







作者介绍
ericxwu(伍鑫),腾讯云数据库专家工程师,在数据库内核、数据复制、大数据计算等领域有丰富经验,曾发表多篇相关论文、专利。加入腾讯前曾在IBM DB2团队工作多年,后加入Hashdata云数仓公司。加入腾讯后,负责TDSQL PG系数据库研发工作。
CDW PG总体介绍
CDW PG作为腾讯首款自研MPP分析型数据库,在政务、公安、电信、金融等多个企业级项目中崭露头角。作为国内分析型数据库里的破局者,CDW PG在发布后继续面向行业前沿构架进行大幅优化。经过团队过去一年的深入探索和改进,CDW PG迎来全面升级版本,我们在自研列式存储、向量化引擎、并行执行逻辑、计算层缓存等核心技术模块取得重大性能突破,通用场景分析性能提升十倍以上。另外对产品周边生态工具以及易用性上也持续投入,推出高速数据流转工具、查询瓶颈自动分析工具、复杂查询自动优化能力等,为内外部用户提供更好的一站式数据分析体验。希望通过本系列干货文章,带你快速体验新产品的强大能力,分析业务适配中的核心问题,让业务聚焦在业务本身,而无需进行平台二次开发。
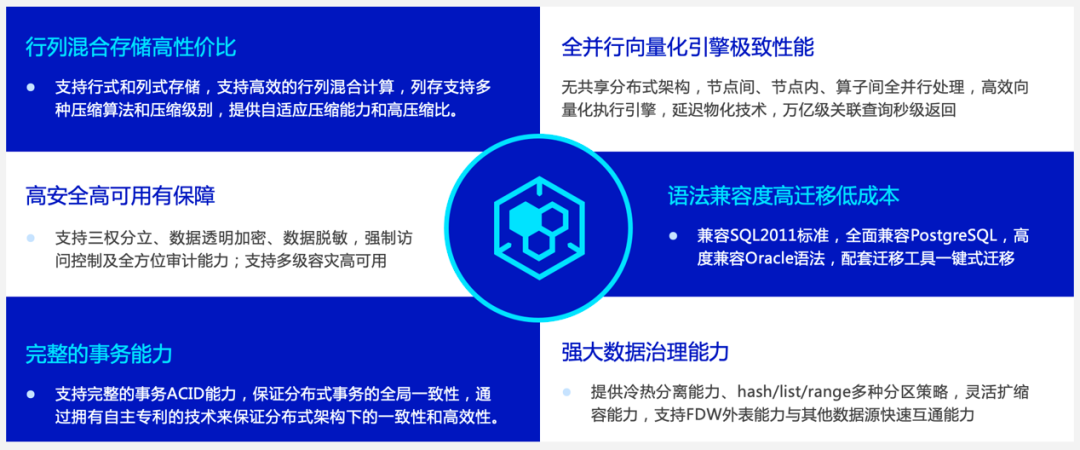
如上图所示,结合CDW PG企业级能力,主要可以为用户提供:
-
面向更加敏捷的业务场景,提供行列混合存储。同时提供支持高性能多模分析的列存储,以及支持高并发数据变更操作的行存储。两种存储格式均严格保证事务ACID特性,支持DML/索引/并发更新/高可用等完整能力。新版本支持将行存格式"热数据"自动Merge"沉降"成列存格式,HTAP混合场景使用体验上更加透明简单。
-
升级全新并行向量化引擎,TPC-DS级别复杂查询场景100%支持向量化执行+并行执行,极致利用系统资源。基于RBO+CBO的分布式查询优化器轻松支持数十张表以上关联查询,用户基本无需调整优化参数。
-
企业级高可用保障,数据库内部处理主备高可用、多级容灾、数据脱敏、透明加密等高可用问题,解决用户后顾之忧。
