






引言
在数据库设计中,选择适当的主键类型对于数据的存储和查询效率至关重要。在MySQL中,有些开发者倾向于使用UUID(Universally Unique Identifier)或者雪花ID作为主键,以确保数据的唯一性。然而,这种做法并不总是推荐的,因为它们在性能、存储空间和索引效率等方面存在一些问题。本文将探讨在MySQL中不推荐使用UUID或者雪花ID作为主键的原因,并与其他主键类型进行差异化对比。
一、什么是UUID?
UUID 是指Universally Unique Identifier,翻译为中文是通用唯一识别码,UUID 的目的是让分布式系统中的所有元素都能有唯一的识别信息。如此一来,每个人都可以创建不与其他人冲突的 UUID,就不需考虑数据库创建时的名称重复问题。
UUID 是由一组32位数的16进制数字所构成,是故 UUID 理论上的总数为1632=2128,约等于3.4 x 10123。
也就是说若每纳秒产生1百万个 UUID,要花100亿年才会将所有 UUID 用完
二、什么是雪花ID?
snowflake是Twitter开源的分布式ID生成算法,结果是64bit的Long类型的ID,有着全局唯一和有序递增的特点。
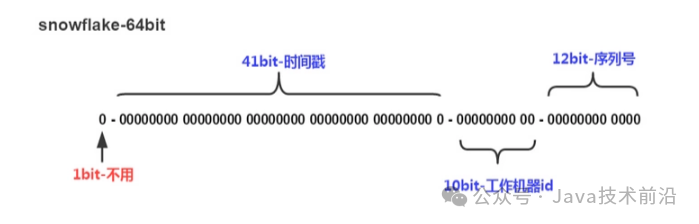
最高位是符号位,因为生成的 ID 总是正数,始终为0,不可用。
41位的时间序列,精确到毫秒级,41位的长度可以使用69年。时间位还有一个很重要的作用是可以根据时间进行排序。10位的机器标识,10位的长度最多支持部署1024个节点。12位的计数序列号,序列号即一系列的自增ID,可以支持同一节点同一毫秒生成多个ID序号,12位的计数序列号支持每个节点每毫秒产生4096个ID序号。
三、什么是MySql自增ID?
自增ID是在设计表时如果将id字段的值设置为自增的形式也就是AUTO_INCREMENT,那么当插入一行数据时就无需指定id,数据表会根据前一个id值+1进行填充。指定了AUTO_INCREMENT的列必须要建索引,一般把ID作为主键,这样系统会自动为ID建立索引。
自增id的好处
- 增加记录时,可以不用指定id字段,不用担心主键重复问题。
- 数据库自动编号,速度快,而且是增量增长,按顺序存放,对于检索非常有利;
- 数字型,占用索引空间小,范围查找与排序友好,在程序中传递也方便;
- 避免像UUID这样随机字符串带来的页分裂问题等
页分裂问题:
一页总要被存满,然后新开一页继续,这种行为被称作页分裂。何时开辟新的页,mysql规定了一个分裂因子,达到页存储空间的15/16则存到下一页。页分裂的存在可能极大影响性能维护索引的性能。通常提倡的是,设定一个无意义的整数自增索引,有利于索引存储
如果非自增或不是整数索引,如非自增整数、类似MD5的字符串,以他们作为索引值时,因为待插入的下一条数据的值不一定比上一条大,甚至比当前页所有值都小,需要跑到前几页去比较而找到合适位置,InnoDB无法简单的把新行插入到上一行后面,而找到并插入索引后,可能导致该页达到分裂因子阀值,需要页分裂,进一步导致后面所有的索引页的分裂和排序,数据量小也许没什么问题,数据量大的话可能会浪费大量时间,产生许多碎片。
自增id的坏处
- 不具有连续性,表中auto_increment最大值被删除,将不会被重用。就是说会跳号(如果设定的auto_increment_increment是1,那么下一次插入的id值将会从被删除的最大值算起,也就是被删除的最大值+1)
- 历史数据表的主键id会与数据表的id重复,两张自增id做主键的表合并时,id会有冲突,但如果各自的id还关联了其他表,这就很不好操作。
- 很难处理分布式存储的数据表,尤其是需要合并表的情况下
- 在系统集成或割接时,如果新旧系统主键不同是数字型就会导致修改主键数据类型,这也会导致其它有外键关联的表的修改,后果同样很严重;
当自增id用完了怎么办?
