









用python实现汉字转拼音工具
主要功能特点:
- 多种拼音风格选择(带声调符号、数字声调、无声调)
- 输出模式:可以选择“普通模式”(仅拼音)或“拼音注音”(每个汉字的拼音显示在上方)
- 可自定义分隔符,可以自定义拼音之间的分隔符(默认空格)
- 标点符号保留选项,关闭时会自动过滤非汉字字符
- 支持文件导入/导出(文本文件)
- 一键复制结果到剪贴板
基本实现
程序需要你安装pypinyin和pyperclip这两个第三方库/模块(若你未安装的话)。
pypinyin:用于将汉字转换为拼音。
pyperclip:跨平台的剪贴板操作库,可以用来复制和粘贴文本到系统的剪贴板。
还用到了Python 的一些标准库,它们通常不需要安装,一般会随 Python 一起安装。
运行界面如下:
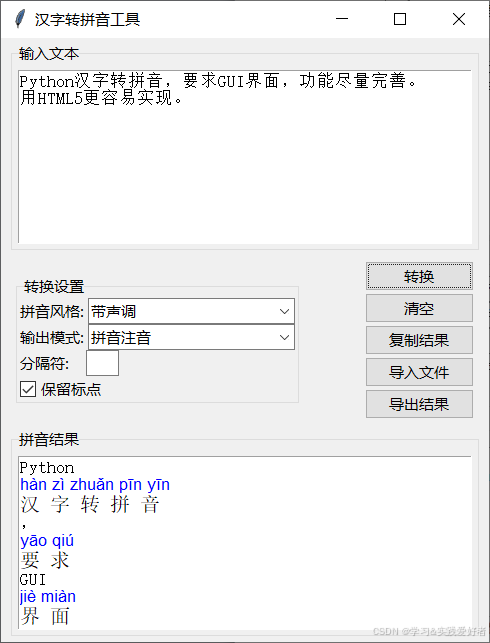
源码如下:
import tkinter as tk
from tkinter import ttk, filedialog, messagebox, font
from pypinyin import pinyin, Style
import pyperclip
import os
import re
class PinyinConverter:
def __init__(self, root):
self.root = root
self.root.title("汉字转拼音工具")
self.setup_ui()
self.set_default_values()
def set_default_values(self):
self.style_var.set('带声调')
self.separator_var.set(' ')
#self.handle_polyphonic_var.set(0)
self.keep_punctuation_var.set(1)
self.output_mode_var.set('普通模式')
def setup_ui(self):
# 输入区域
input_frame = ttk.LabelFrame(self.root, text="输入文本")
input_frame.grid(row=0, column=0, padx=10, pady=5, sticky='nsew')
self.input_text = tk.Text(input_frame, height=10, width=50, wrap='word')
self.input_text.pack(padx=5, pady=5, fill='both', expand=True)
# 控制面板
control_frame = ttk.Frame(self.root)
control_frame.grid(row=1, column=0, padx=10, pady=5, sticky='ew')
# 样式设置
style_frame = ttk.LabelFrame(control_frame, text="转换设置")
style_frame.pack(side=tk.LEFT, padx=5, pady=2)
# 拼音样式
ttk.Label(style_frame, text="拼音风格:").grid(row=0, column=0, sticky='w')
self.style_var = tk.StringVar()
styles = {
'带声调': Style.TONE,
'数字声调': Style.TONE3,
'无声调': Style.NORMAL
}
self.style_combobox = ttk.Combobox(
style_frame, textvariable=self.style_var,
values=list(styles.keys()), state='readonly')
self.style_combobox.grid(row=0, column=1, padx=2)
# 输出模式
ttk.Label(style_frame, text="输出模式:").grid(row=1, column=0, sticky='w')
self.output_mode_var = tk.StringVar()
modes = ['普通模式', '拼音注音']
self.mode_combobox = ttk.Combobox(
style_frame, textvariable=self.output_mode_var,
values=modes, state='readonly')
self.mode_combobox.grid(row=1, column=1, padx=2)
# 分隔符
ttk.Label(style_frame, text="分隔符:").grid(row=2, column=0, sticky='w')
self.separator_var = tk.StringVar()
ttk.Entry(style_frame, textvariable=self.separator_var, width=3).grid(row=2, column=1, sticky='w')
# 高级选项
## self.handle_polyphonic_var = tk.IntVar()
## ttk.Checkbutton(
## style_frame, text="处理多音字",
## variable=self.handle_polyphonic_var).grid(row=3, column=0, columnspan=2, sticky='w')
self.keep_punctuation_var = tk.IntVar()
ttk.Checkbutton(
style_frame, text="保留标点",
variable=self.keep_punctuation_var).grid(row=4, column=0, columnspan=2, sticky='w')
# 操作按钮
btn_frame = ttk.Frame(control_frame)
