







1. Azkaban是什么?
Azkaban是由Linkedin公司推出的一个批量工作流任务调度器,主要用于在一个工作流内以一个特定的顺序运行一组工作和流程,它的配置是通过简单的key:value对的方式,通过配置中的dependencies 来设置依赖关系,这个依赖关系必须是无环的,否则会被视为无效的工作流。Azkaban使用job配置文件建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
在介绍Azkaban之前,我们先来看一下现有的两个工作流任务调度系统。知名度比较高的应该是Apache Oozie,但是其配置工作流的过程是编写大量的XML配置,而且代码复杂度比较高,不易于二次开发。另外一个应用也比较广泛的调度系统是Airflow,但是其开发语言是Python。由于我们团队内部使用Java作为主流开发语言,所以选型的时候就被淘汰掉了。我们选择Azkaban的原因基于以下几点:
- 提供功能清晰,简单易用的Web UI界面
- 提供job配置文件快速建立任务和任务之间的依赖关系
- 提供模块化和可插拔的插件机制,原生支持command、Java、Hive、Pig、Hadoop
- 基于Java开发,代码结构清晰,易于二次开发
2. Azkaban的适用场景
实际项目中经常有这些场景:每天有一个大任务,这个大任务可以分成A,B,C,D四个小任务,A,B任务之间没有依赖关系,C任务依赖A,B任务的结果,D任务依赖C任务的结果。一般的做法是,开两个终端同时执行A,B,两个都执行完了再执行C,最后再执行D。这样的话,整个的执行过程都需要人工参加,并且得盯着各任务的进度。但是我们的很多任务都是在深更半夜执行的,通过写脚本设置crontab执行。其实,整个过程类似于一个有向无环图(DAG)。每个子任务相当于大任务中的一个流,任务的起点可以从没有度的节点开始执行,任何没有通路的节点之间可以同时执行,比如上述的A,B。总结起来的话,我们需要的就是一个工作流的调度器,而Azkaban就是能解决上述问题的一个调度器。
3. Azkaban架构
Azkaban在LinkedIn上实施,以解决Hadoop作业依赖问题。我们有工作需要按顺序运行,从ETL工作到数据分析产品。最初是单一服务器解决方案,随着多年来Hadoop用户数量的增加,Azkaban 已经发展成为一个更强大的解决方案。
Azkaban由三个关键组件构成:
- 关系型数据库(MySQL)
- AzkabanWebServer
- AzkabanExecutorServer

3.1 关系型数据库(MySQL)
Azkaban使用数据库存储大部分状态,AzkabanWebServer和AzkabanExecutorServer都需要访问数据库。
AzkabanWebServer使用数据库的原因如下:
- 项目管理:项目、项目权限以及上传的文件。
- 执行流状态:跟踪执行流程以及执行程序正在运行的流程。
- 以前的流程/作业:通过以前的作业和流程执行以及访问其日志文件进行搜索。
- 计划程序:保留计划作业的状态。
- SLA:保持所有的SLA规则
AzkabanExecutorServer使用数据库的原因如下:
- 访问项目:从数据库检索项目文件。
- 执行流程/作业:检索和更新正在执行的作业流的数据
- 日志:将作业和工作流的输出日志存储到数据库中。
- 交互依赖关系:如果一个工作流在不同的执行器上运行,它将从数据库中获取状态。
3.2 AzkabanWebServer
AzkabanWebServer是整个Azkaban工作流系统的主要管理者,它负责project管理、用户登录认证、定时执行工作流、跟踪工作流执行进度等一系列任务。同时,它还提供Web服务操作的接口,利用该接口,用户可以使用curl或其他ajax的方式,来执行azkaban的相关操作。操作包括:用户登录、创建project、上传workflow、执行workflow、查询workflow的执行进度、杀掉workflow等一系列操作,且这些操作的返回结果均是json的格式。并且Azkaban使用方便,Azkaban使用以.job为后缀名的键值属性文件来定义工作流中的各个任务,以及使用dependencies属性来定义作业间的依赖关系链。这些作业文件和关联的代码最终以*.zip的方式通过Azkaban UI上传到Web服务器上。
3.3 AzkabanExecutorServer
以前版本的Azkaban在单个服务中具有AzkabanWebServer和AzkabanExecutorServer功能,目前Azkaban已将AzkabanExecutorServer分离成独立的服务器,拆分AzkabanExecutorServer的原因有如下几点:
- 某个任务流失败后,可以更方便的将其重新执行
- 便于Azkaban升级
AzkabanExecutorServer主要负责具体的工作流的提交、执行,可以启动多个执行服务器,它们通过mysql数据库来协调任务的执行。
4. Azkaban作业流执行过程
- Webserver根据内存中缓存的各Executor的资源状态(Webserver有一个线程会遍历各个active executor,去发送http请求获取其资源状态信息缓存到内存中),按照选择策略(包括executor资源状态、最近执行流个数等)选择一个executor下发作业流;
- executor判断是否设置作业粒度分配,如果未设置作业粒度分配,则在当前executor执行所有作业;如果设置了作业粒度分配,则当前节点会成为作业分配的决策者,即分配节点;
- 分配节点从zookeeper获取各个executor的资源状态信息,然后根据策略选择一个executor分配作业;
- 被分配到作业的executor即成为执行节点,执行作业,然后更新数据库。
5. Azkaban架构的三种运行模式
在版本3.0中,Azkaban提供了以下三种模式:
- solo server mode:最简单的模式,数据库内置的H2数据库,AzkabanWebServer和AzkabanExecutorServer都在一个进程中运行,任务量不大项目可以采用此模式。
- two server mode:数据库为MySQL,管理服务器和执行服务器在不同进程,这种模式下,AzkabanWebServer和AzkabanExecutorServer互不影响。
- multiple executor mode:该模式下,AzkabanWebServer和AzkabanExecutorServer运行在不同主机上,且AzkabanExecutorServer可以有多个。
目前我们采用的是multiple executor mode方式,分别在不同的主机上部署多个AzkabanExecutorServer以应对高并发定时任务执行的情况,从而减轻单个服务器的压力。
WebServer和ExecutorServer同步solo配置
分别编辑build.gradle 添加如果代码块
from('../azkaban-solo-server/build/resources/main/conf') {
into 'conf'
}
from('../azkaban-solo-server/src/main/resources/commonprivate.properties') {
into 'plugins/jobtypes'
}
from('../azkaban-solo-server/src/main/resources/log4j.properties') {
into ''
}
from('../azkaban-solo-server/src/main/resources/commonprivate.properties') {
into ''
}
# Build and install distributions ./gradlew installDist
6. Azkaban使用
6.1 创建项目
进入Azkaban后,您将看到“项目”页面。此页面将显示您具有读取权限的所有项目的列表。只有组权限或具有READ或ADMIN角色的项目不会出现。