自增id的数据上限和受主键类型的影响,当自增id超过最大值,就会提示主键冲突,所以建议根据业务需求设置主键数据类型,如果超过int 数值范围,可以考虑bigint类型(2^64-1)。当隐性的row_id用完,数据库不会产生错误,它会重新从0开始覆盖之前的数据,这样会导致数据丢失。
代码案例
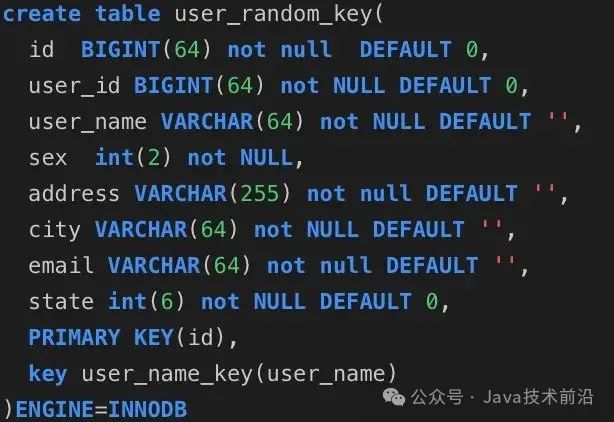
我们首先来建立三张表分别是user_auto_key,user_uuid,user_random_key,分别表示自动增长的主键,uuid作为主键,随机key作为主键,其它我们完全保持不变.
id自增的表:
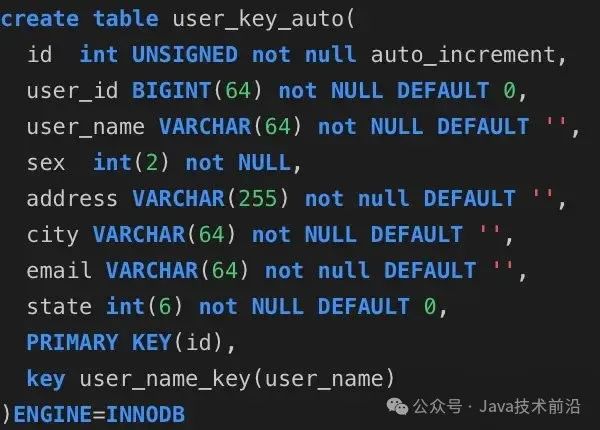
主键是uuid表
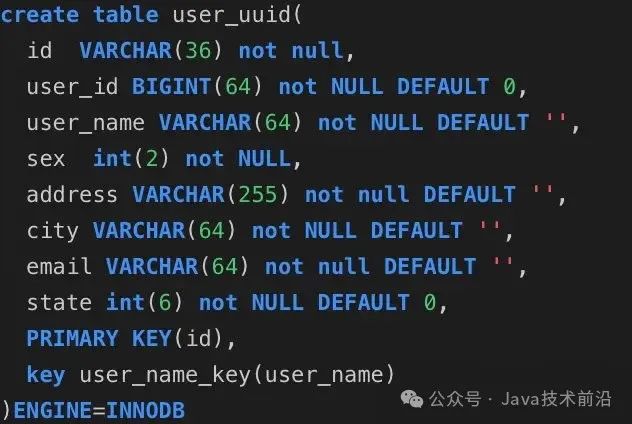
随机主键表
代码演示
技术框架未Spring Boot框架,结合JDBC Template简化数据库操作,JUnit用于执行单元测试以验证功能正确性。为了确保测试的真实性和数据多样性,采用Hutool工具库动态生成随机数据(包括姓名、邮箱、地址等),模拟真实应用场景。此程序在指定测试数据库环境中,批量执行INSERT操作,通过记录和分析操作时间,综合评估数据插入的效率。
执行后效果如图:
id自增表结果如下:
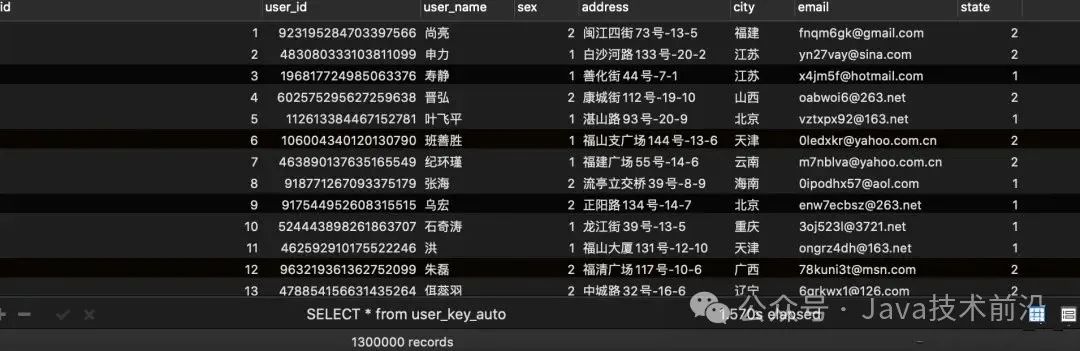
id为uuid为主键表结果如下:
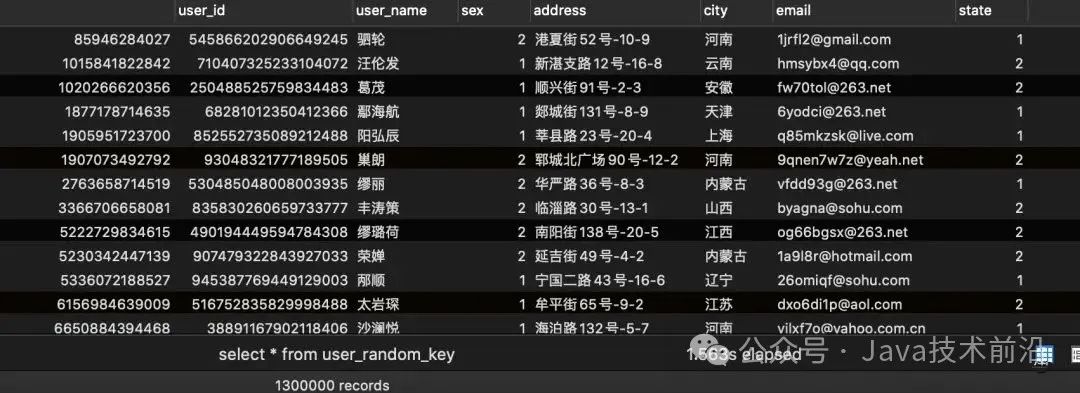
id为雪花算法为主键表结果如下:
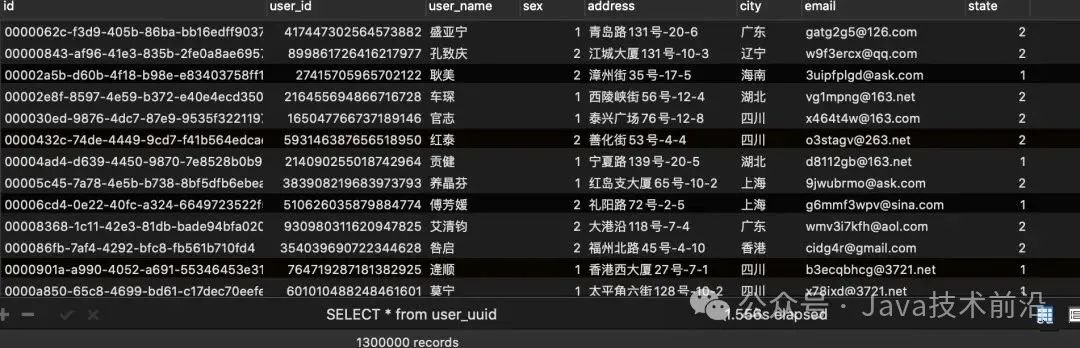
uuid主键和自增id的主键的索引结构对比
使用自增id的内部结构
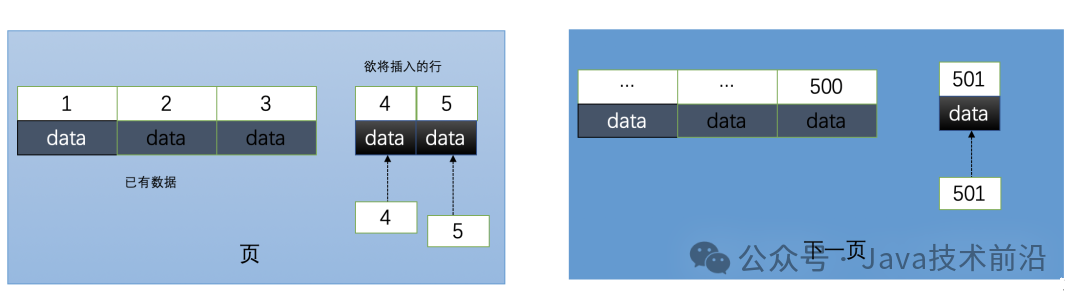
- 索引效率:
- 顺序性:自增ID是顺序的,InnoDB能够高效地将新记录插入到索引的末尾,减少了页分裂和碎片的产生。这意味着数据在物理存储上也是连续的,从而提高了查询和插入的效率。
- 填充率:由于数据是按照顺序插入的,InnoDB能够近乎于顺序地填满每个索引页,提高了页面的最大填充率,减少了空间的浪费。
- 定位与寻址:新插入的行一定会在原有的最大数据行下一行,MySQL定位和寻址很快,不需要为计算新行的位置而做出额外的消耗。
- 性能影响:
- 锁争用:在高并发的负载下,InnoDB在按主键进行插入时可能会造成锁争用,因为所有的插入都发生在主键的上界,这可能导致间隙锁竞争。
- 泄露信息:自增ID容易被外部爬取,从而暴露业务增长信息,可能对企业的经营情况造成潜在风险。
使用uuid为主键的索引内部结构
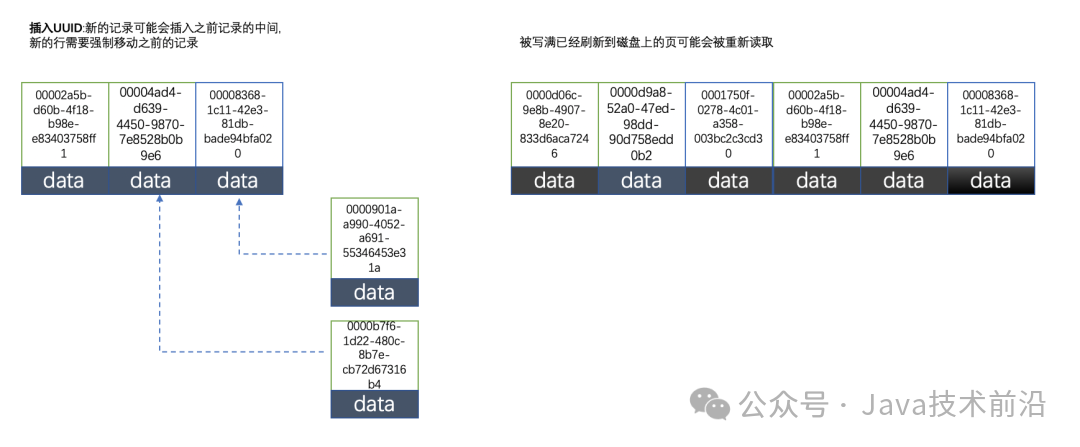