btn_frame.pack(side=tk.RIGHT, padx=5)
ttk.Button(btn_frame, text="转换", command=self.convert).pack(side=tk.TOP, fill=tk.X)
ttk.Button(btn_frame, text="清空", command=self.clear_text).pack(side=tk.TOP, fill=tk.X, pady=2)
ttk.Button(btn_frame, text="复制结果", command=self.copy_result).pack(side=tk.TOP, fill=tk.X)
ttk.Button(btn_frame, text="导入文件", command=self.import_file).pack(side=tk.TOP, fill=tk.X, pady=2)
ttk.Button(btn_frame, text="导出结果", command=self.export_result).pack(side=tk.TOP, fill=tk.X)
# 输出区域
output_frame = ttk.LabelFrame(self.root, text="拼音结果")
output_frame.grid(row=2, column=0, padx=10, pady=5, sticky='nsew')
self.output_text = tk.Text(output_frame, height=10, width=50, wrap='word')
self.output_text.pack(padx=5, pady=5, fill='both', expand=True)
# 配置标签和字体
# 配置标签和字体 - 修正这里的font导入问题
self.pinyin_font = font.Font(family="Arial", size=10) # 使用正确导入的font
self.hanzi_font = font.Font(family="SimSun", size=12)
self.output_text.tag_configure("pinyin", font=self.pinyin_font, foreground="blue")
self.output_text.tag_configure("hanzi", font=self.hanzi_font)
# 布局配置
self.root.columnconfigure(0, weight=1)
self.root.rowconfigure(0, weight=1)
self.root.rowconfigure(2, weight=1)
def convert(self):
try:
input_str = self.input_text.get("1.0", tk.END).strip()
if not input_str:
return
style_mapping = {
'带声调': Style.TONE,
'数字声调': Style.TONE3,
'无声调': Style.NORMAL
}
style = style_mapping[self.style_var.get()]
separator = self.separator_var.get()
keep_punctuation = bool(self.keep_punctuation_var.get())
output_mode = self.output_mode_var.get()
self.output_text.delete(1.0, tk.END)
if output_mode == '普通模式':
# 普通模式:直接输出拼音
pinyin_list = pinyin(
input_str,
style=style,
# heteronym=bool(self.handle_polyphonic_var.get()),
errors='ignore' if not keep_punctuation else lambda x: x
)
result = []
for word in pinyin_list:
selected = word[0] if word else ''
result.append(selected + separator)
self.output_text.insert(tk.END, ''.join(result).strip())
else:
# 拼音注音模式
# 将文本分割成连续的汉字段落和非汉字段落
segments = []
current_segment = ""
current_type = None # 0 for non-Chinese, 1 for Chinese
for char in input_str:
is_chinese = '\u4e00' <= char <= '\u9fff'
char_type = 1 if is_chinese else 0
if current_type is None:
current_type = char_type
current_segment = char
elif current_type == char_type:
current_segment += char
else:
segments.append((current_segment, current_type))
current_segment = char
current_type = char_type
if current_segment:
segments.append((current_segment, current_type))
# 处理每个段落
for segment_text, is_chinese in segments:
if is_chinese:
# 处理汉字段落
py_results = pinyin(
segment_text,
style=style,
