






腾讯云数据湖计算 DLC 提供敏捷高效的 Serverless 数据湖分析与计算服务,作为分布式计算平台,其查询性能受到多项内外部因素影响,例如:引擎 CU 规模、同时提交排队的任务数量、SQL 编写形式、Spark引擎参数设置等。因此,在任务实际使用过程中,用户往往会面临大量的Spark性能调优问题,及因为作业或SQL编写不正确而产生的排障问题。原生Spark UI中虽然能够一定程度获取任务的相关问题,但仍需要用户具备一定的Spark使用经验与运维能力才定位分析问题,无法做到简易的多维感知,快速定位发现任务的潜在问题。
为解决这些问题,腾讯云数据湖计算 DLC 推出了Spark 洞察高阶运维能力,提供了一个可视化的直观界面,帮助用户快速了解当前任务计算性能表现以及影响性能的潜在因素,并提供性能优化建议。
为什么要用数据湖计算洞察功能
大数据开发经常会出现:数据湖上运行的各项任务在刚开始阶段运行顺利,但随着时间推移任务的计算执行效率在慢慢下降。当系统显示异常时,任务执行时间已经严重不能满足业务诉求,导致业务受影响。DLC计算洞察功能,可以让您提早发现问题,并给出解决建议,帮助用户尽早解决问题,避免业务受影响。

适用的业务场景:
1. 运行状态洞察:对 Spark 引擎有整体运行状况洞察的诉求,如:各引擎下运行中的任务资源使用分布情况,任务运行 cpu 总耗时,任务引擎内排队时长和执行时长分析,数据扫描大小,数据 shuffle 大小等都有直观的展示与分析。
2. 资源治理判断:快速定位有问题的大任务并提供针对性优化建议,帮助用户完成降本增效的诉求。