如果刚刚开始,项目页面可能为空。但是,您可以通过单击所有项目来查看所有现有项目。
单击创建项目将弹出一个对话框。输入项目的唯一项目名称和说明,项目名称必须以英文字母开头,只能包含数字、英文字母、下划线、横线 。以后可以更改说明,但项目名称不能。如果您没有看到此按钮,除了具有适当权限的用户之外,创建新项目的可能性已被锁定。

创建项目后,将显示一个空的项目页面。您将自动获得该项目的ADMIN状态。通过单击权限按钮添加和删除权限。

如果您具有适当的权限(如果您创建项目,则应该该权限),您可以从该页面删除项目,更新描述,上传文件和查看项目日志
6.2 上传项目
点击上传按钮。您将看到以下对话框。

选择要上传的工作流文件的存档文件。目前,Azkaban只支持xxx.zip文件。zip应包含xxx.job运行作业所需的文件和任何文件。作业名称在项目中必须是唯一的。
Azkaban将验证zip的内容,以确保满足依赖关系,并且没有检测到循环依赖。如果发现任何无效的工作流,上传将失败。
上传覆盖项目中的所有文件。在上传新的zip文件后,对作业所做的任何更改都将被清除。
6.3 工作流视图
通过点击流程链接,您可以转到流程视图页面。从这里,您将看到流程的图形表示。左侧面板包含流程中的作业列表。
右键单击右侧面板中的作业或图形中的节点将允许您打开单个作业。您还可以从此页面计划和执行流程。

单击“执行”选项卡将显示此流程的所有执行记录。

6.4 项目权限
创建项目时,创建者将自动在项目上给予ADMIN状态。这允许创建者查看,上传,更改作业,运行流程,删除并向项目添加用户权限。管理员可以删除其他管理员,但不能删除自己。除非管理员被管理角色的用户删除,否则这会阻止项目成为管理员。
权限页面可从项目页面访问。在权限页面上,管理员可以将其他用户,组或代理用户添加到项目中。

- 添加用户权限为这些用户赋予项目所指定的权限。通过取消选中所有权限来删除用户权限。
- 组权限允许特定组中的每个人指定的权限。通过取消选中所有组权限来删除组权限。
- 如果代理用户已打开,则代理用户允许项目工作流作为这些用户运行。这有助于锁定哪些无头帐户作业可以代理。添加后,点击“删除”按钮即可将其删除。
- 每个用户都通过UserManager进行验证,以防止添加无效用户。组和代理用户也将检查以确保它们是有效的,并查看是否允许管理员将其添加到项目中。
可以为用户和组设置以下权限:
| Permissions | Values |
|---|---|
| ADMIN | 最高权限,包括给其他用户添加、修改权限 |
| READ | 只能访问每一个project的内容和日志信息 |
| WRITE | 可以在已创建的project上传、修改任务的属性,可以删除任何的project |
| EXECUTE | 允许用户执行任何的工作流 |
| SCHEDULE | 允许用户添加、删除任何工作流的调度信息 |
| CREATEPROJECTS | 如果项目创建被锁定,则允许用户创建新项目 |
6.5 执行流程视图
从流程视图面板中,您可以右键单击图形并禁用或启用作业。在执行期间将禁用残留作业,就像它们的依赖关系一样。残障作业将显示半透明。

通知选项 通知选项允许用户更改流程的成功或失败通知行为。
通知失败
- 第一个故障 - 检测到第一个故障后发送故障电子邮件。
- 流程完成 - 如果流程的作业失败,它将在流程中的所有作业完成后发送故障电子邮件。
电子邮件覆盖
Azkaban将使用流中最终作业中设置的默认通知电子邮件。如果被覆盖,用户可以更改发送失败或成功发送电子邮件的电子邮件地址。列表可以用逗号,空格或分号分隔。

故障选项
当流程中的作业失败时,您可以控制其余的流程如何成功。
- 完成当前运行将完成当前运行的作业,但不会启动新作业。FAILED FINISHING一旦完成,流程将被置于状态并设置为失败。
- 取消全部将立即终止所有正在运行的作业,并将执行流程的状态设置为FAILED。
- 完成所有可能会在流程中继续执行作业,只要其依赖性得到满足即可。FAILED FINISHING一旦完成,流程将被置于状态并设置为失败。

并发选项
如果流同时执行时调用流执行,则可以设置多个选项。
- 如果“ 执行”选项已经运行,则不会运行该流。
- 运行并发选项将运行流程,无论它是否运行。执行不同的工作目录。
- 管道以新执行方式不会超过并发执行的方式运行流程。
- 级别1:执行作业A的块,直到上一个流程的作业A完成。
- 级别2:执行作业A的块,直到上一个流程的作业A的孩子已经完成。如果您需要在已执行流程后面运行流程,这将非常有用。