- 索引效率:
- 无序性:UUID是随机的,没有规律可言,因此InnoDB无法总是将新行插入到索引的最后。这导致InnoDB需要为新行寻找新的合适位置并分配新的空间,增加了额外的操作。
- 随机IO:由于UUID的随机性,写入的目标页可能尚未加载到缓存中,或者已经被刷新到磁盘并从缓存中移除。这导致InnoDB在插入之前不得不先从磁盘读取目标页到内存中,增加了随机IO的次数。
- 页分裂:由于写入是乱序的,InnoDB需要频繁进行页分裂操作以为新行分配空间。页分裂不仅移动了大量的数据,还降低了索引的紧凑性,增加了碎片的产生。
- 性能影响:
- 插入效率:由于上述的随机IO和页分裂问题,UUID作为主键的表在插入操作上的性能通常低于自增ID作为主键的表。
- 优化需求:在将随机值(如UUID)载入到聚簇索引后,有时需要进行OPTIMIZE TABLE操作以重建表并优化页的填充。这将消耗额外的时间和资源。
总结
- 自增ID:适用于大多数需要高效查询和插入操作的场景。它简单易用,索引效率高,但需要注意在高并发下的锁争用问题和信息泄露风险。
- UUID:适用于需要全局唯一标识符的场景,特别是在分布式系统中。然而,其随机性导致了较低的索引效率和较高的插入成本。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