# heteronym=bool(self.handle_polyphonic_var.get())
)
# 创建拼音行
py_line = ""
for py in py_results:
py_text = py[0] if py else ''
py_line += py_text + " "
# 创建汉字行,确保每个汉字有足够空间对应拼音
hz_line = ""
for char in segment_text:
hz_line += char + " "
# 插入拼音和汉字
self.output_text.insert(tk.END, py_line + "\n", "pinyin")
self.output_text.insert(tk.END, hz_line + "\n", "hanzi")
else:
# 处理非汉字段落
self.output_text.insert(tk.END, segment_text + "\n")
except Exception as e:
import traceback
error_details = traceback.format_exc()
messagebox.showerror("错误", f"转换失败: {str(e)}\n\n详细信息:\n{error_details}")
def clear_text(self):
self.input_text.delete(1.0, tk.END)
self.output_text.delete(1.0, tk.END)
def copy_result(self):
result = self.output_text.get(1.0, tk.END).strip()
if result:
pyperclip.copy(result)
messagebox.showinfo("成功", "已复制到剪贴板")
def import_file(self):
file_path = filedialog.askopenfilename(
filetypes=[("文本文件", "*.txt"), ("所有文件", "*.*")])
if file_path:
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
self.input_text.delete(1.0, tk.END)
self.input_text.insert(tk.END, content)
except Exception as e:
messagebox.showerror("错误", f"文件读取失败: {str(e)}")
def export_result(self):
result = self.output_text.get(1.0, tk.END).strip()
if not result:
return
file_path = filedialog.asksaveasfilename(
defaultextension=".txt",
filetypes=[("文本文件", "*.txt"), ("所有文件", "*.*")])
if file_path:
try:
with open(file_path, 'w', encoding='utf-8') as f:
f.write(result)
messagebox.showinfo("成功", "文件保存成功")
except Exception as e:
messagebox.showerror("错误", f"文件保存失败: {str(e)}")
if __name__ == "__main__":
root = tk.Tk()
app = PinyinConverter(root)
root.mainloop()
改进版
在“拼音注音”模式下,拼音和汉字之间的对齐处理计较困难。
使用HTML5来实现汉字转拼音工具(特别是拼音注音功能)更加容易和灵活,浏览器中的渲染效果更好。
这个改进版方案,当用户选择"拼音注音"模式并点击转换后,程序会生成HTML文件并保存到临时目录。用户可以点击"在浏览器中查看"按钮来查看渲染效果。结果也会显示在文本区域中(以HTML源码形式)。
这种方法避免了在Tkinter窗口中嵌入复杂渲染引擎的问题,充分利用了系统浏览器的强大功能,同时保持了程序的简单性和稳定性。
运行界面如下:
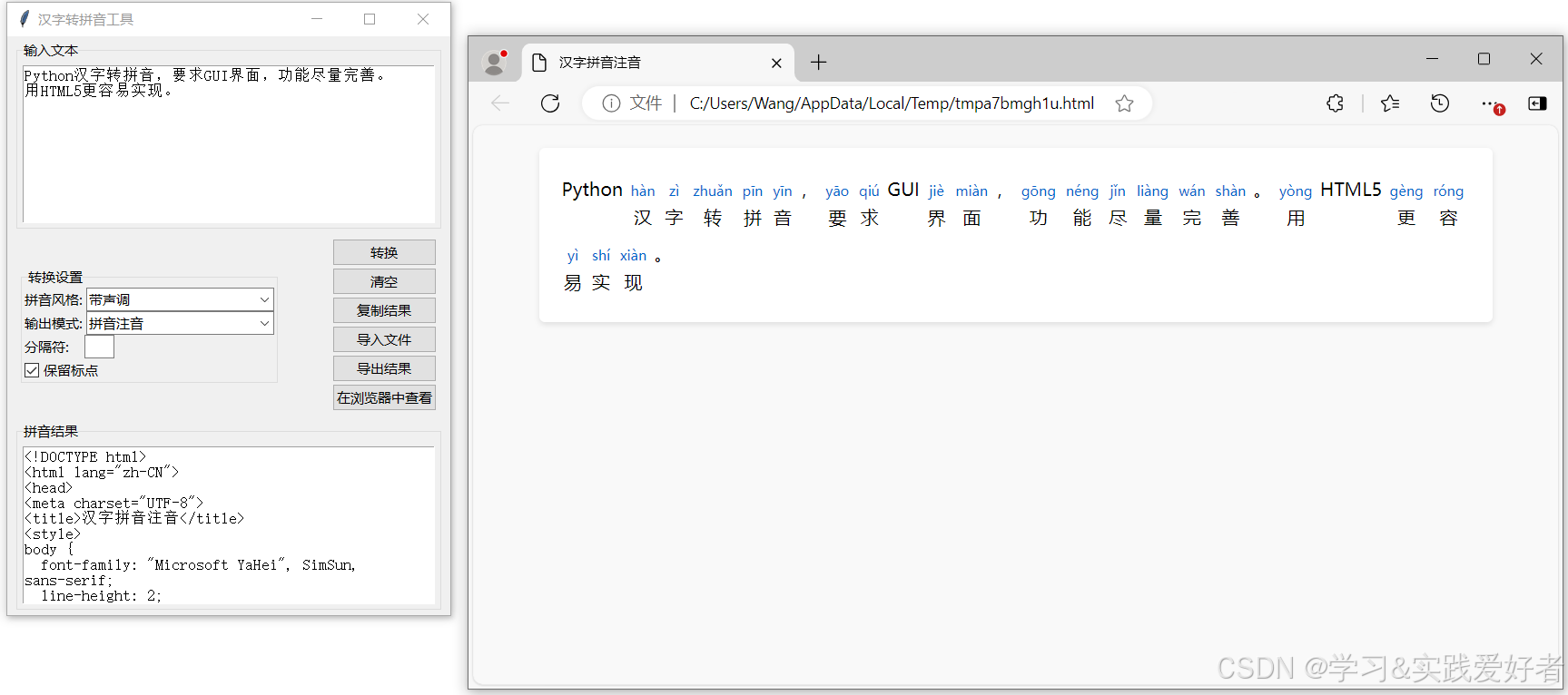
源码如下:
import tkinter as tk
from tkinter import ttk, filedialog, messagebox
from pypinyin import pinyin, Style
import pyperclip
import os
import re
import webbrowser
import tempfile
class PinyinConverter:
def __init__(self, root):
self.root = root
self.root.title("汉字转拼音工具")
self.setup_ui()
self.set_default_values()
self.temp_html_file = None
def set_default_values(self):
self.style_var.set('带声调')
self.separator_var.set(' ')
# self.handle_polyphonic_var.set(0)
self.keep_punctuation_var.set(1)
self.output_mode_var.set('普通模式')
def setup_ui(self):
# 输入区域
input_frame = ttk.LabelFrame(self.root, text="输入文本")
input_frame.grid(row=0, column=0, padx=10, pady=5, sticky='nsew')
self.input_text = tk.Text(input_frame, height=10, width=50, wrap='word')
