






SQL优化对于数据库应用程序的性能、稳定性、可靠性、数据质量、开发效率和管理效率都具有重要意义,以下是给大家分享的一些技巧!
1.获取正确的执行计划
1.1 awr执行计划
1.2 share pool计划
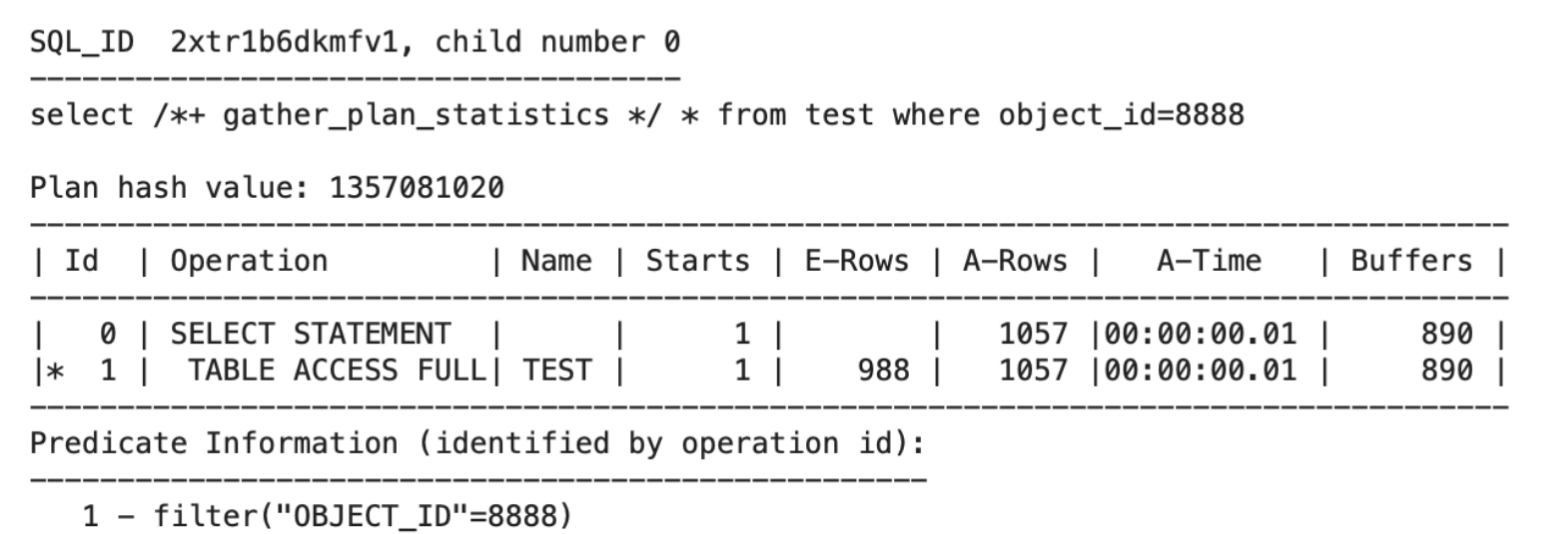
1.3.真实的资源消耗
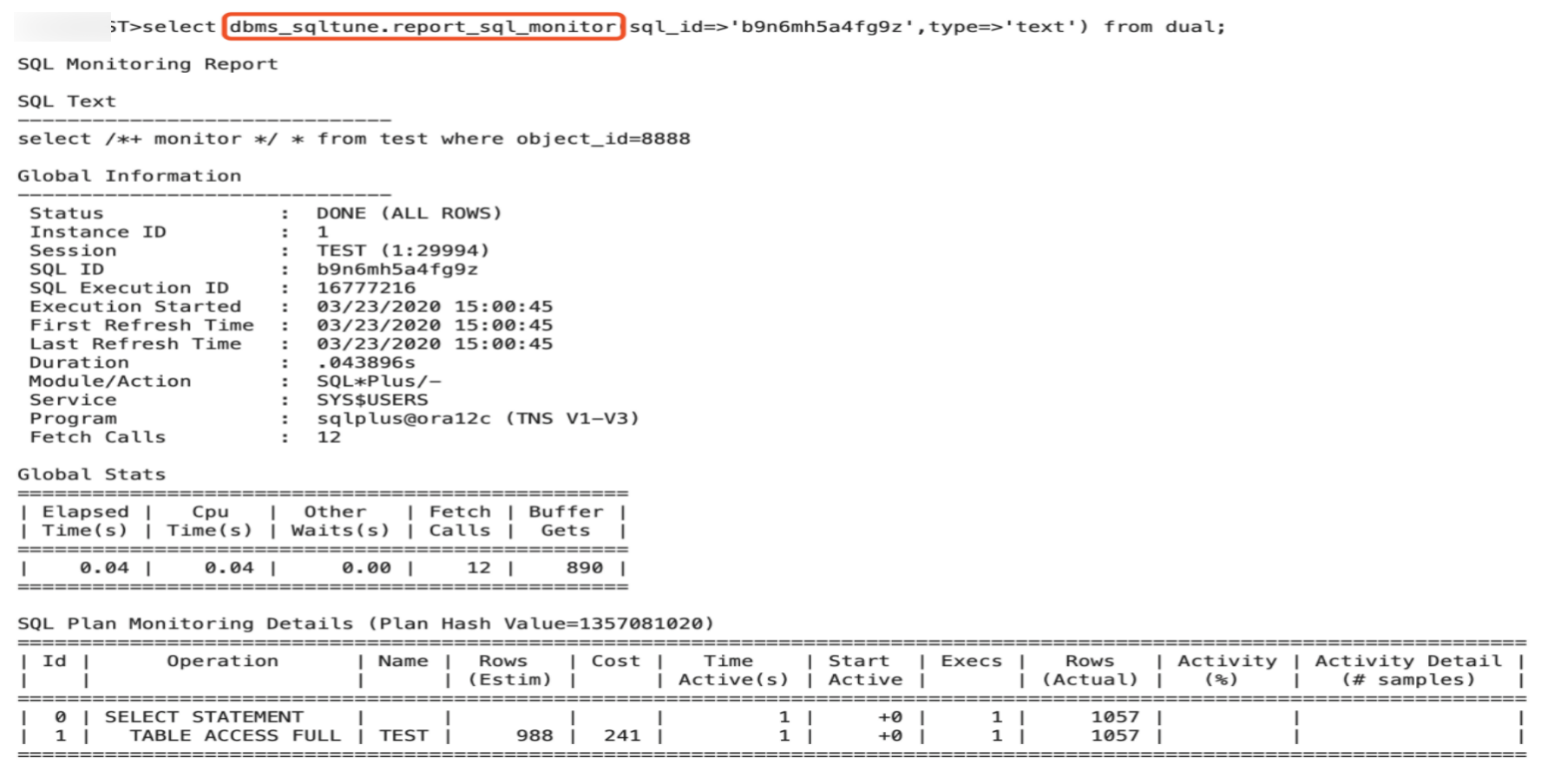
2.索引的应用
2.1 如何建索引
2.2 那种情况不走索引
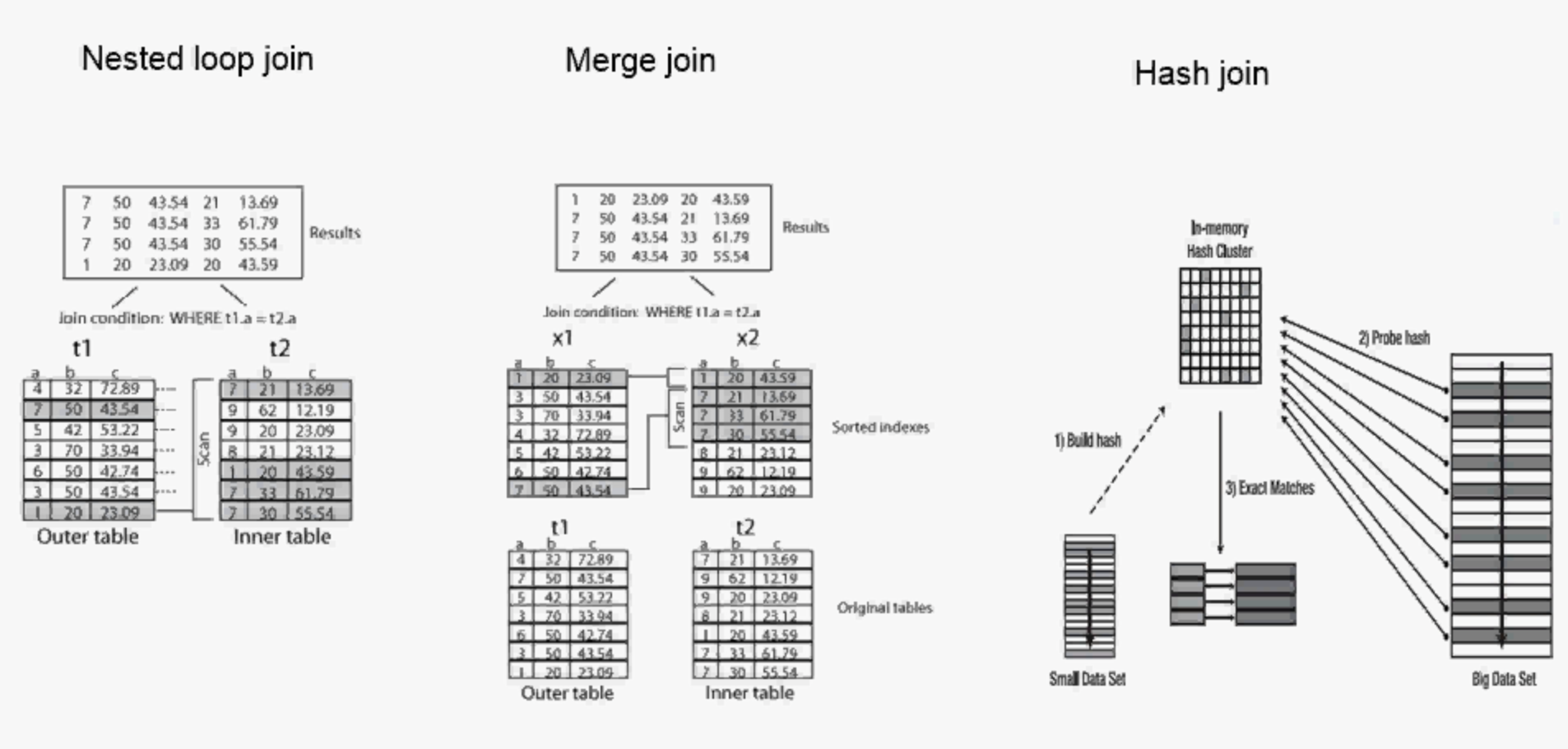