-
全面兼容SQL2011标准,全面兼容PostgreSQL语法,支持存储过程、用户自定义类型、用户自定义函数,并持续增强Oracle兼容能力。
-
完整的事务能力,支持完整的事务ACID能力,保证分布式事务全局一致性。且相关技术为国内最早实现,并申请自主技术专利。用户不必再自己设计分布式锁等与业务无关逻辑。
-
强大的数据治理能力,优化分区表能力,支持hash/list/range多种分区策略、多级分区,支持基于FDW外表的多种外部数据访问能力,灵活应对各种业务模型。
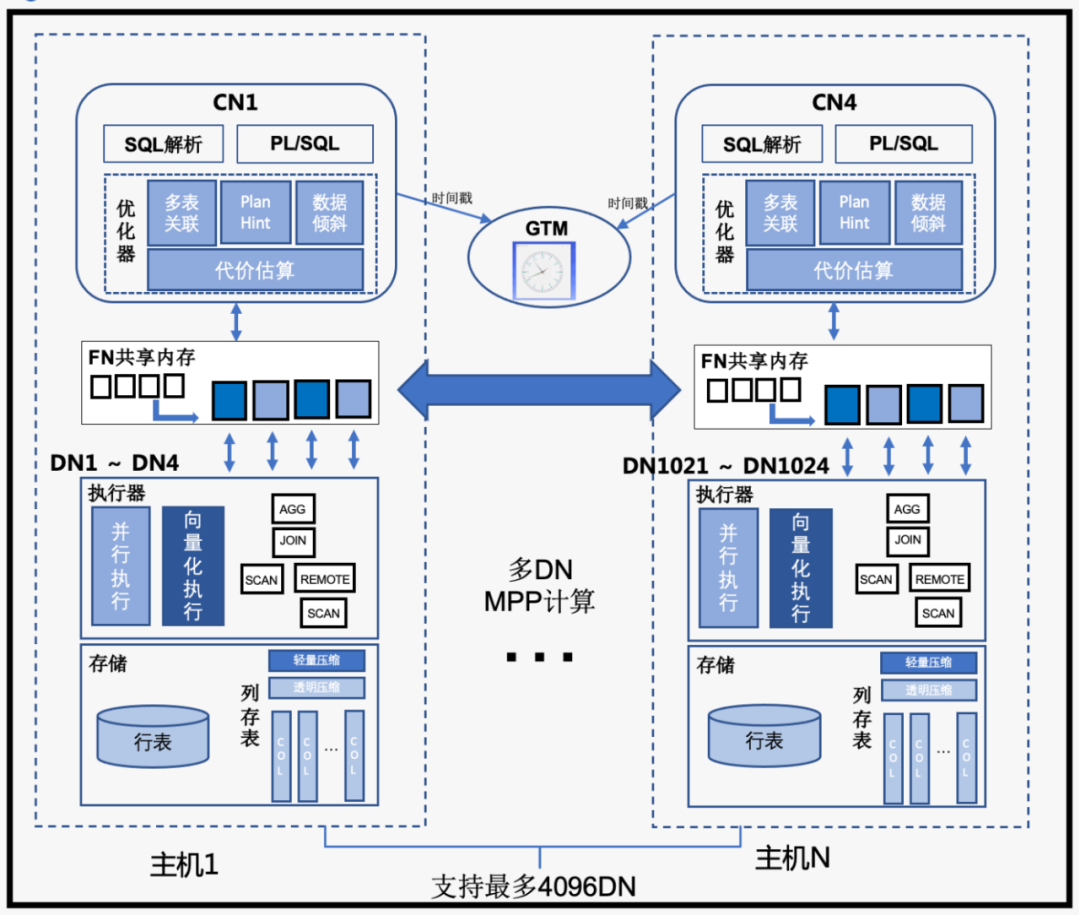
CDW PG集群整体采用MPP无共享计算构架,主要节点类型功能为:
-
Coordinator(CN):协调节点,对外提供接口,负责数据的分发和查询规划,多个节点位置对等,每个节点都提供相同的数据库视图。在功能上CN上只存储系统的全局元数据,并不存储实际的业务数据,所有查询操作。
-
ForwardNode(FN):CDW PG特有的数据转发平面设计,统一负责数据页面在CN/DN间的转发,同一机器内通过共享内存快速传递。通过此方案解决MPP数据库大规模集群高并发场景下的连接风暴问题,因此CDW PG整体支持最多4096个DN节点。
-
DataNode(DN):处理存储本节点相关的元数据,每个节点还存储数据的一个分片。在功能上,DN节点负责完成执行协调节点分发的执行请求。新构架下,CN上生成的查询分片会并行的在DN节点中启动,并通过FN节点异步执行,降低多个查询分片进程的依赖性,最大化数据流转计算效率。
-
GTM:全局事务管理器(Global Transaction Manager),在我们业界领先的基于逻辑时间戳的全局分布式提交协议中,负责全局时间戳GTS的分配。这种设计极大减少高并发时获取全局事务快照带来的单点瓶颈,支持超高事务并发能力。