self.input_text.pack(padx=5, pady=5, fill='both', expand=True)
# 控制面板
control_frame = ttk.Frame(self.root)
control_frame.grid(row=1, column=0, padx=10, pady=5, sticky='ew')
# 样式设置
style_frame = ttk.LabelFrame(control_frame, text="转换设置")
style_frame.pack(side=tk.LEFT, padx=5, pady=2)
# 拼音样式
ttk.Label(style_frame, text="拼音风格:").grid(row=0, column=0, sticky='w')
self.style_var = tk.StringVar()
styles = {
'带声调': Style.TONE,
'数字声调': Style.TONE3,
'无声调': Style.NORMAL
}
self.style_combobox = ttk.Combobox(
style_frame, textvariable=self.style_var,
values=list(styles.keys()), state='readonly')
self.style_combobox.grid(row=0, column=1, padx=2)
# 输出模式
ttk.Label(style_frame, text="输出模式:").grid(row=1, column=0, sticky='w')
self.output_mode_var = tk.StringVar()
modes = ['普通模式', '拼音注音']
self.mode_combobox = ttk.Combobox(
style_frame, textvariable=self.output_mode_var,
values=modes, state='readonly')
self.mode_combobox.grid(row=1, column=1, padx=2)
# 分隔符
ttk.Label(style_frame, text="分隔符:").grid(row=2, column=0, sticky='w')
self.separator_var = tk.StringVar()
ttk.Entry(style_frame, textvariable=self.separator_var, width=3).grid(row=2, column=1, sticky='w')
# 高级选项
## self.handle_polyphonic_var = tk.IntVar()
## ttk.Checkbutton(
## style_frame, text="处理多音字",
## variable=self.handle_polyphonic_var).grid(row=3, column=0, columnspan=2, sticky='w')
self.keep_punctuation_var = tk.IntVar()
ttk.Checkbutton(
style_frame, text="保留标点",
variable=self.keep_punctuation_var).grid(row=4, column=0, columnspan=2, sticky='w')
# 操作按钮
btn_frame = ttk.Frame(control_frame)
btn_frame.pack(side=tk.RIGHT, padx=5)
ttk.Button(btn_frame, text="转换", command=self.convert).pack(side=tk.TOP, fill=tk.X)
ttk.Button(btn_frame, text="清空", command=self.clear_text).pack(side=tk.TOP, fill=tk.X, pady=2)
ttk.Button(btn_frame, text="复制结果", command=self.copy_result).pack(side=tk.TOP, fill=tk.X)
ttk.Button(btn_frame, text="导入文件", command=self.import_file).pack(side=tk.TOP, fill=tk.X, pady=2)
ttk.Button(btn_frame, text="导出结果", command=self.export_result).pack(side=tk.TOP, fill=tk.X)
ttk.Button(btn_frame, text="在浏览器中查看", command=self.view_in_browser).pack(side=tk.TOP, fill=tk.X, pady=2)
# 输出区域
output_frame = ttk.LabelFrame(self.root, text="拼音结果")
output_frame.grid(row=2, column=0, padx=10, pady=5, sticky='nsew')
self.output_text = tk.Text(output_frame, height=10, width=50, wrap='word')
self.output_text.pack(padx=5, pady=5, fill='both', expand=True)
# 布局配置
self.root.columnconfigure(0, weight=1)
self.root.rowconfigure(0, weight=1)
self.root.rowconfigure(2, weight=1)
def convert(self):
try:
input_str = self.input_text.get("1.0", tk.END).strip()