2.3 表连接
1.Nested Loops:每读一条驱动表的数据,就根据连接条件去被驱动表中查找对应的数据,直到读完驱动表所有数据为止。
一般用于驱动表小,被驱动表较大,且关联字段有索引的情况。
2.Hash Join:首先在内存根据连接条件生成一张hash表,然后再去扫描被驱动表,并将每行与hash表对比,找到所有匹配的行。
一般用于两个大表关联、查询小表大部分数据、相同数量级的表关联。
3.Sort Merge Join:将两个表的数据分别全部读取出来并排序,然后再根据连接条件合并。
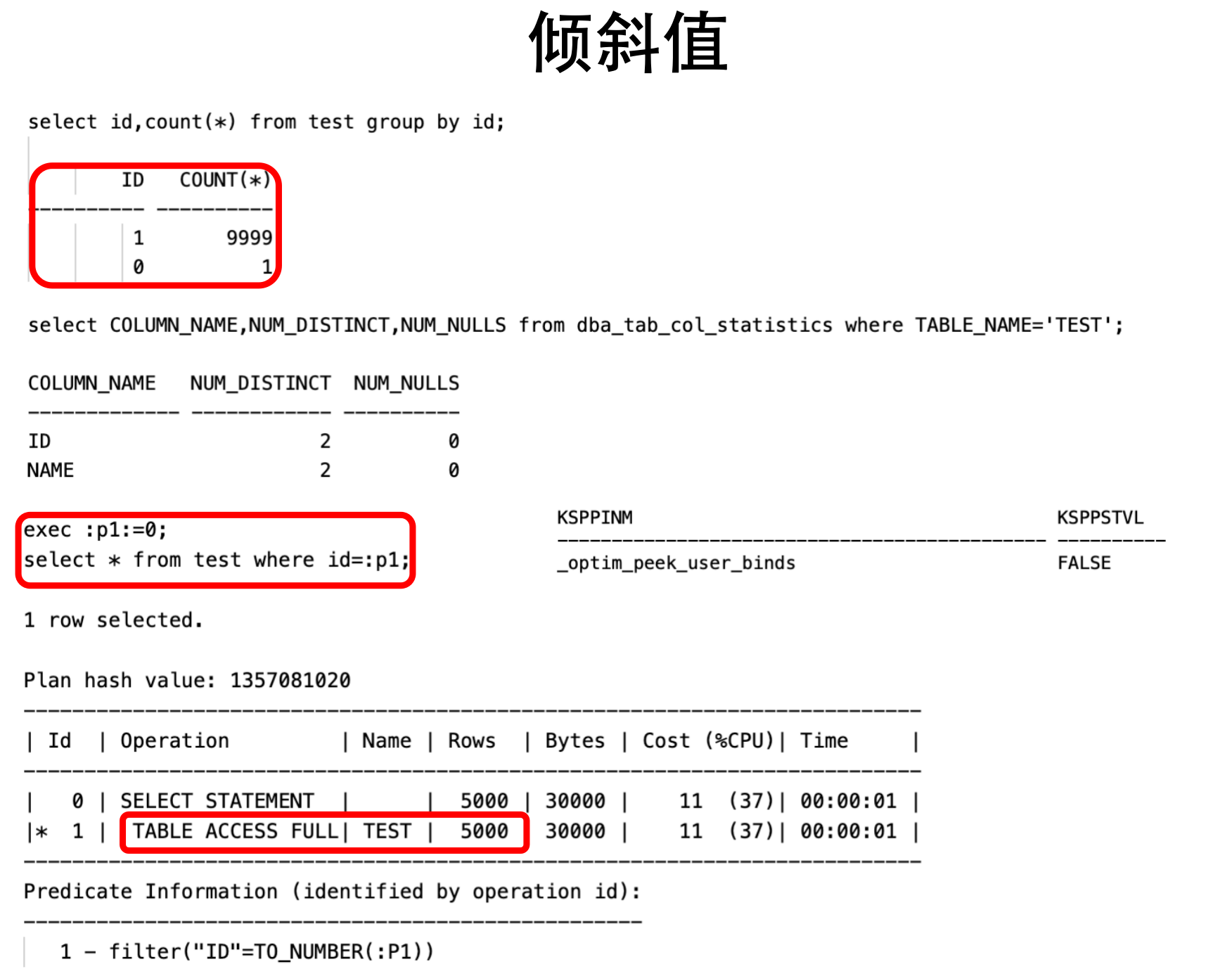
3.绑定变量
4.统计信息
该何时收集统计信息呢?
很难用一种收集策略而适合所有的情况。但对于一些有代表性的对象,我们可以制定相对更适合的收集策略。
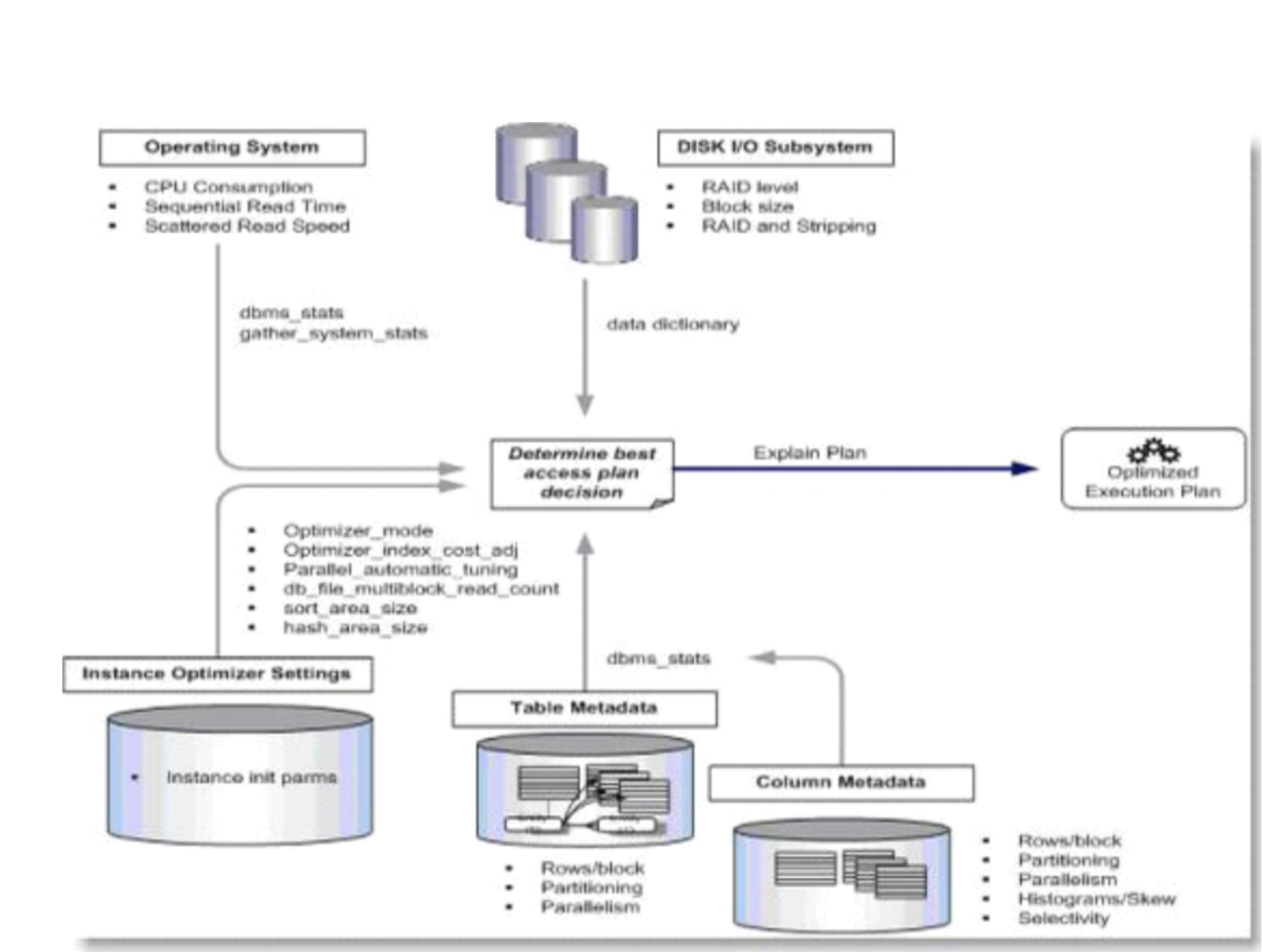
一、针对每天规律变化的表(插入的数据量和数据特征基本近似)
建议策略:使用数据库的自动收集任务。或者在收集了代表性的统计信息后,将该表的统计信息锁定,不再收集。但对于会列中的最大值或最小值出现变化,且该列还会出现在WHERE子句中时,就不适用锁定的方法了。
二、针对临时或每特定时间使用一次的中间表
建议策略:建议在完成数据准备后(通常是大量的插入或更新后),手动做一次统计信息的收集。或者在相关SQL中加入动态采样的提示(/*+ dynamic_sampling(<表别名> <采样级别>) */)。若可以确定有最适合的执行计划,可以在数据库层面做绑定或在SQL代码中加入提示来固定执计计划。
三、数据会出现大幅变化(指一段时间内,插入,更新和删除的行较多)
建议策略:若相关SQL较少(使用绑定变量会减少不一样SQL的数量),可以考虑使用动态采样的方法。若相关SQL较多,但绝大多数SQL可以在统计信息不再更新后,仍能生成正确的执行计划,那么可以考虑将相关表上的统计信息锁定,并针对极少数对统计信息的准确性敏感(比如前边提到的谓词越界的情况)的SQL做执行计划的绑定或固定。
总结
通过优化SQL语句,可以提高数据库的响应速度,降低系统资源的消耗,从而提升整体应用性能!优化是一个长期的持续的过程,分析TOP SQL、分析AWR报告、定期对数据库进行巡检至关重要!















 3519
3519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









