







:NameNode
2:SecondNameNode
3:DataNode
4:ResourceManager
5:NodeManager
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
参考博客:
http://dongxicheng.org/mapreduce-nextgen/nodemanager-architecture/
http://dongxicheng.org/mapreduce-nextgen/yarnmrv2-resource-manager-infrastructure/
http://www.aboutyun.com/thread-7778-1-1.html
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1、NameNode介绍
Namenode 管理者文件系统的Namespace。它维护着文件系统树(filesystem tree)以及文件树中所有的文件和文件夹的元数据(metadata)。管理这些信息的文件有两个,分别是Namespace 镜像文件(Namespace image)和操作日志文件(edit log),这些信息被Cache在RAM中,当然,这两个文件也会被持久化存储在本地硬盘。Namenode记录着每个文件中各个块所在的数据节点的位置信息,但是他并不持久化存储这些信息,因为这些信息会在系统启动时从数据节点重建。
Namenode结构图课抽象为如图:
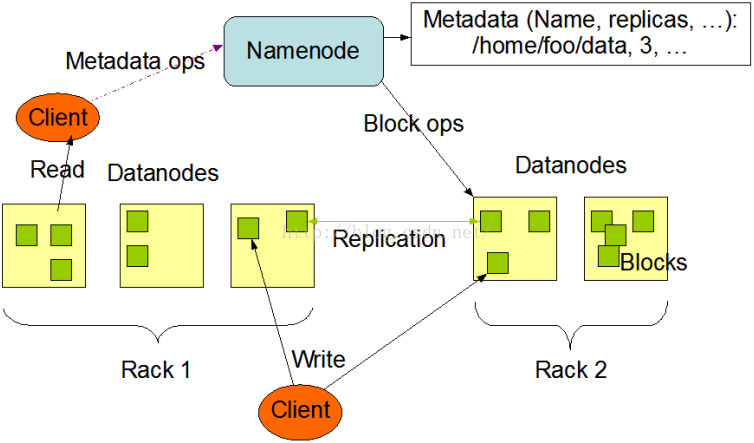
客户端(client)代表用户与namenode和datanode交互来访问整个文件系统。客户端提供了一些列的文件系统接口,因此我们在编程时,几乎无须知道datanode和namenode,即可完成我们所需要的功能。
1.1Namenode容错机制
没有Namenode,HDFS就不能工作。事实上,如果运行namenode的机器坏掉的话,系统中的文件将会完全丢失,因为没有其他方法能够将位于不同datanode上的文件块(blocks)重建文件。因此,namenode的容错机制非常重要,Hadoop提供了两种机制。
第一种方式是将持久化存储在本地硬盘的文件系统元数据备份。Hadoop可以通过配置来让Namenode将他的持久化状态文件写到不同的文件系统中。这种写操作是同步并且是原子化的。比较常见的配置是在将持久化状态写到本地硬盘的同时,也写入到一个远程挂载的网络文件系统。
第二种方式是运行一个辅助的Namenode(Secondary Namenode)。 事实上Secondary Namenode并不能被用作Namenode它的主要作用是定期的将Namespace镜像与操作日志文件(edit log)合并,以防止操作日志文件(edit log)变得过大。通常,Secondary Namenode 运行在一个单独的物理机上,因为合并操作需要占用大量的CPU时间以及和Namenode相当的内存。辅助Namenode保存着合并后的Namespace镜像的一个备份,万一哪天Namenode宕机了,这个备份就可以用上了。
但是辅助Namenode总是落后于主Namenode,所以在Namenode宕机时,数据丢失是不可避免的。在这种情况下,一般的,要结合第一种方式中提到的远程挂载的网络文件系统(NFS)中的Namenode的元数据文件来使用,把NFS中的Namenode元数据文件,拷贝到辅助Namenode,并把辅助Namenode作为主Namenode来运行。
