







作者:高斌龙,腾讯云Elasticsearch高级开发工程师
1. 背景
在之前的一篇文章"PB级大规模Elasticsearch集群的运维与调优实践"中,指出了在集群每天产生大量分片,并且索引不能删除的情况下,需要对比较老的索引通过配置ILM策略进行Shrink,比如从60分片shrink到5或者10分片,从而从整体上降低集群整体的分片数量,避免集群不稳定现象的发生。
以某个客户的使用场景为例,客户采用按小时创建索引的方式,单日会产生2880个分片,集群运行了一段时间后总的分片数量就达到了10w:
-
索引数量过多:按小时创建索引,单日产生24个索引
-
分片数量过多:单日产生2880个分片
过多的分片带来的影响是比较大的,不仅会影响写入,还会影响master节点处理任务的效率,过多分片的元数据也会占用较多内存,导致master节点出现无法响应的情况:
-
影响1:整点时索引写入掉0
原因:扩容、缩容时需要进行分片搬迁,任务优先级较高,从而影响索引新建以及更新mapping,导致集群无法写入
-
影响2: Master节点处理索引创建任务缓慢

原因:集群分片数太多,Master节点task队列容易产生堆积,且集群meta元数据更新缓慢,影响Master处理任务的效率(任务优先级:IMMEDIATE>URGENT>HIGH>NORMAL)
-
影响3:Master节点 Old GC频繁

原因:集群分片数过多,集群meta元数据占用的内存较多,Master节点不稳定,容易出现无法响应的情况
2. 一般的优化手段
为了解决集群分片数过多,通常的做法就是通过配置索引生命周期策略,定期清理过期的数据,或者去掉副本,甚至拆分集群;但是客户的要求是数据一条也不能删,并且需要保证数据的可靠性、一个业务也只能使用一个集群;所以一般的解决方法解决不了客户的问题,因此针对客户的需求我也制定了一系列的优化措施,给索引的生命周期设置了四个阶段,并分别从降低索引粒度,数据冷备去副本,开启Shrink这几个角度进行了优化,其中Shrink特性最能降低集群分片数,在索引创建超过60天后,进入到Warm阶段,就把索引从60分片,缩到10分片,分片数就降低了83%。

经过这些优化,预期可以把每个月新增的分片数降低到3600,但是运行了一段时间后发现并没有达到预期。
在上述优化方案实施了一段时间后,客户反馈偶尔地收到集群Red的告警,经过排查,发现是Shrink出来的新索引会偶现red,也会出现部分节点负载比较高的情况,最严重的是一部分索引的Shrink任务会卡住,导致每个月新增的分片数并没有下降到预期。
Shrink任务存在的问题:
-
Shrunken索引Red,导致集群Red

-
节点负载不均,部分节点的负载较高,最终影响查询

-
Shrink任务卡住,导致部分索引分片数量未减少

针对这些问题,临时的解决办法是通过python脚本来进行批量处理,但是通过python脚本进行处理的方式毕竟不够通用,所以下定决心去研究ES内核中的Shrink这个特性。
3. 优化Shrink Action
带着碰到的问题去研究源码,也理清了Shrink任务的所有执行步骤,步骤比较多,实现也比较复杂:

之后总结并归纳了Shrink任务的核心步骤,也是最容易出问题的三个步骤:
Step 1. 第一步是选择一个节点,作为将要执行Shrink的节点
Step 2. 第二步把原始索引的分片都移动到选择的节点上,主分片和副本分片均可,只要有一份完整的拷贝就可以
Step 3. 第三步构建一个新的分片数量少的索引,通过别名完成新旧索引的切换,从而达到降低索引分片数的目的。
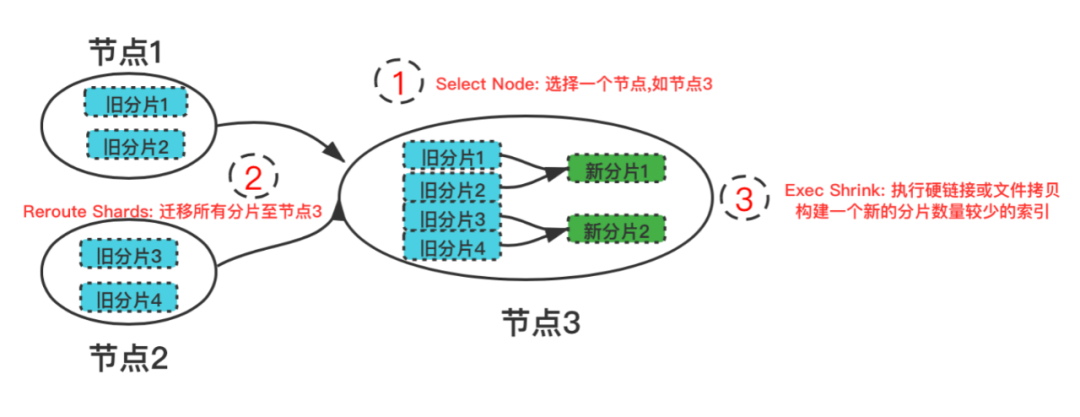
接下来带着已知的问题,逐步去优化Shrink任务的这三个步骤。
3.1 优化Select Node节点选择步骤
3.1.1 从磁盘空间角度优化
在节点选择步骤,原生内核存在以下问题:
-
选择节点时没有考虑磁盘空间水位线DiskThresholdLow阈值,会导致后续RerouteShards步骤卡住
-
多盘节点上不能执行硬链接,只能通过文件拷贝创建Shrunken索引,文件件拷贝的方式势必产生冗余数据,而执行Shrink的节点磁盘空间可能不足,最终会导致Shrunken索引无法初始化而持续Red
因此先从磁盘空间的角度进行优化:
-
选择节点时候选节点磁盘使用率要低于DiskThresholdLow阈值
-
选择节点时候选节点剩余磁盘空间可以容纳2*(Size of all primary shards) + padding
经过对节点选择步骤从磁盘空间角度进行优化,解决了一部分Shrink任务卡住问题以及Shunken索引Red的问题。

相关PR:
https://github.com/elastic/elasticsearch/pull/76206
3.1.2 从节点属性角度优化
在节点选择步骤,原生内核还存在以下问题:
-
欠考虑云的属性:云上集群可以弹性扩容缩容->导致后续RerouteShards步骤卡住
-
欠考虑不同类型的节点属性->导致后续RerouteShards步骤卡住
因此,又从节点属性的角度进行了优化:
-
纵向扩容缩容期间即将剔除掉的旧节点不能被选择
-
Hot->Warm->Cold不同阶段执行Shrink任务,只能选择当前阶段的节点
从节点属性的角度进行的这些优化,又解决了另外一部分Shrink任务卡住的问题。


相关PR:
https://github.com/elastic/elasticsearch/pull/65037 , https://github.com/elastic/elasticsearch/pull/67137
3.1.3 从减少分片移动的角度优化
在解决任务卡住和索引Red问题的过程中,又发现了原生的内核在选择节点时还存在的一个问题:
-
没有考虑减少分片的移动,因为过多的分片移动会消耗系统资源
所以从减少分片移动的角度又进行了优化,优化策略是优先选择本身已经包含当前索引分片的节点,但是还存在按照分片数量还是分片总容量优先的问题。