if not input_str:
return
style_mapping = {
'带声调': Style.TONE,
'数字声调': Style.TONE3,
'无声调': Style.NORMAL
}
style = style_mapping[self.style_var.get()]
separator = self.separator_var.get()
keep_punctuation = bool(self.keep_punctuation_var.get())
output_mode = self.output_mode_var.get()
self.output_text.delete(1.0, tk.END)
if output_mode == '普通模式':
# 普通模式:直接输出拼音
pinyin_list = pinyin(
input_str,
style=style,
# heteronym=bool(self.handle_polyphonic_var.get()),
errors='ignore' if not keep_punctuation else lambda x: x
)
result = []
for word in pinyin_list:
selected = word[0] if word else ''
result.append(selected + separator)
result_text = ''.join(result).strip()
self.output_text.insert(tk.END, result_text)
else:
# 拼音注音模式:生成HTML
html_content = self.generate_html_with_pinyin(
input_str, style,
# handle_polyphonic=bool(self.handle_polyphonic_var.get())
)
# 在文本框中显示HTML源码
self.output_text.insert(tk.END, html_content)
# 保存HTML到临时文件,准备用浏览器查看
if self.temp_html_file:
try:
os.unlink(self.temp_html_file)
except:
pass
fd, self.temp_html_file = tempfile.mkstemp(suffix='.html')
with os.fdopen(fd, 'w', encoding='utf-8') as f:
f.write(html_content)
# 自动在浏览器中打开查看效果
messagebox.showinfo("提示", "HTML已生成,点击“在浏览器中查看”按钮可以打开浏览器查看效果")
except Exception as e:
import traceback
error_details = traceback.format_exc()
messagebox.showerror("错误", f"转换失败: {str(e)}\n\n详细信息:\n{error_details}")
def generate_html_with_pinyin(self, text, style, handle_polyphonic=False):
"""生成带有拼音注音的HTML文档"""
html_content = [
'<!DOCTYPE html>',
'<html lang="zh-CN">',
'<head>',
'<meta charset="UTF-8">',
'<title>汉字拼音注音</title>',
'<style>',
'body {',
' font-family: "Microsoft YaHei", SimSun, sans-serif;',
' line-height: 2;',
' margin: 20px;',
' background-color: #f9f9f9;',
'}',
'ruby {',
' display: inline-flex;',
' flex-direction: column-reverse;',
' text-align: center;',
' margin: 0 2px;',
'}',
'rt {',
' font-size: 0.7em;',
' color: #0066cc;',
' line-height: 1.2;',
' text-align: center;',
' font-weight: normal;',
'}',
'.container {',
' background-color: white;',
' padding: 20px;',
' border-radius: 5px;',
' box-shadow: 0 2px 5px rgba(0,0,0,0.1);',
' max-width: 800px;',
' margin: 0 auto;',
'}',
'.non-chinese {',
' display: inline-block;',
'}',
'</style>',
'</head>',
'<body>',
'<div class="container">'
]
# 将文本分割成连续的汉字段落和非汉字段落
segments = []
current_segment = ""
current_type = None # 0 for non-Chinese, 1 for Chinese
for char in text:
is_chinese = '\u4e00' <= char <= '\u9fff'
char_type = 1 if is_chinese else 0
if current_type is None:
current_type = char_type
current_segment = char
elif current_type == char_type:
current_segment += char