工作流选项
允许用户覆盖工作流参数。工作流参数覆盖作业的全局属性,而不是作业本身的属性

6.6 执行
后执行流程,你将提交执行流程页面。或者,您可以从“ 流程视图”页面的“执行”选项卡,“历史记录”页面或“执行”页面访问这些流程。
此页面类似于“流程视图”页面,但显示运行作业的状态。
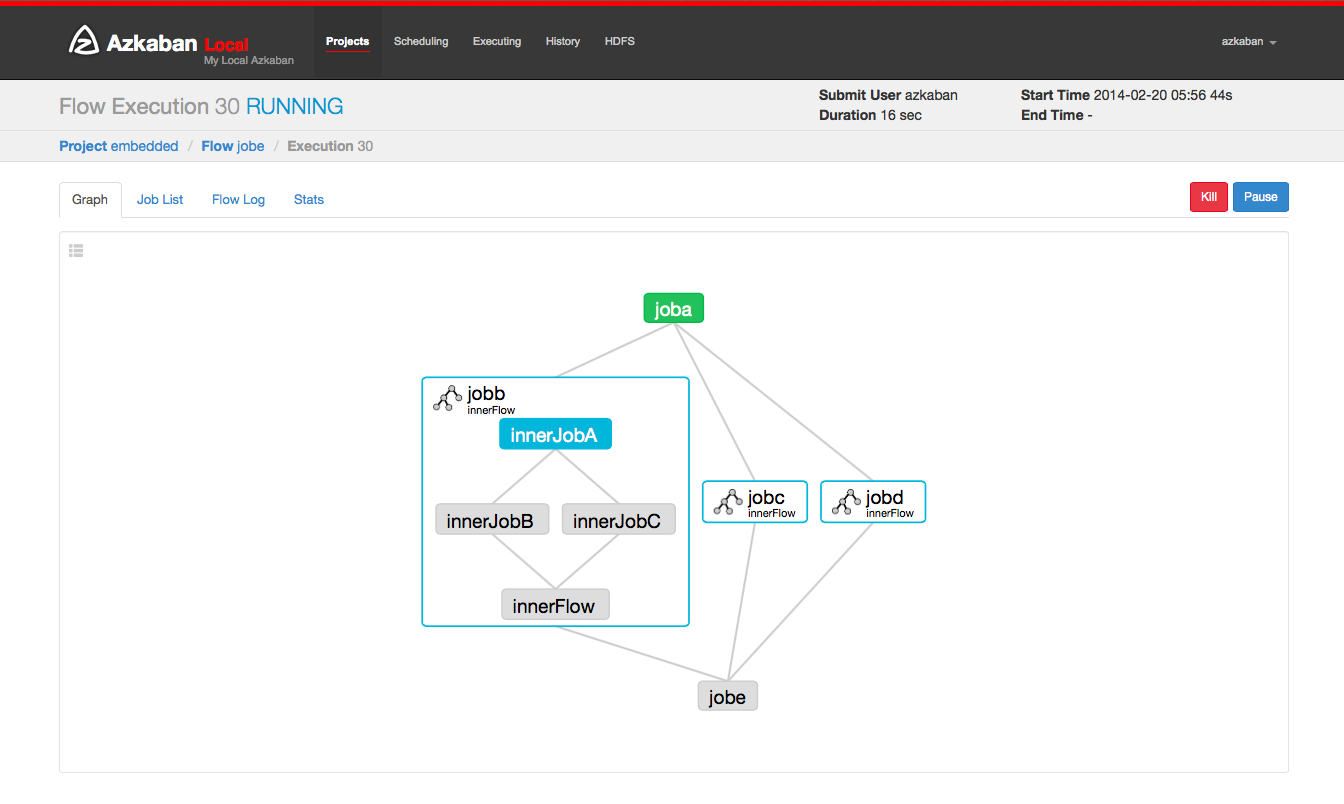
选择工作列表将给出执行工作的时间表。您可以直接从此列表中访问作业和作业日志。

只要执行没有完成,该页面将自动更新。
您可以在执行流程上执行的一些选项包括:
- 取消 - 杀死所有正在运行的作业,并立即失败。流动状态将被杀死。
- 暂停 - 阻止新作业运行。目前运行的作业照常进行。
- 恢复 - 恢复暂停执行。
- 重试失败 - 仅当流程处于FAILED FINISHING状态时可用。当流程仍然活动时,重试将重新启动所有FAILED作业。“尝试”将显示在“作业列表”页面中。
- 准备执行 - 仅在完成的流程中可用,无论成功或失败。这将自动禁用成功完成的作业。
6.7 执行页面
单击标题中的“执行”选项卡将显示“执行”页面。此页面将显示当前运行的执行以及最近完成的流程。

6.8 历史页
当前正在执行的流程以及完成的执行程序将显示在“历史记录”页面中。提供搜索选项来查找您要查找的执行。或者,您可以在“ 流视图执行”选项卡上查看先前执行的流程。

6.9 计划流程
从用于执行流程的同一个面板中,流程可以通过点击* Schedule *按钮进行排定。

将为预定流保留任何流选项集。例如,如果作业被禁用,则预定流程的作业也将被禁用。
使用Azkaban 3.3中的新的灵活调度功能,用户可以在Quartz语法之后定义一个cron作业。与Quartz或cron不同的一个重要变化是Azkaban最多以最小的粒度运作。因此,UI中的第二个字段被标记为静态“0”。该灵活的时间表百科解释了细节如何使用。
安排后,它应该出现在计划页面上,您可以在其中删除计划作业或设置SLA选项。

6.10 SLA
要添加SLA通知或抢占,请单击SLA按钮。从这里您可以设置SLA警报电子邮件。规则可以添加并应用于单个作业或流程本身。如果超过持续时间阈值,则可以设置警报电子邮件,否则流程可能会被自动杀死。
 工作页面 工作组成一个流程的各个任务。要访问作业页面,您可以右键单击流程视图,执行流程视图或项目页面中的作业。
工作页面 工作组成一个流程的各个任务。要访问作业页面,您可以右键单击流程视图,执行流程视图或项目页面中的作业。
6.11 任务页面
在此页面中,您可以查看作业的依赖关系和依赖关系以及作业将使用的全局属性。

6.12 任务编辑
单击作业编辑将允许您编辑除特定保留参数(例如type和)以外的所有作业属性dependencies。只有当作业尚未开始运行时,对参数的更改才会影响执行流程。这些覆盖作业属性将被下一个项目上传覆盖。

