






多线程
多线程的意义
多线程是为了同步完成多项任务,不是为了提高运行效率(强调!),而是为了提高资源使用效率来提高系统的效率。
多线程的实现方法
继承Thread类和实现Runnable接口
继承Thread类有一个缺点就是单继承,而实现Runnable接口则弥补了它的缺点,可以实现多重继承(不是多继承!不是多继承!不是多继承!)。
继承Thread类必须如果产生Runnable实例对象,就必须产生多个Runnable实例对象,然后再用Thread产生多个线程;而实现Runnable接口,只需要建立一个实现这个类的实例,然后用这一个实例对象产生多个线程。即实现了资源的共享性
下面简单说一下这部分的实现。
public class ThreadsDemo0 {
//跟创建线程一样,只不过创建了之后多次调用而已
public static void main(String[] args) {
//实现Runnable接口
Thread002 t1 = new Thread002("1");
Thread002 t2 = new Thread002("2");
t1.start();
t2.start();
//继承Thread
Threads001 td = new Threads001();
Thread ts1 = new Thread(td,"1号");
Thread ts2 = new Thread(td,"2号");
ts1.start();
ts2.start();
}
static class Threads001 implements Runnable{
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"实现runnable接口线程运行");
}
}
static class Thread002 extends Thread{
public Thread002(String num){
super(num);
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"号继承Thread方法运行");
}
}
}
线程池
线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务。简单来说就相当于把宝贵的资源放到一个池子中;每次使用都从里面获取,用完之后又放回池子供其他人使用。
一般创建线程池,阿里开发手册上是推荐使用ThreadPoolExecutor来创建线程池,这样能够展现出线程池的参数,便于他人能详细了解创建的线程池的属性。
jdk8的文档ThreadPoolExecutor类中可以看出是提供了四种构造方法。
我们这里选择最多参数的那个进行解析
corePoolSize - 核心线程数,即使空闲时仍保留在池中的线程数,除非设置 allowCoreThreadTimeOut
maximumPoolSize - 池中允许的最大线程数,核心线程+临时线程数
keepAliveTime - 临时线程执行完任务时,在终止前等待新任务的最大时间。
unit - keepAliveTime参数的时间单位
workQueue -线程的 队列策略
threadFactory - 执行程序创建新线程时使用的工厂
handler - 线程池超过maximumTime,并且workqueue已经打满时或线程已关闭时执行的拒绝策略
 线程池创的流程大致如此,需要注意几点
线程池创的流程大致如此,需要注意几点
1、线程池创建时不会立即创建线程,只有首次任务提交后,才会创建线程。
2、如果有新任务,当前线程数大于corePoolSize且当前线程数小于MaximumPoolSize时,优先调用闲置线程,若没有则开启新线程
3、若当前线程大于maximunPoolSize,执行拒绝策略
线程的队列策略:
SynchronousQuene:不缓存任务的阻塞队列,生产者放入一个任务必须等到消费者取出这个任务。也就是说新任务进来时,不会缓存,而是直接被调度执行该任务,如果没有可用线程,则创建新线程,如果线程数量达到maxPoolSize,则执行拒绝策略。
ArrayBlockingQueue:FIFO,有界 。需要注意的是:当任务持续以平均提交速度大余平均处理速度时,会导致队列无限增长问题,导致内存等资源溢出
LinkedBlockingQueue:基于链表,FIFO,无界。 当任务持续以平均提交速度大余平均处理速度时,会导致队列无限增长问题,导致内存等资源溢出
PriorityBlockingQueue:无界阻塞队列,直到系统资源耗尽。默认情况下元素采用自然顺序升序排列。也可以自定义类实现compareTo()方法来指定元素排序规则,或者初始化PriorityBlockingQueue时,指定构造参数Comparator来对元素进行排序。
线程池的拒绝策略:(1. 线程池已经被关闭;2. 任务队列已满且maximumPoolSizes已满)
SynchronousQueue 无缓冲同步队列,直接提交,每个插入操作必须等待另一个线程相应的删除操作,反之亦然。适合运行在一个线程中的对象必须与在另一个线程中运行的对象同步,以便交付一些信息,事件或任务
LinkedBlockingQueue 可选择性无界阻塞队列,可通过构造函数来进行设置(见补充),新元素插入队列的尾部,队列检索操作获取队列头部的元素。链接队列通常具有比基于阵列的队列更高的吞吐量,但在大多数并发应用程序中的可预测性能较低
PriorityBlockingQueue 无界队列 它没有限制,在内存允许的情况下可以无限添加元素;它又是具有优先级的队列,是通过构造函数传入的对象来判断,传入的对象必须实现comparable接口
ArrayBlockingQueue 有界阻塞队列 有助于防止系统资源耗尽,但队列大小和maximumPoolSize需要相互折衷:使用大型队列和小型池可以最大限度地降低 CPU 使用率、操作系统资源和上下文切换开销,但是可能导致人工降低吞吐量
线程池的使用
能够快捷使用的五种线程池