行列混合存储,适应多种用户场景
数据库技术发展半个世纪,从早期对关系模型的研究到SQL语句的出现,都是不断面向业务需求和用户体验的最佳设计实践。而列存储的出现甚至可以追溯到上世纪70年代的数据库开创时代,当时人们就在讨论具体用何种存储模型来支持上层计算。1985 年,Copeland 和 Khoshafian 提出了一种称为 “Decomposition Storage Model” DSM 存储模型,在这种模型中,数据以属性(也就是列)的方式进行存储,每一行数据有一个代理主键,每个列存代理主键和该列的值。
第一个列式存储系统为 C-Store,在分析型数据库历史中的地位还是非常高的。C-Store 的提出者是 Michael Stonebraker,是数据库领域图领奖获得者,也是著名的商用分析系统 Vertica、开源数据库 Postgresql 的发明者。在 C-Store 的论文中,作者明确了写优化与读优化两种系统的工作场景,并把前者行优先的存储方式称为 Row-Store,而列的方式称为 Column-Store。
而在实际使用场景中,用户业务模型并不会完全适配某一种存储类型,更多的是混合业务模型中带有OLTP或者OLAP场景的倾向性。所以数据库系统在早期针对专一场景的探索比较成熟后,近年来开始进一步探索,逐步提出混合HTAP(Hybrid Transactional/Analytical Processing)模式,希望通过一套引擎来处理混合业务类型。
CDW PG的列存储就是在这种新时代背景下面向未来进行设计。整体以OLAP极致查询性能读优化RO(Read Optimize)为基础前提,保证数据库事务ACID特性,同时针对OLTP场景进行写优化WO(Write Optimize),并且对RO/WO能力进行透明整合,为用户提供透明易用的表结构设计。

图1:列存存储结构设计