6.13 工作历史
任何工作的重试将显示为executionid.attempt数字。

6.14 工作日志
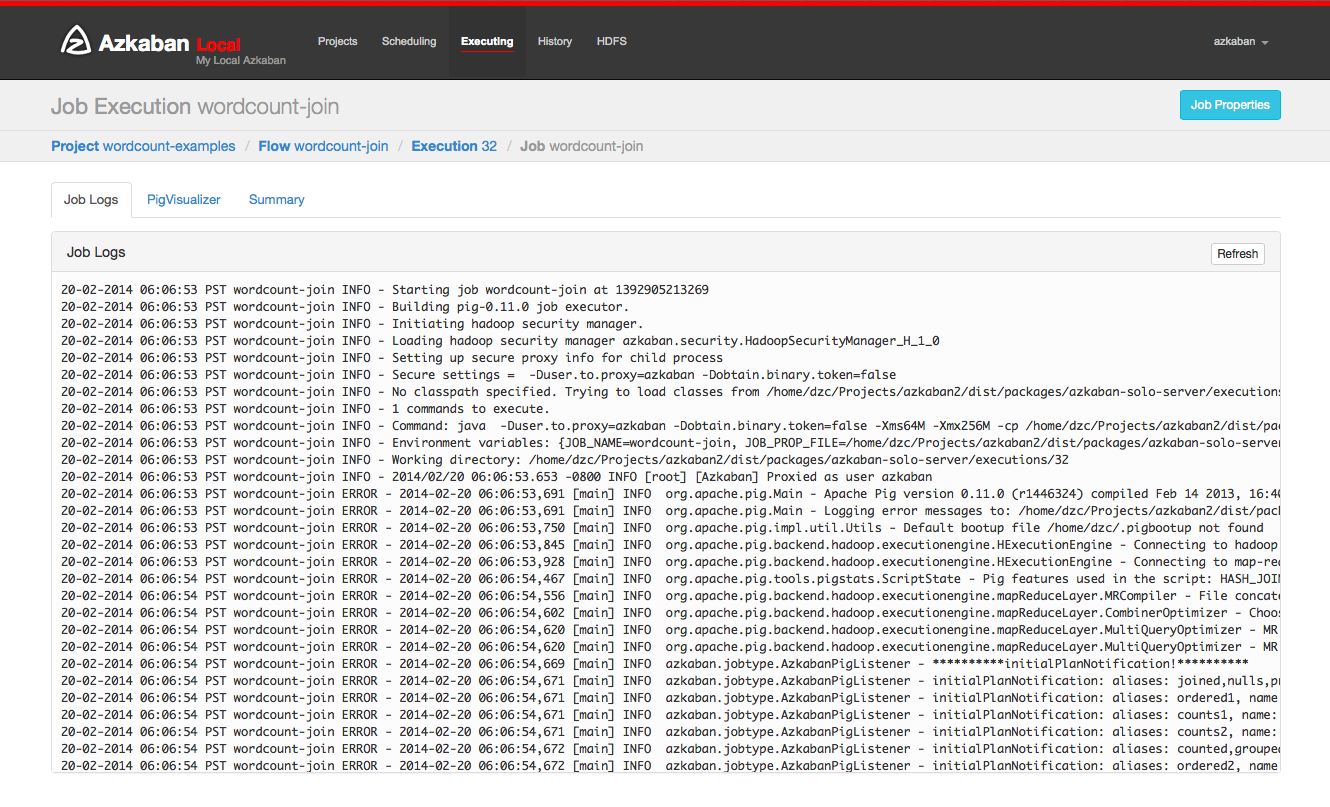
作业日志存储在数据库中。它们包含所有stdout和stderr作业的输出。
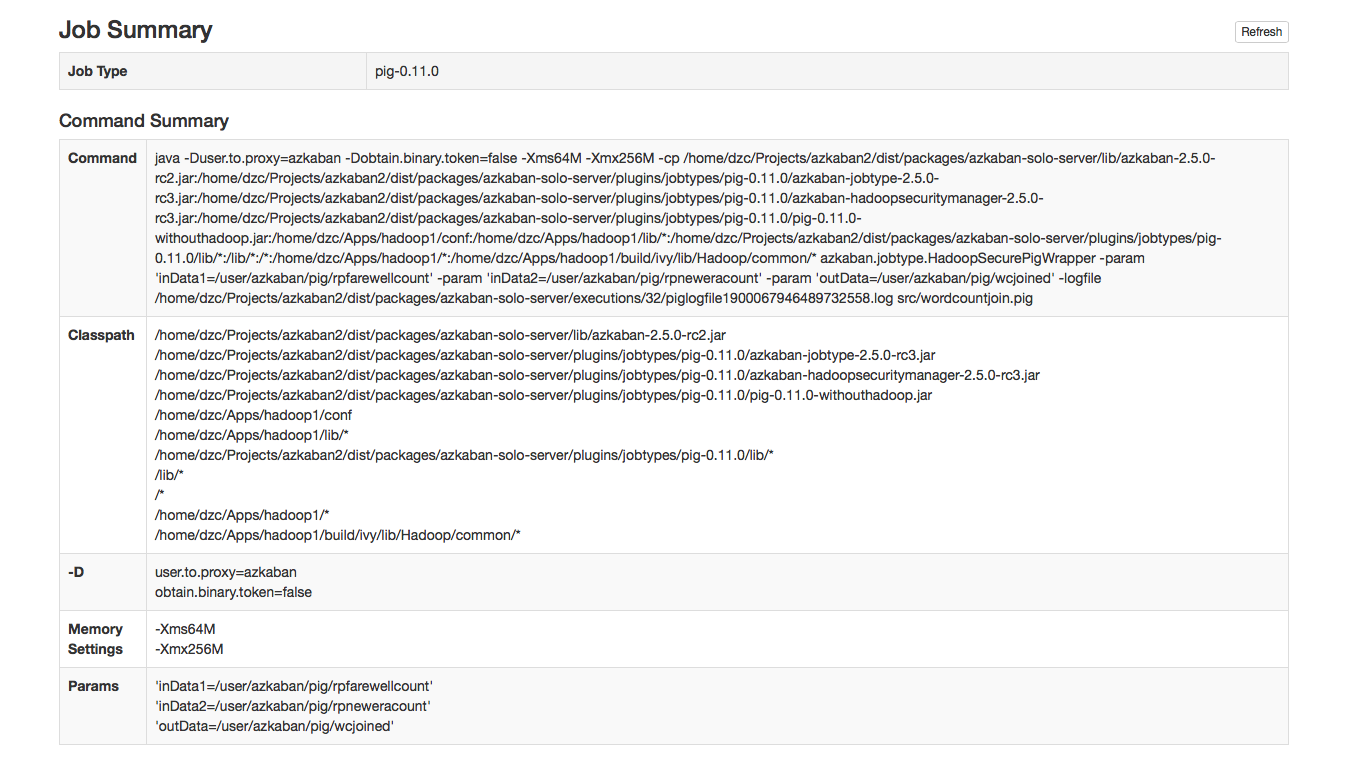
工作总结
- 该作业摘要选项卡包含在作业日志信息的摘要。这包括:
- 作业类型 - 作业的作业类型
- 命令摘要 - 启动作业进程的命令,以及单独显示的类路径和内存设置等字段
- Pig / Hive作业摘要 - Pig和Hive作业的特定定制
- 地图缩小作业 - 将Map-Reduce作业的作业ID列表与已启动的作业链接到其作业跟踪页面
7. Azkaban Job
7.1 串行定时任务工作流
zip目录结构:
|--start.job
|--finish.job
start.job
type=command
command=echo "this is start.job"
finish.job
type=command
dependencies=start
command=echo "this is finish.job"
successEmail=test@example.com
failureEmail=test@example.com
7.2 并行定时任务工作流
zip目录结构:
|--start.job
|--step1.job
|--step2.job
|--step3.job
step1.job
type=command
dependencies=start
command=echo "this is step1.job"
step2.job
type=command
dependencies=start
command=echo "this is step2.job"
step3.job
type=command
dependencies=step1,step2
command=echo "this is step3.job"
7.3 java定时任务工作流
zip目录结构:
|--lib
| |--AzkabanJob.jar
|--azkabanJava.job
AzkabanJob.java
package com.example;
public class AzkabanJob {
public void run() {
// 根据需求编写具体代码
}
public static void main(String[] args) {
AzkabanJob azkabanJob = new AzkabanJob();
azkabanJob.run();
}
}
azkabanJava.job
# azkabanJob.job
type=javaprocess
java.class=com.example.AzkabanJob
classpath=lib/*
7.4 嵌入式定时任务工作流
也可以将工作流作为其他工作流程中的节点包含为嵌入流。要创建一个嵌入式流,只需创建一个.job文件,type=flow并将其flow.name设置为嵌入式工作流的名称。并且嵌入式的工作流是可以单独配置定时任务的,例如:
zip目录结构:
|--bin
| |--flow1.sh
| |--flow2.sh
| |--flow3.sh
|
|--start.job
|--step1.job
|--step2.job
|--flow1.job
|--flow2.job
|--flow3.job
|--subflow1.job
|--subflow2.job
subflow1.job
type=flow
flow.name=flow1
dependencies=start
subflow2.job
type=flow
flow.name=flow2
dependencies=start
flow1.job
type=command
dependencies=step1
command=sh ./bin/flow1.sh
flow2.job
type=command
dependencies=step2
command=sh ./bin/flow2.sh
flow3.job
type=command
dependencies=subflow1,subflow2
command=sh ./bin/flow3.sh
注意:这里的bin目录和所有的.job位于同级目录下,./bin/flow.sh其中的.表示当前目录。
7.5 全局变量
后戳名为.properties的文件将会作为参数文件加载,并且在flow中每个job共享,属性文件通过目录的分层结构继承
zip目录结构
|--common.properties
|--bin
| |--start.sh
| |--finish.sh
|--start.job
|--finish.job
|--flow
| |flow.properties
| |step1
common.properties
start.nofity.email=start@example.com
finish.nofity.email=finish@example.com
step.nofity.email=step@example.com
start.job
type=command
command=sh ./bin/start.sh
notify.emails=${start.nofity.email}
finish.job
type=command
command=sh ./bin/finish.sh
dependencies=start
notify.emails=${finish.nofity.email}
flow.properties
success.email=success@example.com
step.job
type=command
command=echo "this is step"
notify.emails=${step.nofity.email}
success.email=${success.email}
common.properties是全局属性,将会被start.job、finish.job以及flow下的step.job使用,但是start.job和finish.job不能继承flow .properties的属性,因为他是在其下层,而step.job是可以继承flow.properties的。
注意:xxx.properties中声明的属性名不能包含空格,比如${success email}
7.6 Hive Job
hive.job
type=hive
user.to.proxy=Azkaban
azk.hive.action=execute.query
hive.query.01=drop table words;
hive.query.02=create table words (freq int, word string) row format delimited fields terminated by '\t' stored as textfile;
hive.query.03=describe words;
hive.query.04=load data local inpath "res/input" into table words;
hive.query.05=select * from words limit 10;
hive.query.06=select freq, count(1) as f2 from words group by freq sort by f2 desc limit 10;
7.7 Hadoop Job
zip目录结构:
|--system.properties
|--pig.job
|--hadoop.job
system.properties
user.to.proxy=Azkaban
HDFSRoot=/tmp
param.inDataLocal=res/rpfarewell
param.inData=${HDFSRoot}/${user.to.proxy}/wordcountjavain
param.outData=${HDFSRoot}/${user.to.proxy}/wordcountjavaout
pig.job
type=pig
pig.script=src/wordcountpig.pig
user.to.proxy=azkabanHDFS
Root=/tmp
param.inDataLocal=res/rpfarewell