3. 问题根因定位:可以自助排查分析任务运行情况的诉求,如:定位 Spark 任务运行缓慢或失败的原因,如资源抢占,shuffle 异常,数据倾斜等情况,都有清晰的定位
DLC洞察实现原理
数据湖计算 DLC 基于 Spark 内部 Metrics 数据,发布可观测和可洞察双维度的引擎洞察功能。通过直观界面,帮助用户快速了解当前计算性能表现以及影响性能的潜在因素,并获取性能优化建议。
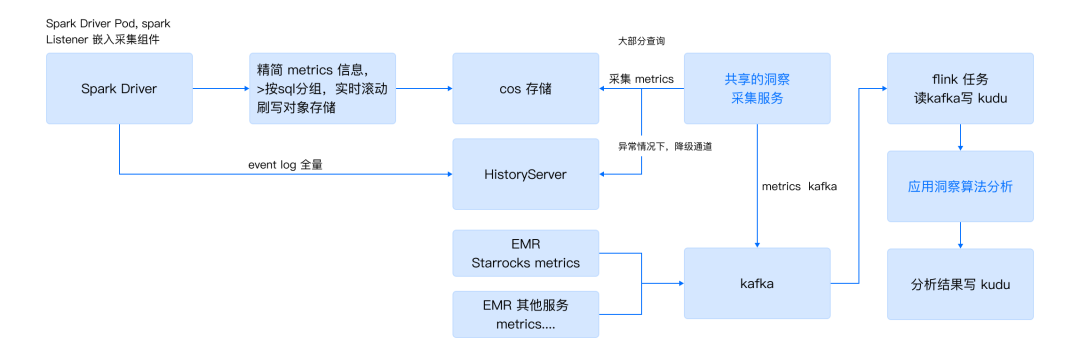
1. 洞察采集的实现方式
a. 主要方式:基于 SparkListener 无侵入式采集数据,按照 SQL 或者批作业任务分组统计,采集 stage、task 、执行计划等精简后的数据,模拟 Spark 内部计算口径,按照 SQL 分组后实时滚动刷写至对象存储。
b. 备用方式:基于 HistoryServer 采集,这是一个降级采集数据的通道,仅作用于异常情况。DLC 原本就在每个地域部署了一个 HistoryServer,用于用户方便查看 Spark UI 分析任务,但由于 HistoryServer 回放大量任务的 eventLog 成本过高且不稳定,所以仅作为备用的降级方案。
同时每个地域也部署了一个洞察采集的容器服务,感知每个用户查询进度,查询完成后,会拉取统计数据,推送 kafka ,同时记录采集状态,必要情况下进行重试或者降级采集数据。
2. 洞察分析
采集多种类型的作业(包括 Spark、Starrocks、MapReduce 等)Metrics 指标信息,持久化存储到KUDU中,集成多种分析算法,使用 Flink 引擎针对数据倾斜,数据长尾等问题进行自动化分析并进行可视化展现。
案例分享