当然在hadoop 2.x 中,已经有了新的解决方案,那就是NameNode HA(因为Hadoop还包括 ResourceManage HA),hadoop联邦, Hadoop HA是指同时启动两个NameNode,一个处于工作状态,另外一个处于随时待命状态,这样在处于工作状态的NameNode所在的服务器宕机时,可在数据不丢失的情况下,手工或者自动切换到另外一个NameNode提供服务。
------------------------------------------------------------------------------------------------------------------------------------------------------------------------
2、Datanode介绍
Datanode是文件系统的工作节点,他们根据客户端或者是namenode的调度存储和检索数据,并且定期向namenode发送他们所存储的块(block)的列表。
集群中的每个服务器都运行一个DataNode后台程序,这个后台程序负责把HDFS数据块读写到本地的文件系统。当需要通过客户端读/写某个 数据时,先由NameNode告诉客户端去哪个DataNode进行具体的读/写操作,然后,客户端直接与这个DataNode服务器上的后台程序进行通 信,并且对相关的数据块进行读/写操作。
------------------------------------------------------------------------------------------------------------------------------------------------------------------------
3、Secondary NameNode介绍
另外一篇关于Secondary NameNode 的博客,描述的也十分清晰:点击阅读
Secondary NameNode是一个用来监控HDFS状态的辅助后台程序。就想NameNode一样,每个集群都有一个Secondary NameNode,并且部署在一个单独的服务器上。Secondary NameNode不同于NameNode,它不接受或者记录任何实时的数据变化,但是,它会与NameNode进行通信,以便定期地保存HDFS元数据的 快照。由于NameNode是单点的,通过Secondary NameNode的快照功能,可以将NameNode的宕机时间和数据损失降低到最小。同时,如果NameNode发生问题,Secondary NameNode可以及时地作为备用NameNode使用。
3.1NameNode的目录结构如下:
${dfs.name.dir}/current/VERSION
/edits
/fsimage
/fstime
3.2Secondary NameNode的目录结构如下:
${fs.checkpoint.dir}/current/VERSION
/edits
/fsimage
/fstime
/previous.checkpoint/VERSION
/edits
/fsimage
/fstime
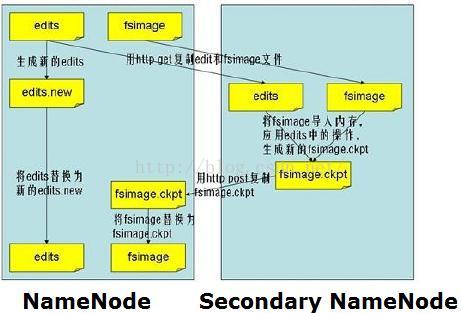
如上图,Secondary NameNode主要是做Namespace image和Edit log合并的。
那么这两种文件是做什么的?当客户端执行写操作,则NameNode会在edit log记录下来,(我感觉这个文件有些像Oracle的online redo logo file)并在内存中保存一份文件系统的元数据。
Namespace image(fsimage)文件是文件系统元数据的持久化检查点,不会在写操作后马上更新,因为fsimage写非常慢(这个有比较像datafile)。