上图为CDW PG列存储模块示意图,数据块采用DSM模型,每列以Silo格式独立存储,保证高压缩比和最大化I/O裁剪能力支持。而每张列存储表会创建两张辅助heap表,Registry表用来存储Silo的元数据信息,Stash表用来承接Write Optimize的短事务DML数据并后台进行数据“沉降”Merge。
通过基于heap表的元数据实现,将列存的MVCC设计与行存表统一,使得CDW PG的列存表能够完美支持DML、分布式事务一致性、并发更新等能力。同时列存表也支持B-Tree/Hash索引,range/hash/list等多级分区表能力。用户使用起来更加方便,在选择存储类型建表后,用户基本可以无感知地进行行列混合多表关联、基于索引的点查询加速、多任务并发入库/查询。
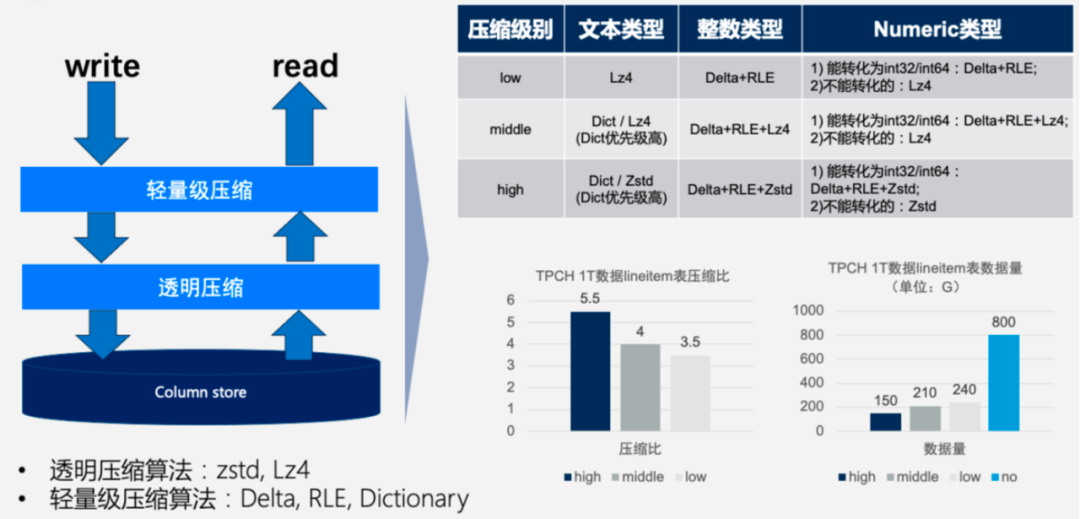
图2:列存压缩设计
列存本身的Silo存储格式是严格设计的自描述(Self-Described)紧凑排列。通过大批量的同类型数据可以支持更高的压缩比。如上图所示,CDW PG列存在TPC-H 1TB数据集上的默认压缩比可以达到5.5倍,此时压缩解压对系统CPU的增量消耗可以忽略不计。为了将不同数据类型压缩最佳经验自动提供给用户,用户建表时可以选择只填写默认压缩等级high/middle/low,系统会根据数据类型自动选择何种压缩算法。
原生向量化的列存扫描设计将列存物理格式的I/O效率完全释放,同时对接上层向量化计算引擎也更加平滑。Predicate Pushdown可以将表达式计算尽可能地提前下推到Silo级别进行过滤,支持Null/Same/Min/Max/直方图等多种过滤方式。Late Read延迟物化扫描方式则可以进一步在有多列条件过滤时,通过前置列的过滤结果避免后续列Silo数据的扫描。以上能力均由CDW PG增强的优化器自动进行查询优化。
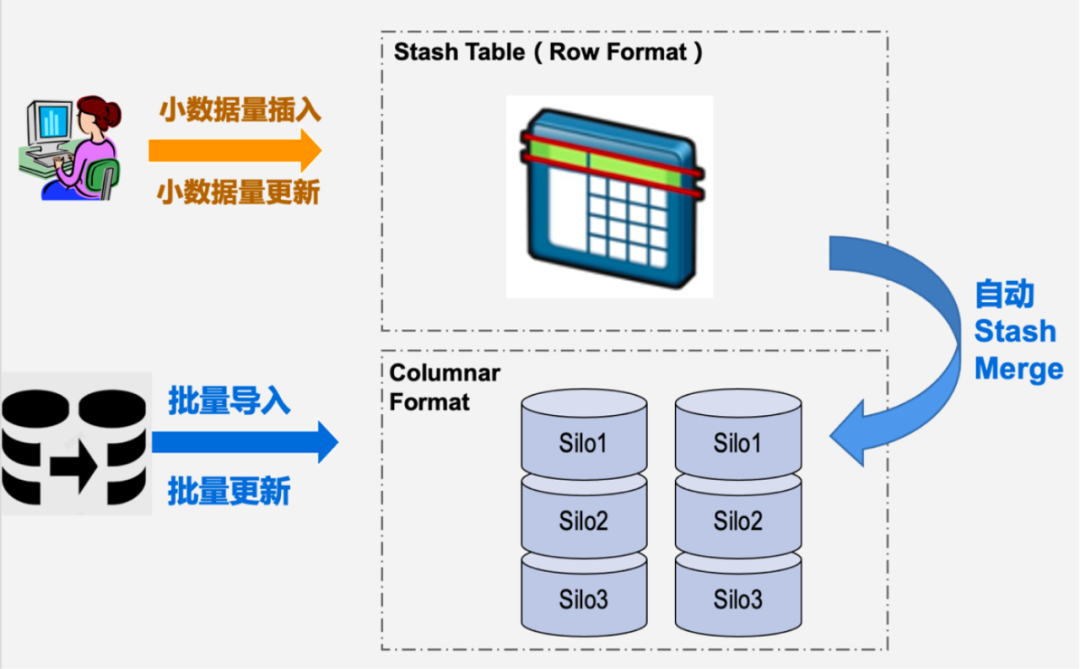
图3:列存自动数据沉降
