







题目原文:
274. H-Index
Given an array of citations (each citation is a non-negative integer) of a researcher, write a function to compute the researcher’s h-index.
According to the definition of h-index on Wikipedia: “A scientist has index h if h of his/her N papers have at least h citations each, and the other N − h papers have no more than h citations each.”
For example, given citations = [3, 0, 6, 1, 5], which means the researcher has 5 papers in total and each of them had received 3, 0, 6, 1, 5 citations respectively. Since the researcher has 3 papers with at least 3 citations each and the remaining two with no more than 3 citations each, his h-index is 3.
275.H−IndexII
Follow up for H-Index: What if the citations array is sorted in ascending order? Could you optimize your algorithm?
题目大意:
274.H−Index
给出一个研究者的引用量数组,写一个算法计算这个研究者的h指数。
H指数的定义:一个人的h指数是指在一定期间内他发表的论文至少有h篇的被引频次不低于h次。
例如,给出citations数组=[3,0,6,1,5],代表这个研究者写了5篇论文,引用次数分别是3,0,6,1,5.那么他的h值是3,因为有3篇论文的引用次数>=3次。
275.H−IndexII
若citations数组是升序排列的,能否优化算法?
题目分析:
根据wiki中给出的算法:
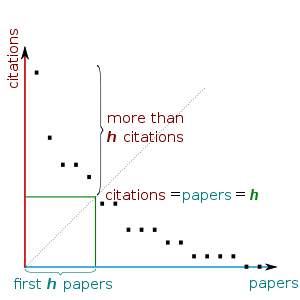
把引用数降序排列画在坐标系中,位于直线y=x上面的点个数就是h值。由于本题中引用数是降序排列的,所以改为统计位于直线x+y=n(n为论文数目)上方点的数目即可。因为数组是有序的,所以可以使用二分查找。
源码:(language:java)
public class Solution {
public int hIndex(int[] citations) {
int count=0,length = citations.length;
int start=0,end=length-1,mid=0;
while(start<=end) {
mid = (start+end) / 2;
if(citations[mid] >= length-mid) {
if(mid==0 || citations[mid-1]<length-mid+1)
return length-mid;
else if(citations[mid-1]>=length-mid)
end=mid-1;
}
else
start=mid+1;
}
return 0;
}
}成绩:
H-Index:4ms,beats 9.28%,众数1ms,38.82%
H-Index II:13ms,beats 31.68%,众数12ms,24.72%
Cmershen的碎碎念:
在第一题中,使用二分查找比无脑查找慢,但第二题中无脑插的耗时是213ms,远差于二分查找。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









