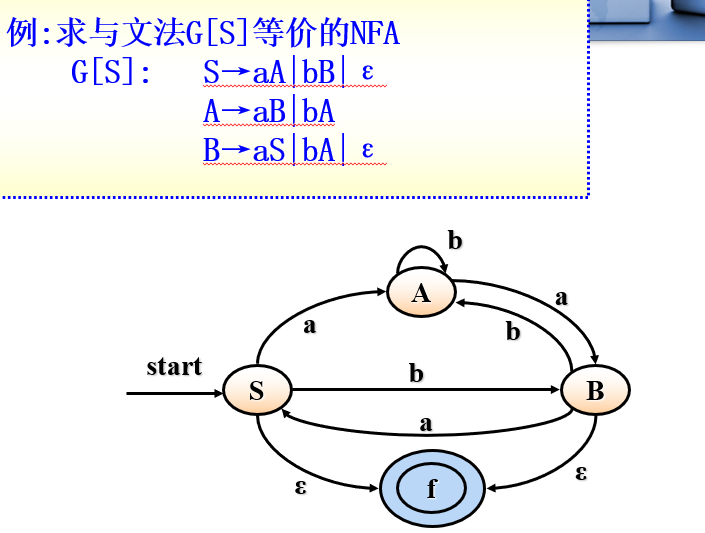
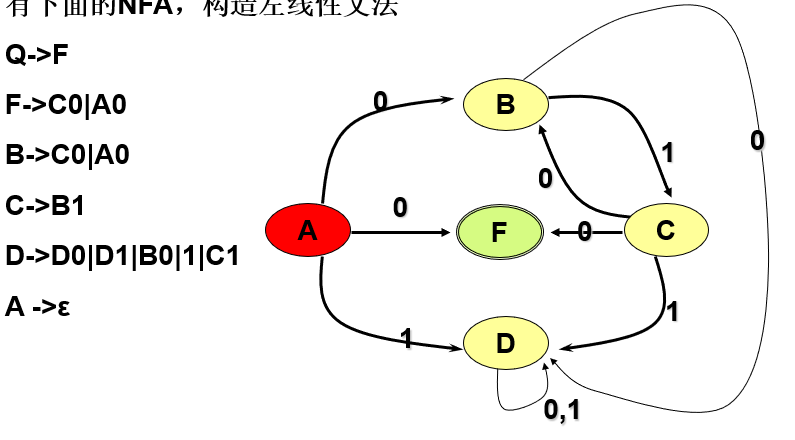
2)左线性文法 -> NFA
- 引入新的初态。S0 = Q。(区别)
- 终态,对应起始符。F = { S }
- 输入符号表,对应终结符集合。 ∑ = Vt
- 状态集合,对应非终结符。 S = Vn ∪ { Q }
- 映射函数δ:(区别)
- 若 A -> a, a ∈ Vt ∪ { ɛ }, 则 δ(Q,a) = A
- 若 A1 -> Aa, A2 -> Aa ...... Ak -> Aa , 则 δ(A,a) = { A1,A2,A3,...... ,Ak }
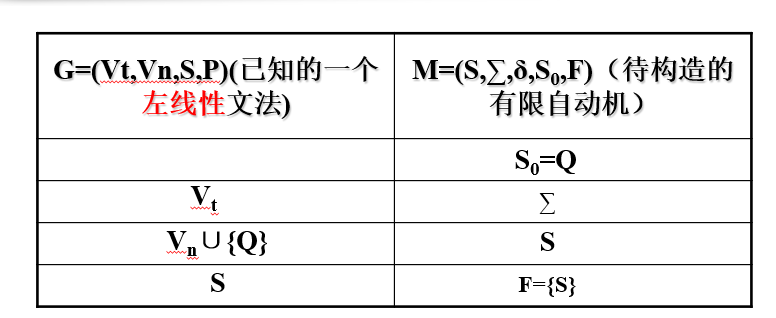
例题:

3)DFA -> 右线性文法
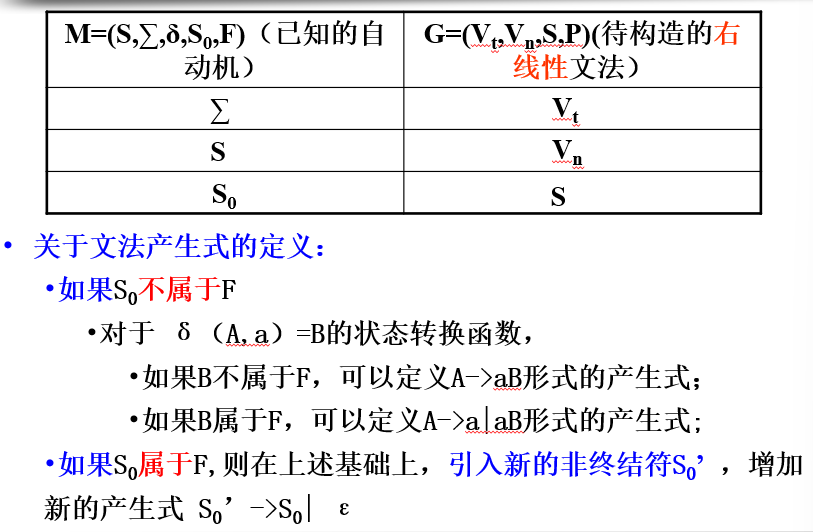