由于Edit log不断增长,在NameNode重启时,会造成长时间NameNode处于安全模式,不可用状态,是非常不符合Hadoop的设计初衷。所以要周期性合并Edit log,但是这个工作由NameNode来完成,会占用大量资源,这样就出现了Secondary NameNode,它可以进行image检查点的处理工作。步骤如下:
(1) Secondary NameNode请求NameNode进行edit log的滚动(即创建一个新的edit log),将新的编辑操作记录到新生成的edit log文件;
(2) 通过http get方式,读取NameNode上的fsimage和edits文件,到Secondary NameNode上;
(3) 读取fsimage到内存中,即加载fsimage到内存,然后执行edits中所有操作(类似OracleDG,应用redo log),并生成一个新的fsimage文件,即这个检查点被创建;
(4) 通过http post方式,将新的fsimage文件传送到NameNode;
(5) NameNode使用新的fsimage替换原来的fsimage文件,让(1)创建的edits替代原来的edits文件;并且更新fsimage文件的检查点时间。
整个处理过程完成。
Secondary NameNode的处理,是将fsimage和edites文件周期的合并,不会造成nameNode重启时造成长时间不可访问的情况。
------------------------------------------------------------------------------------------------------------------------------------------------------------------------
4、ResourceManager介绍
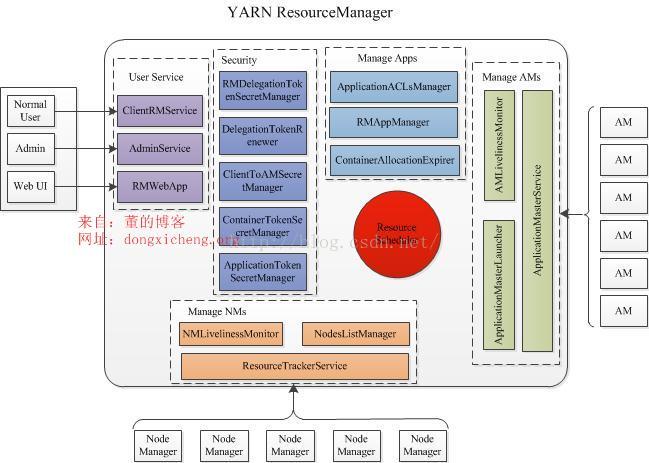
ResourceManage 即资源管理,在YARN中,ResourceManager负责集群中所有资源的统一管理和分配,它接收来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序(实际上是ApplicationManager)。
RM包括Scheduler(定时调度器)和ApplicationManager(应用管理器)。Schedular负责向应用程序分配资源,它不做监控以及应用程序的状态跟踪,并且不保证会重启应用程序本身或者硬件出错而执行失败的应用程序。ApplicationManager负责接受新的任务,协调并提供在ApplicationMaster容器失败时的重启功能。
这里简单介绍以下ApplicationMaster,每个应用程序的AM负责项Scheduler申请资源,以及跟踪这些资源的使用情况和资源调度的监控
更多关于ResourceManager的介绍参考:点击阅读
------------------------------------------------------------------------------------------------------------------------------------------------------------------------
5、NodeManager介绍
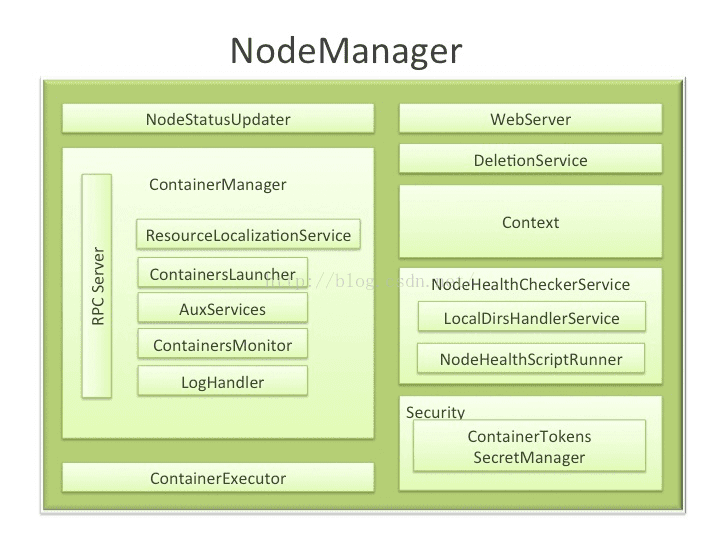
NM是ResourceManager在每台机器上的代理,负责容器管理,并监控它们的资源使用情况,以及向ResourceManager/Scheduler提供资源使用报告
更多参考
更多详细的架构分析请参考:点击阅读















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