前面提到,大部分早期列存格式主要针对分析型业务展开设计。而用户如果有混合业务则需要DBA和开发人员进行面向OLTP场景的行存表加列存表的综合方案,并且需要对数据同步方案进行开发设计。CDW PG列存看到HTAP混合业务模型方案,将以上能力在内核层面进行支持。用户可以使用列存而不必对自身业务逻辑进行拆分。DN节点上的Auto Stash Merge背景进程会选择空闲时间进行行存Stash表数据Merge成Silo列存格式的操作,并且避免与业务DML操作冲突。
全新向量化引擎结合并行框架
Postgres和大多通用关系型数据库一样,执行引擎选择适应性更强的标准火山模型。数据自下而上按tuple元组级别被一条条地向上返回。在面向海量数据计算情况下,这中间的多次函数调用以及频繁的CPU缓存换入换出导致代码执行效率不高。目前整体框架优化思路分为向量化执行Vectorize Execution和执行编译Query Compilation。向量化执行通过框架/算子/函数对数据元组的批量操作实现,降低分支预测带来的性能损耗,并且同一vector数据在计算时可以提高CPU缓存命中率。而为了追求极致优化,CPU的SIMD(Single Instruction/Multiple Data)指令集层面也需要对代码进行针对性的适配优化。Query Compilation则是在runtime时针对query进行动态编译来简化执行流程,Postgres在PG11之后也开始在表达式计算上进行增强。业界经验上两者综合效果不分伯仲,且同样呈现两者融合的趋势,即在向量化的整体框架下对算子/表达式进行运行时编译。
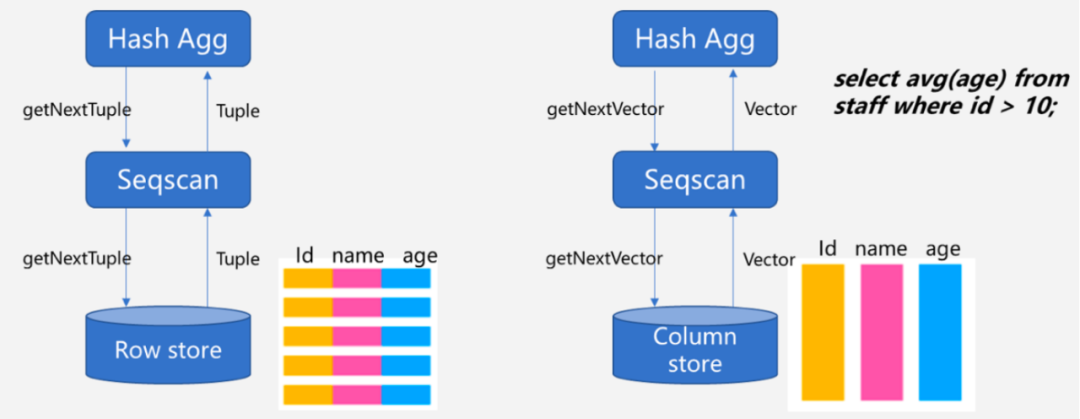
图4:向量化模型示意图