例题:
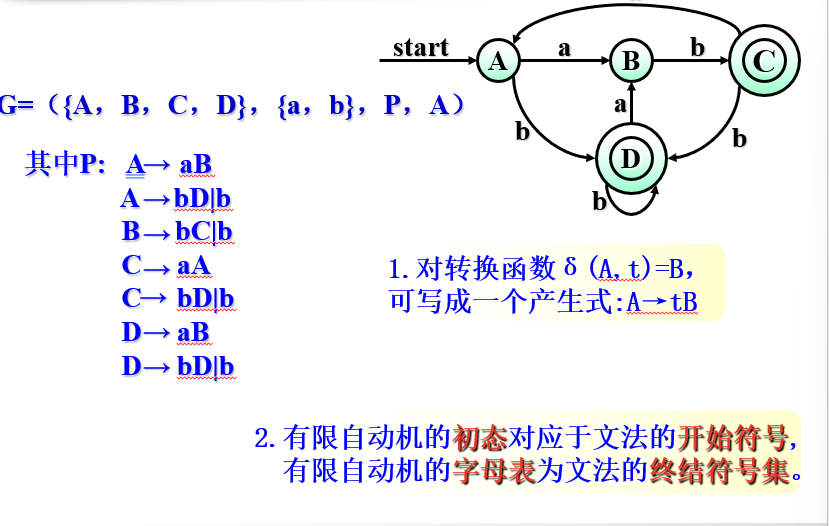
4)DFA -> 左线性文法
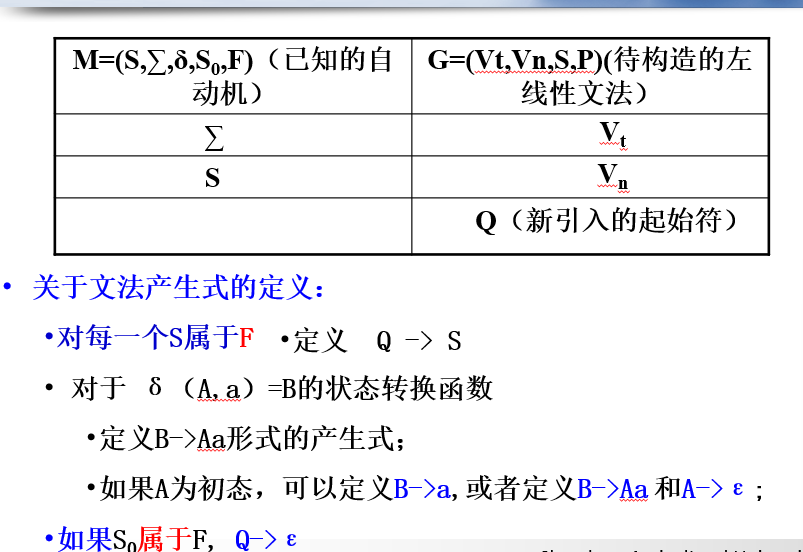
例题:
三、总结
-------------------------------------------------------END-------------------------------------------------------------------
任意门:
编译原理------语法分析器(一) 自上而下的推导(LL1文法)-CSDN博客
编译原理------语法分析(二)自下而上的归约(算符优先,LR分析)-CSDN博客















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