newSingleThreadExecutor:核心线程与最大线程都是只有一个,其他的参数已经没有什么效果了。一个单线程的线程池,可以用于需要保证顺序执行的场景,并且只有一个线程在执行。
newFixedThreadPool:一个固定大小的线程池,可以用于已知并发压力的情况下,对线程数做限制。

newCachedThreadPool:核心线程为0,临时线程无限(integer的最大值),线程运行完毕后,60s的存活时间 一个可以无限扩大的线程池,比较适合处理执行时间比较小,各自相对独立的任务。

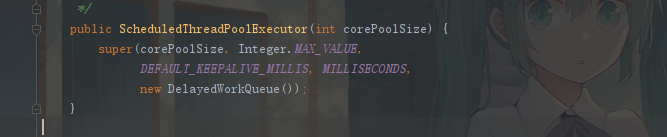
newScheduledThreadPool:输入核心线程数,队列无限大(integer的最大值),DelatWorkQueue保证了可以延时启动,定时启动的线程池,适用于需要多个后台线程执行周期任务的场景。
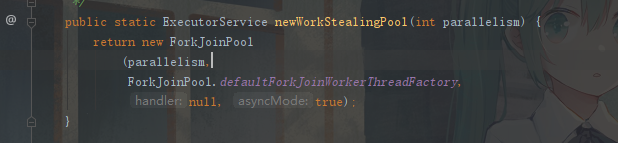
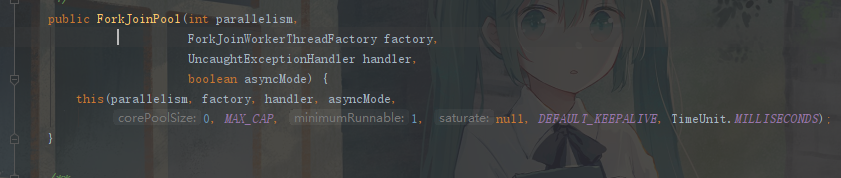
newWorkStealingPool:一个拥有多个任务队列的线程池,可以减少连接数,创建当前可用cpu数量的线程来并行执行,适合使用在很耗时的操作,但是newWorkStealingPool不是ThreadPoolExecutor的扩展,它是新的线程池类ForkJoinPool的扩展,但是都是在统一的一个Executors类中实现(这部分跟其他几个线程有些许区别,大致就是将任务按照工作线程均分。然后先工作完的线程去帮助没处理完的线程工作。以实现最快完成工作,具体实现代码示例
)
然后就是一般线程池的使用(推荐)

虽然有已经定义好的几个线程池供人使用,但是在阿里开发手册中,还是推荐大家使用这种自己定义好的方式来使用线程,一来可以很明显的看到各个参数,了解当前这个线程池的基本属性;二来更容易理解线程池的运行规则,避免资源耗尽的风险。当然具体情况还是看实际开发情况,不推荐但是并不是禁止使用(存在即合理嘛)















 77
77











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