本次升级中,CDW PG主要聚焦向量化执行执行方向进行框架改造和深入优化。针对TPC-DS场景做到所有语句支持向量化执行。区别于列存表存储格式,我们对内存列存vector结构同样进行了深入设计优化,保证不同数据类型以面向计算的最佳格式进行排列,并减少算子间vector传递时的内存拷贝次数。而在算子层面,则针对Scan、Join、Aggregation、Sort、Redistribution、Shared CTE等算子进行向量化版本全新开发。各个数据类型的表达式函数也同样进行向量化适配。通过以上大规模改造,提供一个完整的向量化执行引擎。
优化器也进行适配改造,支持向量化/非向量化查询计划的自动规划。用户打开向量化引擎开关后,系统会自动对支持向量化查询的语句进行优化执行。
我们还针对向量化执行设计了面向计算层的缓存能力,在缓存命中情况下完全屏蔽SeqScan层的计算和I/O开销,而且是针对查询语句的条件进行精准缓存,并做到列级别和表达式范围双重维度的缓存弹性,带来更好的缓存命中率。同时向量化缓存还做到自动数据强一致,在有DML数据变更时对涉及的向量化缓存内容进行异步失效。
此次升级,CDW PG对并行框架也进行了深入改造。查询优化器的CBO模型完整支持MPP分布式场景下的并行查询计划规划。向量化引擎及相关算子也完整支持算子级别并行执行,达到执行效率进一步提升。
复杂关联查询
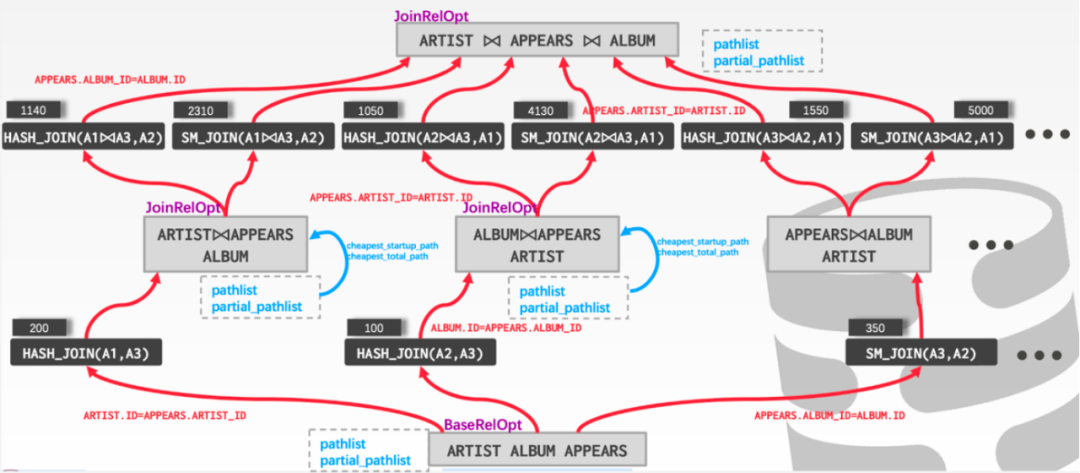
图5:优化器CBO动态规划
作为通用分析型数据库,系统并不会对多表关联查询操作进行限制,用户可以自由根据业务模型进行表设计及优化,而这其中最复杂的模块非查询优化器莫属。CDW PG分布式优化器结合CBO(Cost Based Optimization)与RBO(Rule Based Optimization)对MPP分布式计算进行最佳查询计划搜寻。上图为执行路径的动态规划过程示意图。简而言之,以Base Relation为基础,自下而上针对所有可能的执行路径进行尝试,每层根据路径Path的代价评估进行Cheapest Cost判定形成转移函数,通过重复使用子问题(子计划树)的最优解,减少计算量并最终寻找到全局最优解。