【痛点一:资源抢占,导致任务执行延迟】
数据湖计算 DLC 作为分布式计算平台,计算资源支持资源池化+多租户共享方式来实现极致的资源利用率,但同时也带来了一个问题:
由于资源属于共享池,在大规模、大数据量的任务同时并发进行时,会导致不同租户、不同优先级的作业对资源抢占,致使任务资源分配不均。资源分配少的任务会面临任务运行时间拉长或任务长时间拉不起来的情况发生。洞察提供了近实时的端到端时间消耗瀑布流图,帮助更易分析全局任务的运行情况。
案例:某企业的运维人员,在周末进行任务巡检时,发现某指定任务一直在执行中,运行时长超过预期,需要初步排查定位问题
解决方案:
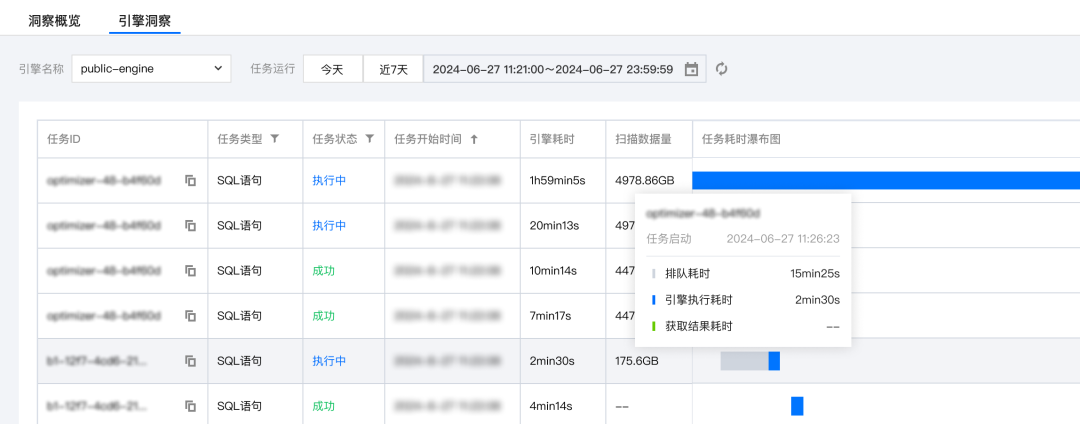
1. 进入引擎用量洞察功能页面:页面提供了指定引擎下所有任务运行的瀑布流图,灰色部分进度条代表正在等待资源,如图所示,发现有占资源的大任务,导致其他任务因等待资源排队耗时过长。
2. 任务结束后,可通过洞察详情方便找到与该任务并发运行的其他任务,如图可找到 27 个与其争抢资源的任务,第二个任务抢占了过多资源。
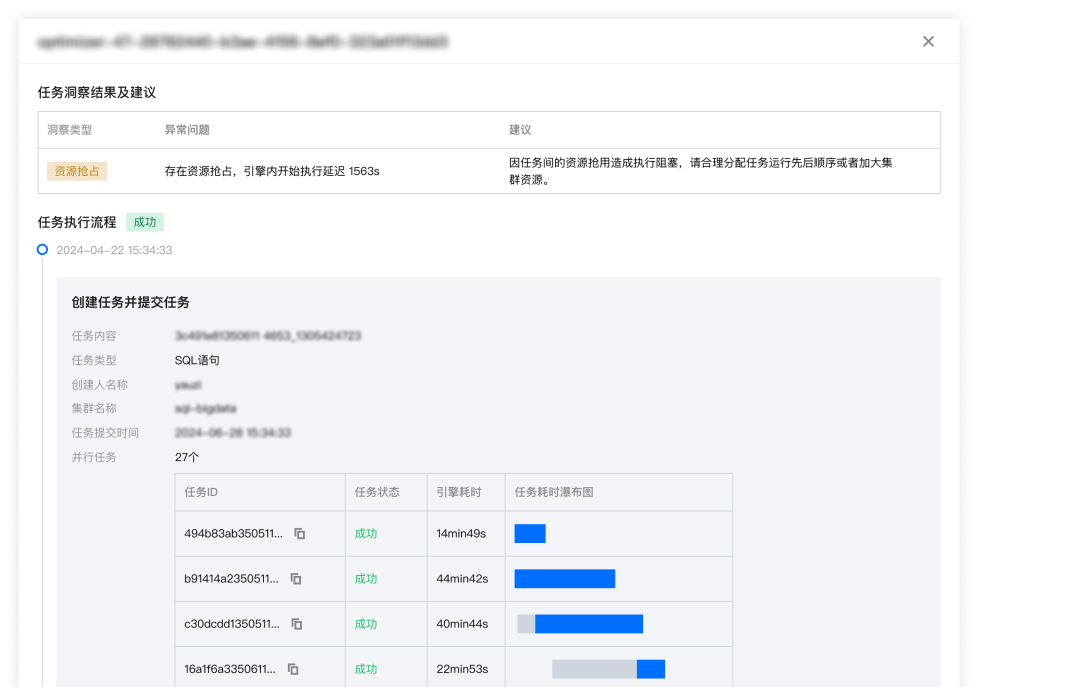
解决建议:
1. 确认占资源的大任务是否符合预期,是否需要调整任务内容或者顺序。
2. DLC 新内核提供灵活限制单个任务使用 core 最大上限的功能,可针对大任务配置,减少饥饿问题。
3. 利用DLC弹性能力,在资源紧张时加大资源供给。
【痛点二:任务质量层次不齐,众多任务难以运维,导致集群资源利用率低下】
任务的运行性能,除了资源支持外,工程师们的写的脚本、配置的参数,都会影响着任务的性能,例如数据倾斜,shuffle 并发度不够,长尾任务拖慢整体执行时间等问题。