param.inData=${HDFSRoot}/${user.to.proxy}/wordcountpigin
param.outData=${HDFSRoot}/${user.to.proxy}/wordcountpigout
hadoop.job
type=hadoopJava
job.class=azkaban.jobtype.examples.java.WordCount
classpath=./lib/*,${hadoop.home}/lib/*
main.args=${param.inData} ${param.outData}
force.output.overwrite=true
input.path=${param.inData}
output.path=${param.outData}
dependencies=pig
8. Azkaban Job最佳实践
已正式使用Azkaban执行定时任务,下面将以talent项目组的定时任务作为最佳实践代码进行讲解,
目录结构:
meritpay
|
|--conf
| |--application.properties
| |--bootstrap.yml
| |--logback.xml
| |--mybatis-config.xml
|
|--lib
| |--talent-base-0.0.1-SNAPSHOT.jar
| |--talent-meritpay-core-0.0.1-SNAPSHOT.jar
| |--talent-meritpay-job-0.0.1-SNAPSHOT.jar
| |--xxx.jar
|
|--ComputeTask.job
|--DataCheck.job
|--ExecutePlan.job
ExecutePlan.job
type=command
command=java -Xms64m -Xmx1024m -XX:MaxPermSize=64M -Dazkaban.job.id=ExecPlan -jar talent-meritpay-job-0.0.1-SNAPSHOT.jar
ComputeTask.job
type=command
command=java -Xms64m -Xmx1024m -XX:MaxPermSize=64M -Dazkaban.job.id=ExecTask -jar talent-meritpay-job-0.0.1-SNAPSHOT.jar
dependencies=ExecutePlan
DataCheck.job
type=command
command=java -Xms64m -Xmx1024m -XX:MaxPermSize=64M -Dazkaban.job.id=DataCheck -jar talent-meritpay-job-0.0.1-SNAPSHOT.jar
dependencies=ComputeTask
9. Azkaban Ajax API
azkaban也提供了API接口来使用,这样可以基于azkaban实现自己的管理方式,这些接口是通过HTTPS的方式与web服务器进行通信的,因为在azkaban中有用户和权限的概念,所以在调用API之前需要登录,登录成功之后会返回用户一个session id,之后所有的操作都需要携带这个id以判断用户是否有权限。如果session id无效,那么调用API会返回"error" : "session"的信息,如果不携带session.id参数,会返回登陆界面的html文件内容(有些session id的访问也会返回这样的内容)。azkaban提供的API包括:具体请参照官方文档:http://azkaban.github.io/azkaban/docs/latest/#ajax-api
9.1 Authenticate
用户登录操作,需要携带用户名和密码,如果成功登录则返回一个session id用于之后的请求。
请求参数:
| 参数 | 描述 |
|---|---|
| action=login | 登录操作(固定参数) |
| username | Azkaban用户 |
| password | Azkaban密码 |
实例代码:
curl -k -X POST --data "action=login&username=azkaban&password=azkaban" https://localhost:8443
返回结果:
{
"status" : "success",
"session.id" : "c001aba5-a90f-4daf-8f11-62330d034c0a"
}
9.2 Create a Project
创建一个新的project,这需要在任何关于这个project操作之前进行,需要输入project的name作为这个project的唯一标示,还需要包含这个project的描述信息,其实和在web 页面上创建project的输入一样。
请求参数:
| 参数 | 描述 |
|---|---|
| session.id | 用户登录成功返回的session.id |
| action=create | 创建项目操作(固定参数) |
| name | 项目名称 |
| description | 项目描述 |
实例:
curl -k -X POST --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&name=MyProject&description=test" https://localhost:8443/manager?action=create
返回结果:
{
"status":"success",
"path":"manager?project=MyProject",
"action":"redirect"
}
9.3 Delete a Project
删除一个已经存在的project,该请求没有回复信息,需要输入project的标识。
请求参数:
| 参数 | 描述 |
|---|---|
| session.id | 用户登录成功返回的session.id |
| delete=true | 删除项目操作(固定参数) |
| project | 项目名称 |
实例:
curl -k -X POST --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&delete=true&project=azkaban" https://localhost:8443/manager
9.4 Upload a Project Zip
上传一个zip文件到一个project,一般在创建一个project完成之后,之后的上传将覆盖以前上传的内容。
请求参数:
| 参数 | 描述 |
|---|---|
| session.id | 用户登录成功返回的session.id |
| ajax=upload | 上传作业流操作(固定参数) |
| project | 项目名称 |
| file | 项目zip文件,上传类型必须是application/zip或application/x-zip-compressed |
实例:
curl -k -i -H "Content-Type: multipart/mixed" -X POST --form 'session.id=c001aba5-a90f-4daf-8f11-62330d034c0a' --form 'ajax=upload' --form 'file=@myproject.zip;type=application/zip' --form 'project=MyProject;type/plain' https://localhost:8443/manager
返回结果:
{
"error" : "Installation Failed.\nError unzipping file.",
"projectId" : "192",
"version" : "1"
}
9.5 Fetch Flows of a Project
获取一个project下的所有flow信息,输入需要指定project的标识,一个project下面可能存在多个flow,输出的flow只包含flowId标识每一个flow。
请求参数:
| 参数 | 描述 |
|---|---|
| session.id | 用户登录成功返回的session.id |
| ajax=fetchprojectflows | 获取项目作业流操作(固定参数) |
| project | 项目名称 |
实例:
curl -k --get --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&ajax=fetchprojectflows&project=MyProject"
https://localhost:8443/manager
返回结果:
{
"project" : "MyProject",
"projectId" : 192,
"flows" : [ {
"flowId" : "test"
}, {
"flowId" : "test2"
} ]
}
9.6 Fetch Jobs of a Flow
获取一个flow下所有job的信息,因为在API端每个命令都是独立的,所以这里需要输入project的标识和flow的标识,输出包含每一个job的信息,包括job的标识(id)、job 类型以及这个job直接以来的job。
请求参数:
| 参数 | 描述 |
|---|---|
| session.id | 用户登录成功返回的session.id |
| ajax=fetchflowgraph | 获取作业操作(固定参数) |
| project | 项目名称 |
| flow | 作业流ID |
实例:
curl -k --get --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&ajax=fetchflowgraph&project=MyProject&flow=test"
https://localhost:8443/manager
返回结果:
{
"project" : "MyProject",
"nodes" : [ {
"id" : "test-final",
"type" : "command",
"in" : [ "test-job-3" ]
}, {
"id" : "test-job-start",
"type" : "java"
}, {
"id" : "test-job-3",
"type" : "java",
"in" : [ "test-job-2" ]
}, {
"id" : "test-job-2",
"type" : "java",
"in" : [ "test-job-start" ]
} ],
"flow" : "test",
"projectId" : 192
}
9.7 Fetch Executions of a Flow
获取flow的执行情况,需要制定特定的project和flow,这个接口可以分页返回,所以需要制定start指定开始的index和length指定返回的个数,因为每一个flow 都可以单独的或者作为其他flow的子flow执行,这里返回该flow指定区间内的每一次执行的信息。每一个执行信息包括起始时间、提交执行的用户、执行的状态、提交时间、这次执行在全局的id(递增的execid),projectid、结束时间和flowId。
请求参数:
| 参数 | 描述 |
|---|---|
| session.id | 用户登录成功返回的session.id |
| ajax=fetchFlowExecutions | 获取项目作业流信息操作(固定参数) |
| project | 项目名称 |
| flow | 作业流ID |
| start | 获取执行的开始索引 |
| length | 获取作业执行的记录数 |
实例:
curl -k --get --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&ajax=fetchFlowExecutions&project=MyProject&flow
=test&start=0&length=1" https://localhost:8443/manager
返回结果:
{
"executions" : [ {
"startTime" : 1407779928865,
"submitUser" : "1",
"status" : "FAILED",
"submitTime" : 1407779928829,
"execId" : 306,
"projectId" : 192,
"endTime" : 1407779950602,
"flowId" : "test"
}],
"total" : 16,
"project" : "MyProject",
"length" : 1,
"from" : 0,
"flow" : "test",
"projectId" : 192
}
9.8 Fetch Running Executions of a Flow
获取当前正在执行的flow的执行信息,输入包括project和flow的标识,返回的是该flow正在执行的所有执行id(全局的exec id)。
请求参数:
| 参数 | 描述 |
|---|---|
| session.id | 用户登录成功返回的session.id |
| ajax=getRunning | 获取项目正在执行作业流操作(固定参数) |
| project | 项目名称 |
| flow | 作业流ID |
实例:
curl -k --get --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&ajax=getRunning&project=MyProject&flow=test"
https://localhost:8443/executor
返回结果:
{
"execIds": [301, 302]
}
9.9 Execute a Flow
启动一个flow的执行,这个输入比较多,因为在web界面上每次启动flow的执行都需要设置几项配置,可以在该接口设置出了调度之外的乞讨配置信息,输入还需要包括project和flow 的标识,输出为这个flow的id和本次执行的exec id
| 参数 | 描述 |
|---|---|
| session.id | 用户登录成功返回的session.id |
| ajax=executeFlow | 执行作业流操作(固定参数) |
| project | 项目名称 |
| flow | 作业流ID |
| disabled (optional) | 本次执行需要被禁止执行的作业列表 ["job_name_1", "job_name_2"] |
| successEmails (optional) | 执行成功邮件列表foo@email.com,bar@email.com |
| failureEmails (optional) | 执行成功邮件列表foo@email.com,bar@email.com |
| successEmailsOverride (optional) | 是否用系统默认配置的成功邮件来覆盖,true或false |
| failureEmailsOverride (optional) | 是否用系统默认配置的失败邮件来覆盖,true或false |
| notifyFailureFirst (optional) | 只要发生第一个故障发送执行失败邮件,true或false |
| notifyFailureLast (optional) | 只要发生最后一个故障发送执行失败邮件,true或false |
| failureAction (Optional) | 如果发生故障,如何执行:finishCurrent, cancelImmediately, finishPossible |
| concurrentOption (Optional) | 并发选择:ignore, pipeline, queue |
| flowOverrideflowProperty | 使用指定值覆盖指定作业流属性:flowOverride[failure.email]=test@gmail.com |
实例:
curl -k --get --data 'session.id=c001aba5-a90f-4daf-8f11-62330d034c0a' --data 'ajax=executeFlow' --data
'project=MyProject' --data 'flow=test' https://localhost:8443/executor
返回结果:
{
message: "Execution submitted successfully with exec id 295",
project: "foo-demo",
flow: "test",
execid: 295
}
9.10 Cancel a Flow Execution