else:
segments.append((current_segment, current_type))
current_segment = char
current_type = char_type
if current_segment:
segments.append((current_segment, current_type))
# 处理每个段落
for segment_text, is_chinese in segments:
if is_chinese:
# 处理汉字段落
py_results = pinyin(
segment_text,
style=style,
# heteronym=handle_polyphonic
)
# 为每个汉字创建ruby标签
for i, (char, py) in enumerate(zip(segment_text, py_results)):
py_text = py[0] if py else ''
html_content.append(f'<ruby>{char}<rt>{py_text}</rt></ruby>')
else:
# 处理非汉字段落
html_content.append(f'<span class="non-chinese">{segment_text}</span>')
# 完成HTML
html_content.extend([
'</div>',
'</body>',
'</html>'
])
return '\n'.join(html_content)
def view_in_browser(self):
"""在浏览器中打开HTML文件"""
if not self.temp_html_file or not os.path.exists(self.temp_html_file):
if self.output_mode_var.get() == '拼音注音':
self.convert() # 重新生成HTML
else:
messagebox.showinfo("提示", "请先切换到拼音注音模式并执行转换")
return
if self.temp_html_file and os.path.exists(self.temp_html_file):
webbrowser.open('file://' + os.path.abspath(self.temp_html_file))
else:
messagebox.showerror("错误", "HTML文件不存在或无法访问")
def clear_text(self):
self.input_text.delete(1.0, tk.END)
self.output_text.delete(1.0, tk.END)
# 删除临时HTML文件
if self.temp_html_file and os.path.exists(self.temp_html_file):
try:
os.unlink(self.temp_html_file)
self.temp_html_file = None
except:
pass
def copy_result(self):
result = self.output_text.get(1.0, tk.END).strip()
if result:
pyperclip.copy(result)
messagebox.showinfo("成功", "已复制到剪贴板")
def import_file(self):
file_path = filedialog.askopenfilename(
filetypes=[("文本文件", "*.txt"), ("所有文件", "*.*")])
if file_path:
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
self.input_text.delete(1.0, tk.END)
self.input_text.insert(tk.END, content)
except Exception as e:
messagebox.showerror("错误", f"文件读取失败: {str(e)}")
def export_result(self):
result = self.output_text.get(1.0, tk.END).strip()
if not result:
return
if self.output_mode_var.get() == '拼音注音':
default_ext = ".html"
filetypes = [("HTML文件", "*.html"), ("所有文件", "*.*")]
else:
default_ext = ".txt"
filetypes = [("文本文件", "*.txt"), ("所有文件", "*.*")]
file_path = filedialog.asksaveasfilename(
defaultextension=default_ext,
filetypes=filetypes)
if file_path:
try:
with open(file_path, 'w', encoding='utf-8') as f:
f.write(result)
messagebox.showinfo("成功", "文件保存成功")
except Exception as e:
messagebox.showerror("错误", f"文件保存失败: {str(e)}")
if __name__ == "__main__":
root = tk.Tk()
app = PinyinConverter(root)
root.mainloop()
特别说明,需要将拼音添加到汉字上面时,用python实现比HTML5+JavaScript实现繁琐。在下一篇博文中用HTML5+JavaScript实现汉字转拼音工具。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