当众多质量层次不齐的任务一起运行后,集群运维就比较困难,难以快速发现有问题的核心任务进行针对性优化,只能通过加大集群资源来解决,不能充分利用集群资源。
案例:某客户在DLC有4000+CU的资源,想优化整体任和提高集群资源利用率,但任务众多,不知何处解决。
解决方案:
1. 利用洞察快速找到有问题大任务优化:时间有限的情况下,可优先找到头部大任务,优化效果收益更好。例如按照引擎执行耗时排序(或者 cu 耗时排序)后,筛选数据倾斜(或其他洞察类型)任务,点击任务洞察详情,可看到倾斜的 stage 信息,针对性的进行优化,例如案例中存在长尾 task 2h 的任务,优化后运行时间可从 2.5h 缩短为 44s。
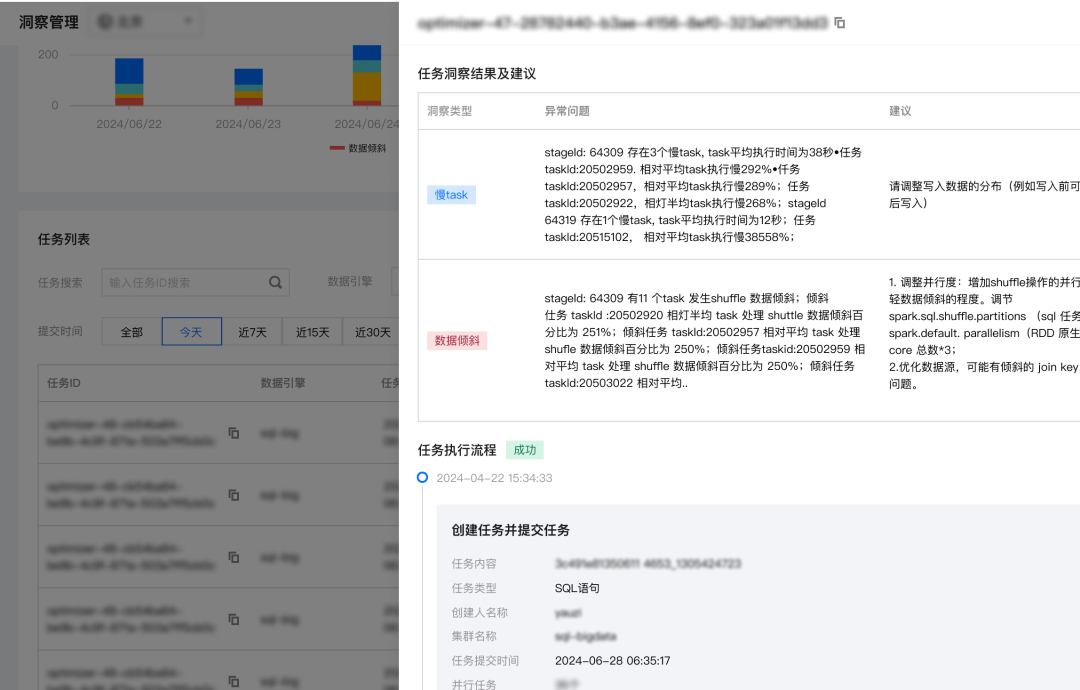


2. 洞察也提供了多维度分析任务的途径,例如按照数据扫描量,数据 shuffle 大小,cpu 总耗时等等指标排序后分析,方便快速定位头部大任务,可更充分评估和利用集群资源。
由于 Spark shuffle 阶段是影响任务执行速度和整体集群稳定关键因素,针对大 shuffle 数据量的任务进行定向优化,收益会比较好(即使成功任务内部也可能会存在 shuffle 重试的情况,筛选 shuffle 异常的任务,也可以方便快速定位调优)。
效果:案例中的用户从高峰期的 4096 CU * 2 集群降至3000+CU 单集群,有了明显的降本成效。
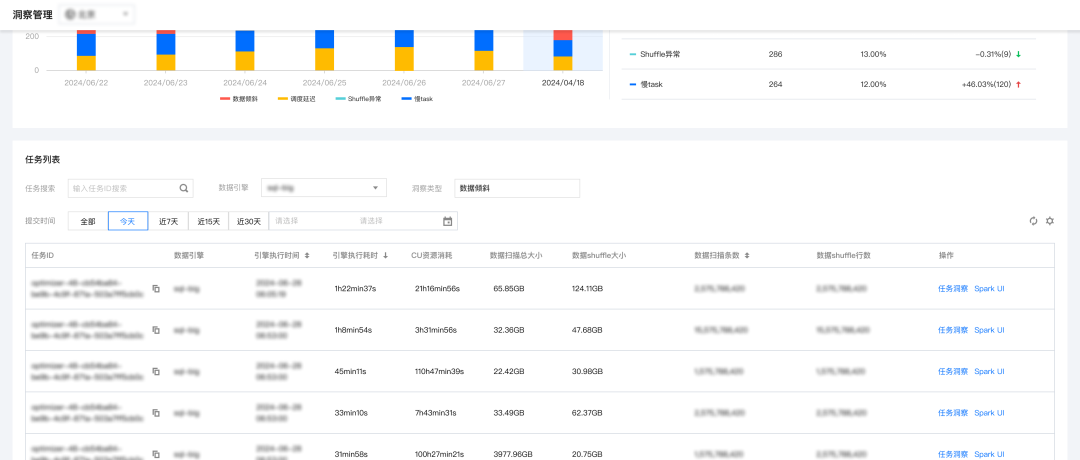