取消一次flow的执行,需要输入的是全局的exec
请求参数:
| 参数 | 描述 |
|---|---|
| session.id | 用户登录成功返回的session.id |
| ajax=cancelFlow | 取消正在执行的作业流(固定参数) |
| execid | 正在执行的作业流ID |
实例:
curl -k --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&ajax=cancelFlow&execid=302" https://localhost:8443/executor
返回结果:
{
"error" : "Execution 302 of flow test isn't running."
}
9.11 Flexible scheduling using Cron
使用时间表达式灵活配置定时任务
请求参数:
| 参数 | 描述 |
|---|---|
| session.id | 用户登录成功返回的session.id |
| ajax=scheduleCronFlow | 使用定时表达式配置作业流定时任务(固定参数) |
| projectName | 项目名称 |
| flowName | 作业流ID |
| cronExpression | cron时间表达式,在Azkaban中,使用的是Quartz时间表达式格式 |
实例:
curl -k -d ajax=scheduleCronFlow -d projectName=wtwt -d flow=azkaban-training --data-urlencode cronExpression="0 23/30 5,7-10 ? * 6#3" -b "azkaban.browser.session.id=c001aba5-a90f-4daf-8f11-62330d034c0a" http://localhost:8081/schedule
返回结果:
{
"message" : "PROJECT_NAME.FLOW_NAME scheduled.",
"status" : "success"
}
9.12 Fetch a Schedule
根据项目名称和作业流ID获取其对应的时间定时任务信息
请求参数:
| 参数 | 描述 |
|---|---|
| session.id | 用户登录成功返回的session.id |
| ajax=fetchSchedule | 获取定时任务操作(固定参数) |
| projectId | 项目ID |
| flowId | 作业流ID |
| cronExpression | cron时间表达式,在Azkaban中,使用的是Quartz时间表达式格式 |
实例:
curl -k --get --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&ajax=fetchSchedule&projectId=1&flowId=test" http://localhost:8081/schedule
返回结果:
{
"schedule" : {
"cronExpression" : "0 * 9 ? * *",
"nextExecTime" : "2017-04-01 09:00:00",
"period" : "null",
"submitUser" : "azkaban",
"executionOptions" : {
"notifyOnFirstFailure" : false,
"notifyOnLastFailure" : false,
"failureEmails" : [ ],
"successEmails" : [ ],
"pipelineLevel" : null,
"queueLevel" : 0,
"concurrentOption" : "skip",
"mailCreator" : "default",
"memoryCheck" : true,
"flowParameters" : {
},
"failureAction" : "FINISH_CURRENTLY_RUNNING",
"failureEmailsOverridden" : false,
"successEmailsOverridden" : false,
"pipelineExecutionId" : null,
"disabledJobs" : [ ]
},
"scheduleId" : "3",
"firstSchedTime" : "2017-03-31 11:45:21"
}
}
9.13 Unschedule a Flow
取消作业流的定时配置
请求参数:
| 参数 | 描述 |
|---|---|
| session.id | 用户登录成功返回的session.id |
| ajax=removeSched | 删除作业流定时配置操作(固定参数) |
| scheduleId | 定时配置ID |
实例:
curl -k https://HOST:PORT/schedule -d "action=removeSched&scheduleId=3" -b azkaban.browser.session.id=c001aba5-a90f-4daf-8f11-62330d034c0a
返回结果:
{
"message" : "flow FLOW_NAME removed from Schedules.",
"status" : "success"
}
- Pause a Flow Execution
暂停一次执行,输入为exec id。如果这个执行不是处于running状态,会返回错误信息。
请求参数:
| 参数 | 描述 |
|---|---|
| session.id | 用户登录成功返回的session.id |
| ajax=removeSched | 删除作业流定时配置操作(固定参数) |
| scheduleId | 定时配置ID |
实例:
curl -k https://HOST:PORT/schedule -d "action=removeSched&scheduleId=3" -b azkaban.browser.session.id=c001aba5-a90f-4daf-8f11-62330d034c0a
返回结果:
{
"message" : "flow FLOW_NAME removed from Schedules.",
"status" : "success"
}
9.14 Resume a Flow Execution
重新启动一次执行,输入为exec id,如果这次执行已经在进行,不返回任何错误,如果它不再运行则返回错误信息。
请求参数:
| 参数 | 描述 |
|---|---|
| session.id | 用户登录成功返回的session.id |
| ajax=pauseFlow | 暂停正在执行的作业流操作(固定参数) |
| execid | 执行ID |
实例:
curl -k --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&ajax=pauseFlow&execid=303" https://localhost:8443/executor
返回结果:
{
"error" : "Execution 303 of flow test isn't running."
}
9.15 Resume a Flow Execution
给定一个exec id,该API将恢复暂停的运行流程。如果执行已经被恢复,它不会返回任何错误; 如果执行没有运行,它将返回一条错误消息。
请求参数:
| 参数 | 描述 |
|---|---|
| session.id | 用户登录成功返回的session.id |
| ajax=resumeFlow | 暂停正在执行的作业流操作(固定参数) |
| execid | 执行ID |
实例:
curl -k --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&ajax=resumeFlow&execid=303" https://localhost:8443/executor
返回结果:
{
"error" : "Execution 303 of flow test isn't running."
}
9.16 Fetch a Flow Execution
获取一次执行的所有信息,输入为exec id,输出包括这次执行的属性(参见7),还包括这次执行的所有的job的执行情况。