当然这只是最基本的思路,针对并行查询、参数化路径、延迟物化路径,优化器也需要进行转移函数的优化考虑。而CDW PG的优化器在对分布式场景的探索中,始终保持CBO框架基础的维护,保证路径生成严格按照贴近PG原生框架的最优算法设计。这种设计也会给后续产品优化器更复杂场景的能力增强打好基础。
而动态规划算法在数十张表关联的情况下,全局最优解的搜寻效率会是一个问题,在CDW PG中,用户可以通过设置GUC参数enable_geqo选择是否开启使用遗传算法,并可以通过设置GUC参数geqo_threshold,选择在连接表的数量大于等于该阈值时使用遗传算法。优化器将参与连接的表作为基因、不同的连接路径作为染色体、连接路径的总代价作为适应度。在每次迭代中,通过对随机选取的染色体进行交叉操作,产生新的连接路径,并通过适应度计算,淘汰不良的染色体,经过N轮之后获取一个局部最优的连接路径。
通过以上技术,保证查询在TPC-DS级别的语句中,基本可以做到无需优化器参数调优,用默认参数就可以生成最佳执行计划。而在多个企业级项目的复杂(20~30张表关联)业务场景中,也得到了很好的效果验证。
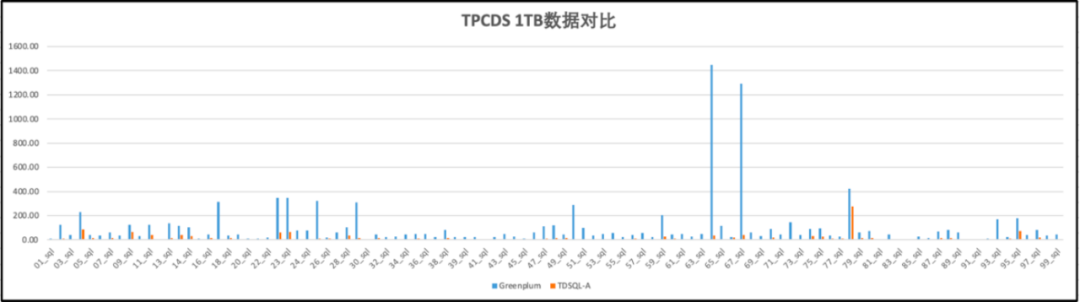
以下为TPC-DS 1000 scale factor(1TB)标准数据集下,相同8台TS85物理机环境下,CDW PG与业界数仓标杆Greenplum 6的性能对比。整体达到6倍性能领先。
资源组能力介绍
CDW PG在本次升级后,提供了增强的资源组(Resource Group)管控能力,为角色Role提供资源组配置能力,相同资源组内用户可以设置优先级控制。资源组能力控制本身支持基于CGroup的CPU资源管控,相同资源组的查询在所有节点DN上的进程都会绑定到对应CGroup中进行管控。而基于query_mem的语句级内存资源管控能力,可以通过优化器自动对语句每个算子的work_mem进行规划,保证系统整体内存不超限。整体保证集群CPU、内存等资源完全在内核范围可控,避免因复杂查询导致系统资源耗尽带来的异常状况。用户可以基于资源组支持多租户能力,灵活进行业务资源隔离。