在90%的场景下,数据在各个分片都是均匀分布的,分片数量最多的节点就是分片总容量最大的节点,这时候选择分片总容量最大的节点是没有问题的;但是仍然需要考虑剩下10%的数据分布不均的场景,经过对比测试,移动较大的分片相对小的分片,在耗时和系统资源消耗上都会高不少,最终确定优先选择分片总容量最大的节点,既减少分片迁移的时间,也降低了系统资源的消耗。
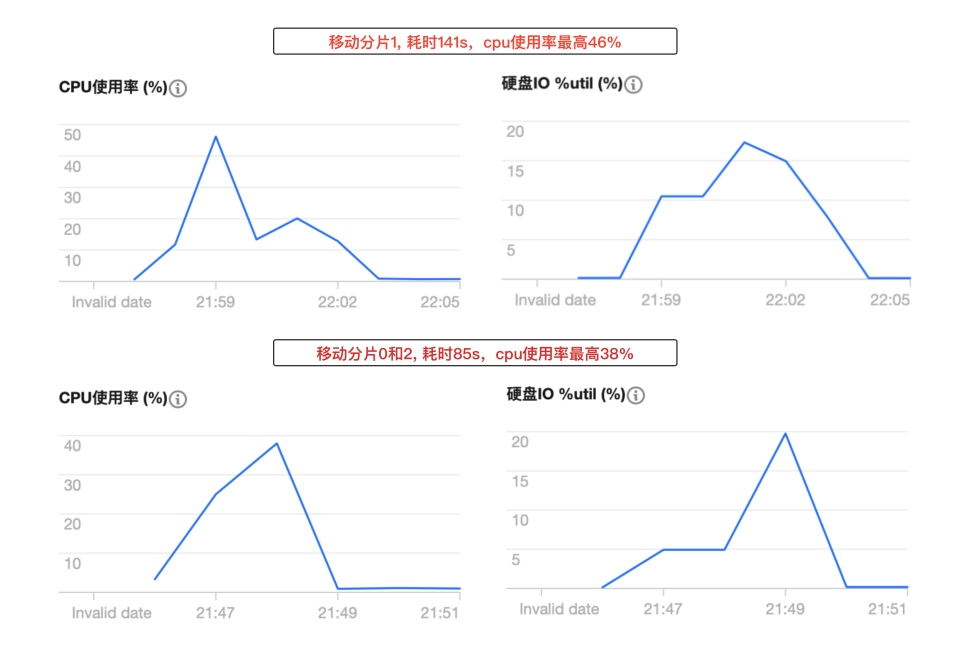
相关PR:https://github.com/elastic/elasticsearch/pull/76206
3.2 优化Reroute Shards移动分片步骤
紧接着是优化第二个步骤,Reroute shards, 这一步是在上一步选择了节点之后,把索引的分片都移动到这个节点上,原生内核在这一步骤存在以下两个问题:
-
欠考虑用户自定义的TotalShardsPerNode属性->导致RerouteShards步骤卡住
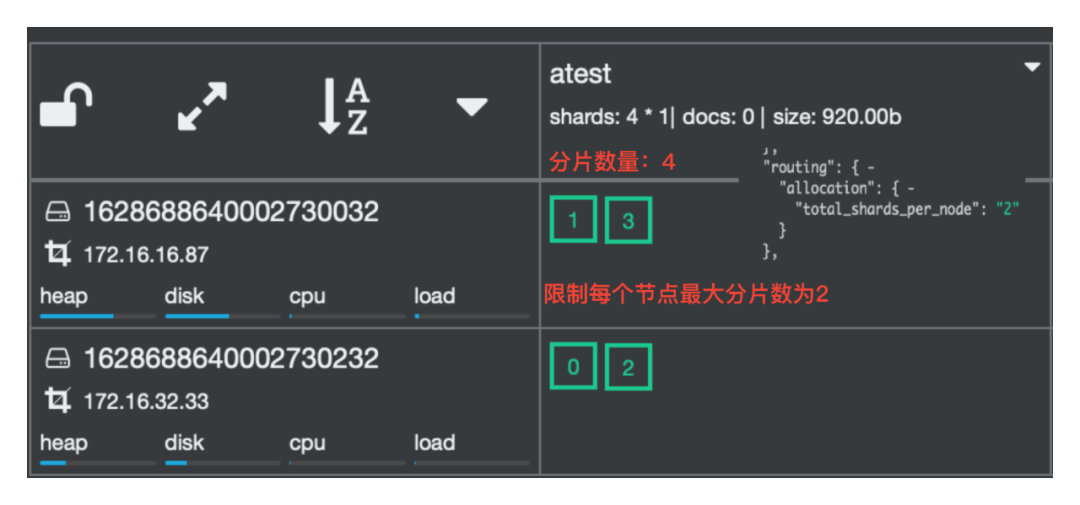
-
缺少检测用户设置的目标分片数量是否合适->导致后续ExecShrink步骤卡住

所以又从索引属性的角度分别对以上问题进行了优化:
-
检测是否可以把原索引的分片都移动到一个节点上,为否则提前终止Shrink任务
-
检测目标分片数量是否是原索引分片数的因子,为否则提前终止Shrink任务
相关PR:https://github.com/elastic/elasticsearch/pull/74219
3.3 优化Exec Shrink步骤
接下来是优化第三个步骤,执行Shrink, 原生内核里,对于要shrink到多少个分片,数量是固定的,比如60个分片,只能选择shrink到10或者20个分片:

但是索引容量有大有小,都shrink到10个分片的话,就会出现分片容量忽大忽小的问题:
 这就不符合我们常说的一个准则,一个分片容量大小在30-50GB时可以获得较好的性能,这样做的原因有很多,总结来说就是分片过大过小都会影响集群性能:
这就不符合我们常说的一个准则,一个分片容量大小在30-50GB时可以获得较好的性能,这样做的原因有很多,总结来说就是分片过大过小都会影响集群性能:
-
分片越大,从本地恢复的时间越长
-
分片越大,Rebalance时间越久
-
分片越大,Segment merge时占用磁盘空间更多、磁盘IO时间越更长
-
分片越大,Update操作容易将磁盘IO打满
-
分片越大,影响节点缓存继而影响查询性能
-
分片大小不均,磁盘使用率、节点负载会不均
-
分片越小,会导致集群分片数量过多并且影响查询性能
在发现了这个问题之后,前期也通过python脚本进行了优化,但是毕竟不能通用,所以决定去优化内核,在这一步骤中,增加了设置基准分片容量大小的参数,计算出最佳的目标分片数:
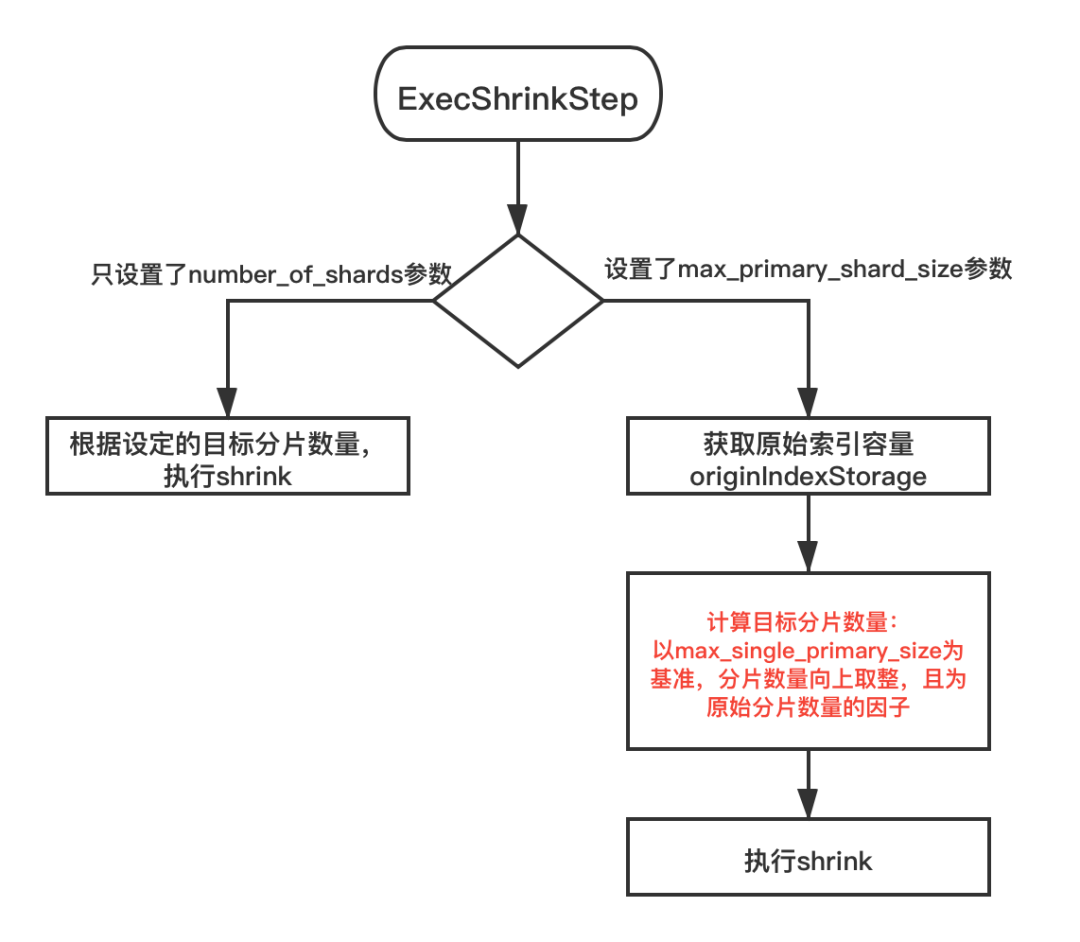
相关PR:
https://github.com/elastic/elasticsearch/pull/67705, https://github.com/elastic/elasticsearch/pull/68502
比如以50GB为基准,不同容量大小的索引Shrink到不同的分片数,从而使得单分片的容量不会超过50GB,大部分的索引都可以保持在30-50GB:

另外一方面,因为客户的业务高峰期持续时间不长,100-500GB的索引居多,所以这个优化还可以进一步降低集群整体的分片数。
从对比测试的结果来看,保持分片在50GB,相比较100GB以上的大分片,分片恢复以及分片迁移的时间都可以降低不少,另外所以这个优化还可以把集群整体的分片数量再次降低10%左右。
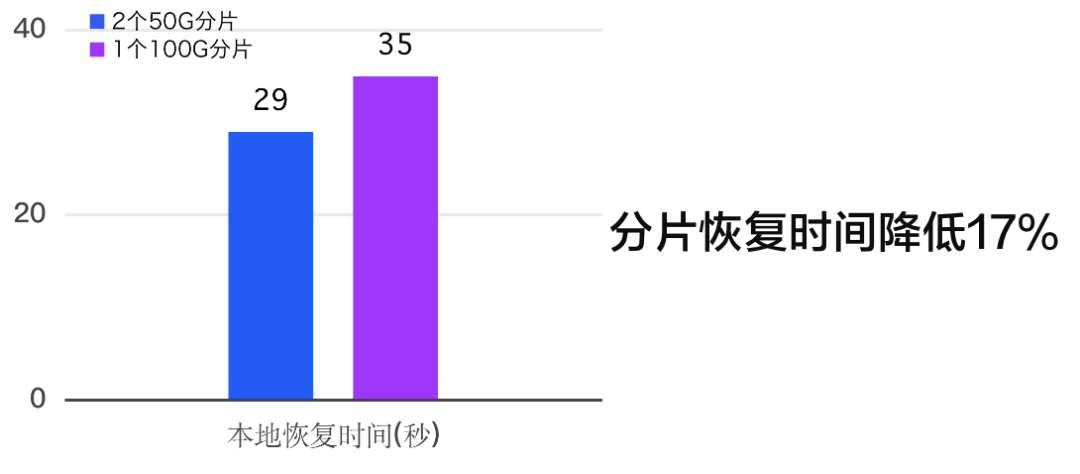


经过上述一系列的优化,整体的优化效果如下:
-
集群的分片数量降低了81%,从而从根本上解决了因为分片数量过多而导致集群不稳定的现象发生
-
解决了Shrink任务自身的一些问题,消除了索引变red的以及卡住的问题,也使得分片数量缓慢增长
-
通过弹性目标分片数量的优化,也使得节点的负载、磁盘使用率更加均衡,进一步提高了集群的稳定性。
经过这次对ILM中的Shrink Action的优化,我总结了解决一些棘手问题的方法,就是要从实际场景出发,去解决核心问题,最重要的是要把想法变成现实。在解决Shrink的问题之后,也尝试去思考怎么从源头避免产生大量分片,而不是出了问题之后再去解决,目前在云上已经实现了分片数量的自动化巡检,并且主动给客户提供改进优化的建议,方便客户快速解决问题。
此外,为了降低索引的使用与运维成本,让索引能够智能的根据业务负载进行自我管理,腾讯云ES也推出了一站式的索引管理解决方案-自治索引,自治索引能够实现分片数动态调整,相比原生ES写入和集群稳定性更优。通过多种统计算法,自治索引能够识别周期性波动、写入毛刺等用户写入场景,并且和节点数量关联,保障分片数合理设置,避免写入拒绝,并且收敛整个集群的分片数,提升集群稳定性。在易用性方面,相比原生ES,自治索引只需一条命令完成索引创建和管理,读写和使用像一张表一样简单,欢迎大家关注和使用腾讯云ES自治索引。

自治索引介绍:
https://cloud.tencent.com/document/product/845/74396















 1402
1402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