请求参数:
| 参数 | 描述 |
|---|---|
| session.id | 用户登录成功返回的session.id |
| ajax=fetchexecflow | 获取作业流详细信息(固定参数) |
| scheduleId | 定时配置ID |
实例:
curl -k --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&ajax=fetchexecflow&execid=304" https://localhost:8443/executor
返回结果:
{
"attempt" : 0,
"submitUser" : "1",
"updateTime" : 1407779495095,
"status" : "FAILED",
"submitTime" : 1407779473318,
"projectId" : 192,
"flow" : "test",
"endTime" : 1407779495093,
"type" : null,
"nestedId" : "test",
"startTime" : 1407779473354,
"id" : "test",
"project" : "test-azkaban",
"nodes" : [ {
"attempt" : 0,
"startTime" : 1407779495077,
"id" : "test",
"updateTime" : 1407779495077,
"status" : "CANCELLED",
"nestedId" : "test",
"type" : "command",
"endTime" : 1407779495077,
"in" : [ "test-foo" ]
}],
"flowId" : "test",
"execid" : 304
}
9.17 Fetch Execution Job Logs
获取一次执行中的一个job的执行日志,可以将job的执行日志作为一个文件,这里需要制定exec
请求参数:
| 参数 | 描述 |
|---|---|
| session.id | 用户登录成功返回的session.id |
| ajax=fetchExecJobLogs | 获取执行作业日志信息(固定参数) |
| execid | 执行ID |
| jobId | 作业ID |
| offset | 日志信息偏移量 |
| length | 日志信息长度 |
实例:
curl -k --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&ajax=fetchExecJobLogs&execid=297&jobId=test-foobar&offset=0&length=100" https://localhost:8443/executor
返回结果:
{
"data" : "05-08-2014 16:53:02 PDT test-foobar INFO - Starting job test-foobar at 140728278",
"length" : 100,
"offset" : 0
}
9.18 Fetch Flow Execution Updates
这个是返回上次查看之后每个任务的执行情况?这个有点疑惑。应该是在flow执行的时候执行进度的信息获取。
请求参数:
| 参数 | 描述 |
|---|---|
| session.id | 用户登录成功返回的session.id |
| ajax=fetchexecflowupdate | 删除作业流定时配置操作(固定参数) |
| execid | 执行ID |
| lastUpdateTime | 最后更新时间,如果只为-1表示需要所有作业的信息 |
实例:
curl -k --data "execid=301&lastUpdateTime=-1&session.id=c001aba5-a90f-4daf-8f11-62330d034c0a" https://localhost:8443/executor?ajax=fetchexecflowupdate
返回结果:
{
"id" : "test",
"startTime" : 1407778382894,
"attempt" : 0,
"status" : "FAILED",
"updateTime" : 1407778404708,
"nodes" : [ {
"attempt" : 0,
"startTime" : 1407778404683,
"id" : "test",
"updateTime" : 1407778404683,
"status" : "CANCELLED",
"endTime" : 1407778404683
}, {
"attempt" : 0,
"startTime" : 1407778382913,
"id" : "test-job-1",
"updateTime" : 1407778393850,
"status" : "SUCCEEDED",
"endTime" : 1407778393845
}, {
"attempt" : 0,
"startTime" : 1407778393849,
"id" : "test-job-2",
"updateTime" : 1407778404679,
"status" : "FAILED",
"endTime" : 1407778404675
}, {
"attempt" : 0,
"startTime" : 1407778404675,
"id" : "test-job-3",
"updateTime" : 1407778404675,
"status" : "CANCELLED",
"endTime" : 1407778404675
} ],
"flow" : "test",
"endTime" : 1407778404705
}
从这里的接口可以看出,azkaban提供的API只能用于简单创建project、flow,查看project、flow、execute等操作,而web界面的操作要比这丰富得多,如果我们希望基于azkaban进行开发的话,在这些接口的基础上,我觉得还可以对azkaban的数据库进行分析,从数据库中得到我们想要的信息(基本的写操作都能够通过这些API实现,所以我们只需要从数据库中读取)。但是这样相对于使用API还是有个弊端,毕竟随着版本的更新数据库的结构可能会发生变化,但是这也不失为一种方式。
10. Azkaban插件
10.1 Hadoop Security
Azkaban最常用在Hadoop等大数据平台中。Azkaban的作业类型插件系统允许大多数灵活的支持这些系统。
Azkaban能够支持所有Hadoop版本,支持Hadoop Security功能; Azkaban能够支持各种不同版本的生态系统组件,如同一个实例中的不同版本的pig,hive。
Hadoop Security最常见的实现方式是依赖HadoopSecurityManager通过安全方式与Hadoop集群进行通信和确保Hadoop的安全。
具体请参考Hadoop Security
10.2 Azkaban HDFS浏览器
Azkaban HDFS浏览器是一个插件,可以让您查看HDFS FileSystem并解码多种文件类型。它最初创建于LinkedIn,以查看Avro文件,Linkedin的BinaryJson格式和文本文件。随着这个插件进一步成熟,我们可能会在将来添加不同文件类型的解码。
下载HDFS插件,并将其解压缩到Web服务器的插件目录中,默认目录是/azkaban-web-server/plugins/viewer/
具体请参考HDFS Browser
10.3 Jobtype插件
Jobtype插件确定单个作业在本地或远程群集上的实际运行情况。它提供了很大的便利:可以添加或更改任何工作类型,而不用接触Azkaban核心代码; 可以轻松地扩展Azkaban来运行不同的hadoop版本或分发版本; 在添加相同类型的新版本的同时,可以保留旧版本。但是,由管理这些插件的管理员来确保安装和配置正确。
在AzkabanExecutorServer启动后,Azkaban将尝试加载所有可以找到的作业类型插件。Azkaban将做非常简单的测试和丢掉坏的。应该总是尝试运行一些测试作业,以确保工作类型真正按预期工作。
具体请参考JobType Plugins

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