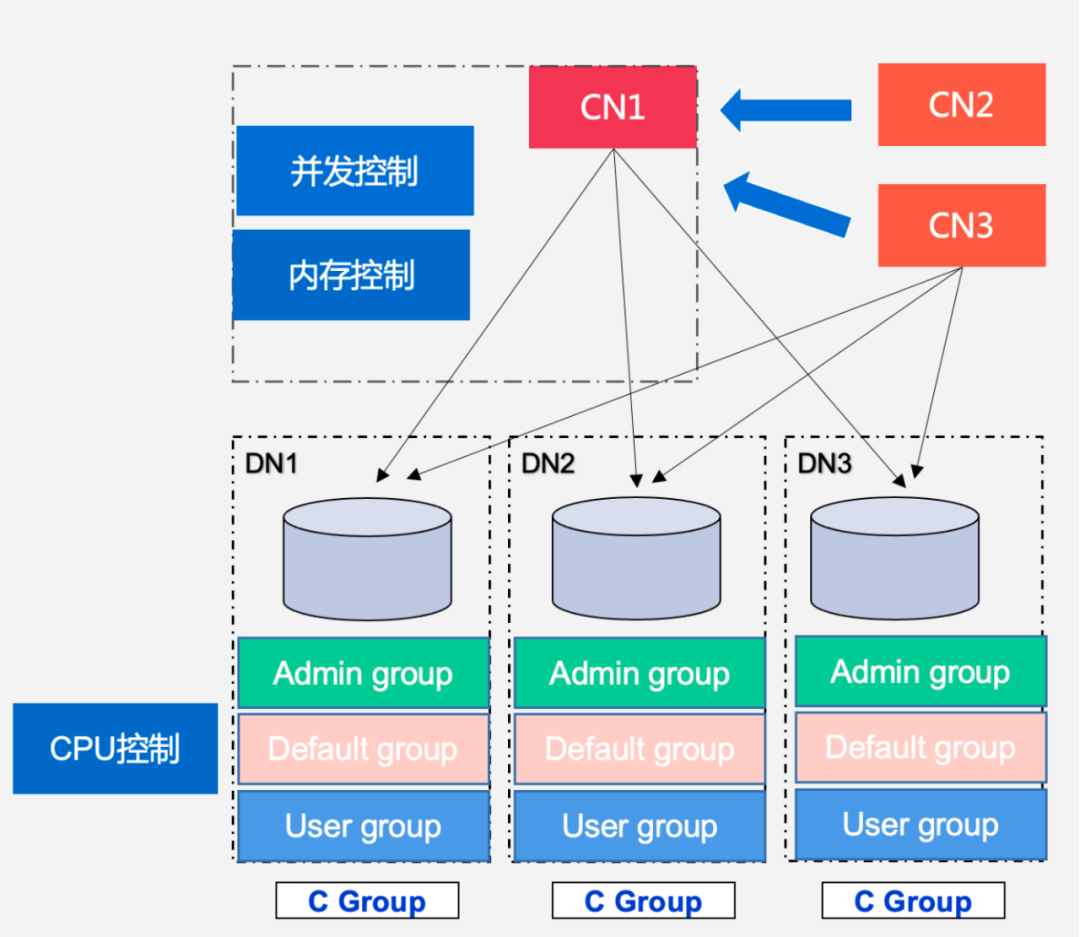
图6:资源组构架
数据导入工具
CDW PG海量数据处理情况下,Postgres原生的Copy数据导入性能成为瓶颈,如何快速将前端OLTP/ODS数据导入到CDW PG进行分析成为了整个生态中关键的一环。这里我们针对分析型数据库多DN节点进行了分布式优化,用户建立基于TDX的外部表,在数据导入导出过程中,DN并行的从TDX进行数据分片的收取和发送,整体性能达到Copy的数十倍。
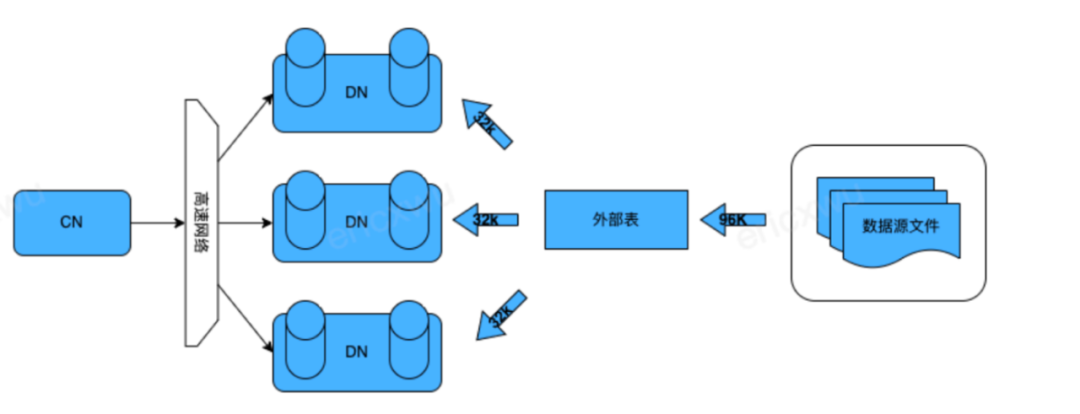
图7:TDX数据导入导出工具
TDX同时还可以通过管道的方式对接多种数据源,比如通过Kafka connector将数据写入TDX对接的管道中,达到更加灵活的数据导入方案。
自动运维工具
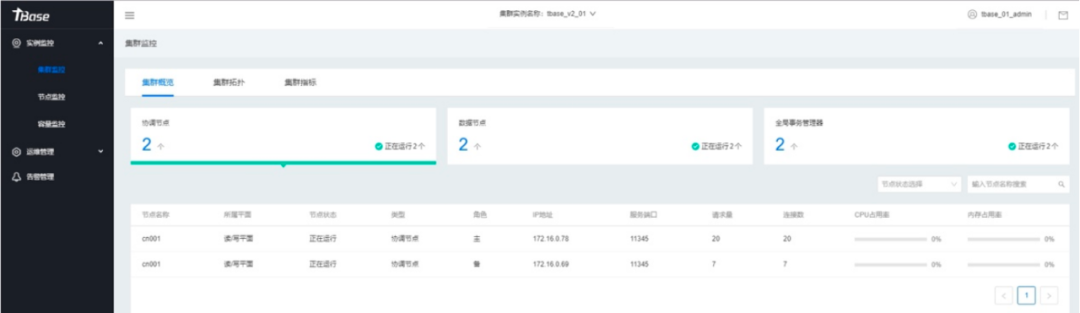
图8:可视化的管控界面
CDW PG作为企业级产品,可视化的管控界面也是持续进行深入优化。支持实力管理、节点管理、主备倒换、灾备恢复、扩容缩容、审计安全等全面的运维能力,极大的提高运维同学的操作效率。
通过以上的整体介绍,希望大家对CDW PG本次升级整体能力有全面的了解,并方便您在分析型计算框架选型中更加明确需求与对应产品能力的适配原理。接下来我们将陆续针对上述技术点进行全面细致的解读文章推送,欢迎您的持续关注与支持。CDW PG团队将持续打破技术边界,不断突破优化,为用户提供更扎实、好用的数据库产品。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









