







YOLO5face人脸检测模型论文和代码简析
YOLO5Face论文发出以后,对YOLO5Face论文进行分析的文章较少,就想写一篇对YOLO5Face进行分析的文章,主要也是非常喜欢YOLO系列,博主也是刚刚入门人脸检测,写的就是一篇小白文,也第一次写文章,有不正确的地方希望大神们多多指正。
YOLO5Face模型分析
论文及源码下载
论文地址:https://arxiv.org/abs/2105.12931论文我们中国人写的,读起来还是挺顺的。
源码地址:https://github.com/deepcam-cn/yolov5-face
WiderFace地址:WIdeFace
Yolo5Face是深圳神目科技&LinkSprite Technologies(美国)在Yolov5模型基础上进行更新得到的人脸检测模型,在WiderFace上取得了SOTA。
论文创新点
正如论文名字的后半部分Why Reinventing a Face Detector?论文将人脸检测视为一般的目标检测任务,所以作者以现在比较热门的YOLOv5模型为基础,辅助以人脸特性,得到一个新的人脸检测器。
论文创新点:
-
在YOLOv5网络中添加五个人脸关键点回归,回归的损失函数用的是Wing loss。(类比MTCNN、RetinaFace)
MTCNN中使用L2损失作为5个人脸关键点的回归损失,但是L2对小的误差并不敏感,为了克服这个问题,Wing-Loss出现了。
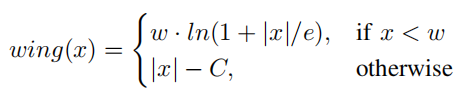
可以看到Wing-loss是一个分段的复合损失函数,在训练初期误差较大时用L1损失,在训练后期误差相对小,用一个具有偏移量的对数函数。wing-loss的优点我也不能很好的论述清楚,感兴趣的可以去看这篇博客。https://blog.csdn.net/john_bh/article/details/106302026
作者将五个人脸关键点回归损失加入到总的损失函数中去后,作者将这部分损失函数称为LossL并给这部分损失加上权重,加上YOLOv5本身的损失函数LossO,总的损失函数为Loss(s)。

作者在配置文件里面写的:landmark: 0.005 # landmark loss gain,那应该这个权重就是0.005,具体的代码我还没有看到,看到以后如果不对再改。 -
用Stem模块替代网络中原有的Focus模块,提高了网络的泛化能力,降低了计算复杂度,同时性能也没有下降。
Focus模块出来的时候,就有人说Focus模块比较鸡肋。可能是作者想改掉这部分又不想大改v5的整体模型,所以设计出一个相对更好的模块。
Stem模块的图示中虽然都是用的CBS,但是看代码可以看出来第2个和第4个CBS是1x1卷积,第1个和第3个CBS是3x3,stride=2的卷积。配合yaml文件可以看到stem以后图像大小由604x640变成了160x160。
class StemBlock(nn.Module):
def __init__(self, c1, c2, k=3, s=2, p=None, g=1, act=True):
super(StemBlock, self 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7613
7613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