【痛点三:能够对资源进行全局的判断,帮助企业进行更好的降本增效精细化管理】
企业对于资源的采购,往往根据数据量级、往期消费趋势来进行判断的。但单一的账单是无法体现出资源是否有效的分配在每一个任务里或者每一个任务是否由于数据质量问题导致资源浪费。数据湖计算DLC洞察通过CU消耗情况,通过统计所有 Spark task executor runtime 时间累加值,结合任务洞察建议、引擎执行耗时分布等多方位的数据展示,更好的帮助企业判断资源消耗的健康度。
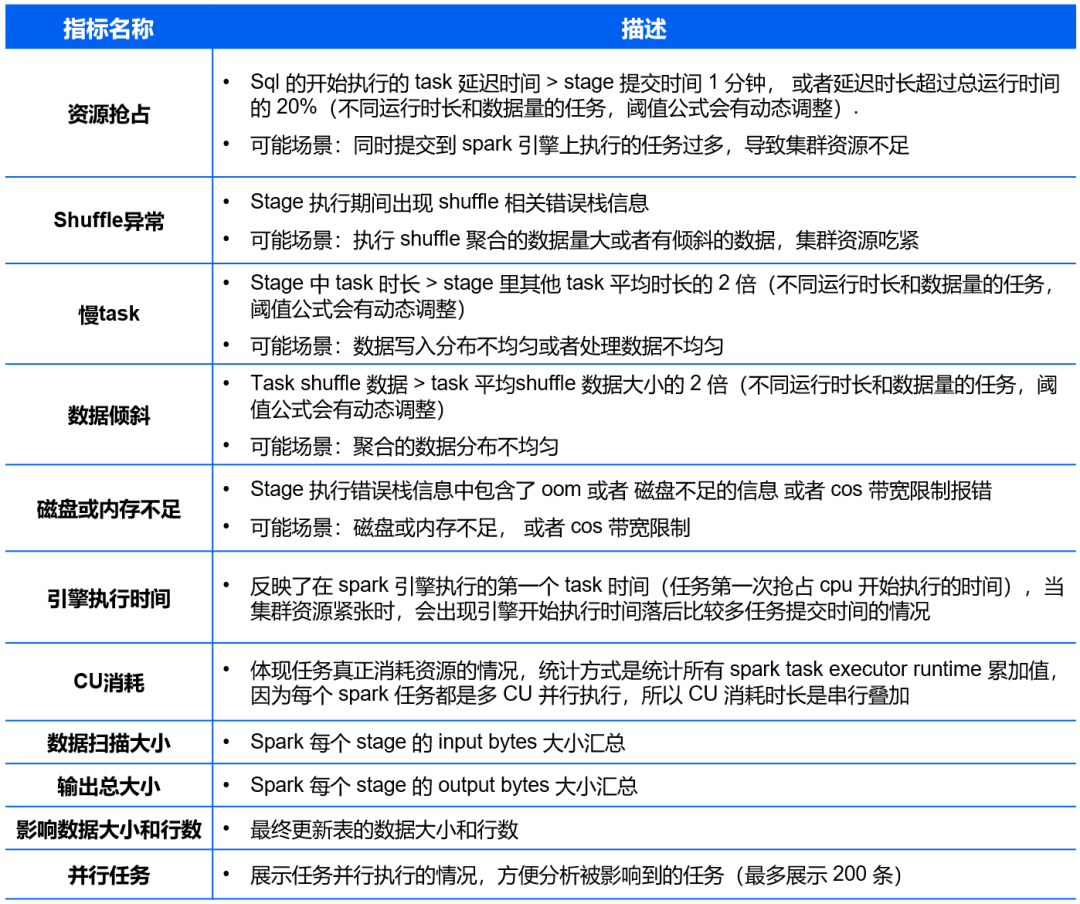
当前DLC的洞察核心检查项如下(会持续改进和新增算法规则):
后续规划
腾讯云数据湖计算 DLC 产品作为Serverless Lakehouse产品,近年来投入了大量资源进行相关的特性开发。在未来,DLC团队将持续在洞察能力上的投入,构建更多的关键产品能力,如:
1. HBO(History Based Optimizer),基于历史任务的 metrics 和执行计划,查询热点情况,自动推荐查询索引例如 bloomfilter,推荐优化的数据分布列序,减少事后干预,提高运维效率。
2. 基于执行计划等数据,添加更多完善的洞察算法,更精确和容易的运维任务,减少排障时间。
如您对DLC洞察管理功能感兴趣,可进一步通过 腾讯云 DLC官网文档 获得更多信息。
关注腾讯云大数据公众号
邀您探索数据的无限可能

点击原文链接,了解更多相关产品详情
↓↓↓















 7751
7751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









