







背景:项目有一个需求是这样的,针对某个拍摄的视频,做压缩导出操作,导出操作支持不同的规格,所以压缩导出的时间各不相同,所以需要做压缩效率的一个专项测试,初步设想需要取得的数据为耗时–规格–时长的一个统计图,比如下面这张图:
痛点:简单的专项可以手动去做,因为数据少,代码结构改变的话维护成本低;但是,项目还在初期阶段,导出规格和底层的压缩算法有可能会变,而且每次执行数据量会很大,手工操作统计数据都要1人/d,而且存在读数错误的风险,所以只能通过自动化的方式执行统计,把时间压缩到只要准备待测资源,然后等待数据执行完成即可。
所以最后得到的是一个csv文件:

然后手动生成一张图表:
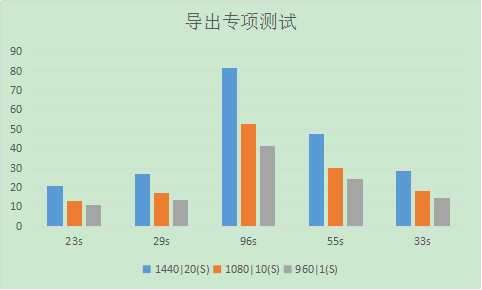
使用:
只需要在我自定义的文件夹内复制一些需要测试的资源,然后在配置一下导出的规格,然后一键执行等待结果就行了,有了结果数据,分析还不简单吗。
物料准备:
- AndroidJuniRunner框架一个
- javacsv.jar第三方库一个
- 导出接口一个
代码结构:
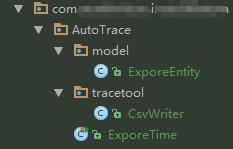
实际运行是运行单元测试哒,主要有3个类:
- ExporeEntity用来定义规格和各种参数,使用的时候只要在@Before实例化一次就行了。
- CsvWriter这就是第三方库
- ExporeTime导出时间的单元测试类
主要代码和思路:
@Before
public void setUp(){
context = InstrumentationRegistry.getTargetContext();
exporeEntity = new ExporeEntity();
}在before准备context和我定义的实体类。
@Test
public void startTest(){
try {
csvWriter = new CsvWriter(exporeEntity.out_csv,',', Charset.forName("GBK"));
ArrayList in_testFile = exporeEntity.getArrayList();
Assert.assertThat("AirTest文件夹内无内容或者资源无效,请检查!!!",in_testFile, Matchers.notNullValue());
HashMap quial_map = exporeEntity.getHashMap();
writeCsvPhoneInfo();
writeCsvTitle(quial_map,csvWriter);
for(int i = 0;i < in_testFile.size();i++){
Log.i("cloudhuan","被测应用共:"+in_testFile.size()+"当前为:"+(i+1));
String in_path = (String) in_testFile.get(i);
String in_path_name = new File(in_path).getName();
Log.i("cloudhuan",in_path+in_path_name);
ArrayList arrayList = new ArrayList();
arrayList.add(in_path_name);
arrayList.add(getVideoSize(in_path));
arrayList.add(String.valueOf(getVideoTotleTime(in_path))+"秒");
for(Object key:quial_map.keySet()){
mheight = (Integer)key;
mbitrate = (int) quial_map.get(mheight);
_start = System.currentTimeMillis();
Log.i("cloudhuan","export begin"+mheight+"|||"+mbitrate);
arComposeUtil = new ArComposeUtil();
arComposeUtil.composeVideo(context,in_path,
exporeEntity.tmp_file, mheight,mbitrate,this,this,this);
Log.i("cloudhuan","export done");
arrayList.add(String.valueOf((System.currentTimeMillis()-_start)/1000.0));
arrayList.add(getVideoSize(exporeEntity.tmp_file));
SystemClock.sleep(1000);
}
writeCsv(arrayList);
}
} catch (Exception e) {
e.printStackTrace();
}finally {
try {
csvWriter.flush();
} catch (IOException e) {
e.printStackTrace();
}
csvWriter.close();
Log.i("cloudhuan","writecsv done");
}
}然后在一个@Test方法执行自动导出列表内的所有资源,每个资源导出N个规格次,并统计生成csv文件,思路是这样的:
- 一个资源对应着N个规格,然后一个资源写csv一行数据,所以文件夹内遍历出所有有效视频(以mp4结尾且长度大于0),然后没一个视频对应着N次循环。
- 写入csv,因为有N个循环,所以列数不定,也需要动态循环扩展csv的列数,所以这里用了一个hashmap来定义规格,然后循环N次来写入数据。
写在最后:
咳咳,好久没写博客了,因为新入职事多,加上也不知道写什么,该学的都学了,剩下的更多是加深理解和实际运用,所以以后会把项目用到的好玩的技术和对项目中实现高效率的实际运用,总结成博客吧!















 117
117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









