







 本文介绍了一种名为MoCA的新型神经网络模型,它借鉴了生物大脑中的'grandmothercell'原理,通过记忆原型和注意力机制在生成对抗网络中增强图像生成质量。文章详细阐述了记忆力学习、概念注意力以及空间上下文注意力的融合,展示了如何提高模型鲁棒性和生成图像的清晰度。
本文介绍了一种名为MoCA的新型神经网络模型,它借鉴了生物大脑中的'grandmothercell'原理,通过记忆原型和注意力机制在生成对抗网络中增强图像生成质量。文章详细阐述了记忆力学习、概念注意力以及空间上下文注意力的融合,展示了如何提高模型鲁棒性和生成图像的清晰度。
肯定很多人都看过了吧,也发了很多笔记,但是我还是想写一篇自己的。
这篇文章结合医学,眼前一亮。
原文链接:https://openreview.net/pdf?id=lY0-7bj0Vfz
知乎同步更新:id为cocotaini
摘要:
猕猴的大脑视觉皮质层的表层有神经编码,这种编码复杂、多样、稀疏。引人联想到计算机语言中的grandmother cell。本文假设这些单元作为记忆原型,在大脑生成图像的过程中,进行特征处理。这些记忆力原型通过聚类形成,并通过一种注意力操作来应用。本文提出的该方法叫做MoCA(Memory Concept Attention),提高少样本图像生成质量。本方法,提高了生成质量并由可解释的视觉概念聚类,提高模型的鲁棒性。
1 概述
神经生物学中有一个现象,一些复杂的神经元,对于他们更偏向的模型会表现出更强烈的反射。这些神经元的高度选择性表示,他们类似特定模型检测器。因为这种对于复杂刺激表现出的选择性,这些神经元的数量就非常稀疏,4~6:1000的比例。本文将高选择性、稀疏响应的特征检测器成为“grandmother cell”,他们对特定原型有明确的编码方式,一个原型对应一个神经元的稀疏聚类而不只是一个神经元。
本文假设“grandmother neurons”作为原型记忆力先验,调节图像生成过程。这些先验知识让这个过程通过当时的空间上下文进行,运用原型记忆力进行不断学习和积累。“grandmother cell”在记忆注意力过程中作为结构化概念先验,进行图像生成。
MoCA模块,在GAN网络中的每一层之前都插入一个,作为每层的预置生成器。
本文实验backbone:sota StyleGAN2和新网络FastGAN。
另外,本文发现在测试阶段,带有MoCA的生成器可以在一定程度上,抑制噪声。说明在生成阶段使用结构化记忆力先验可以增加模型的鲁棒性。
2 相关工作
视觉概念学习:
视觉概念就是中级的语义特征,有效解决误分类问题。
自注意力:
现在的自注意力GAN网络只局限于使用桐言的图像的上下文信息来调节激活。
原型记忆力机制:
本文在low-level使用memory bank,来存储原型。
少样本原型学习:
从训练集中生成不同原型,在测试中使用。
3 方法
本文主要贡献是引入基于原型记忆力的调节模块,从而提高GAN的生成器。前面的网络层的激活在两个注意力过程中被修改:(1)MoCA的上下文调节(2)自注意力的空间上下文调节。这个模块把GAN的feature map作为输入,结合以上两个机制的结果,来调节后续处理过程。
模型流程概括如图1。
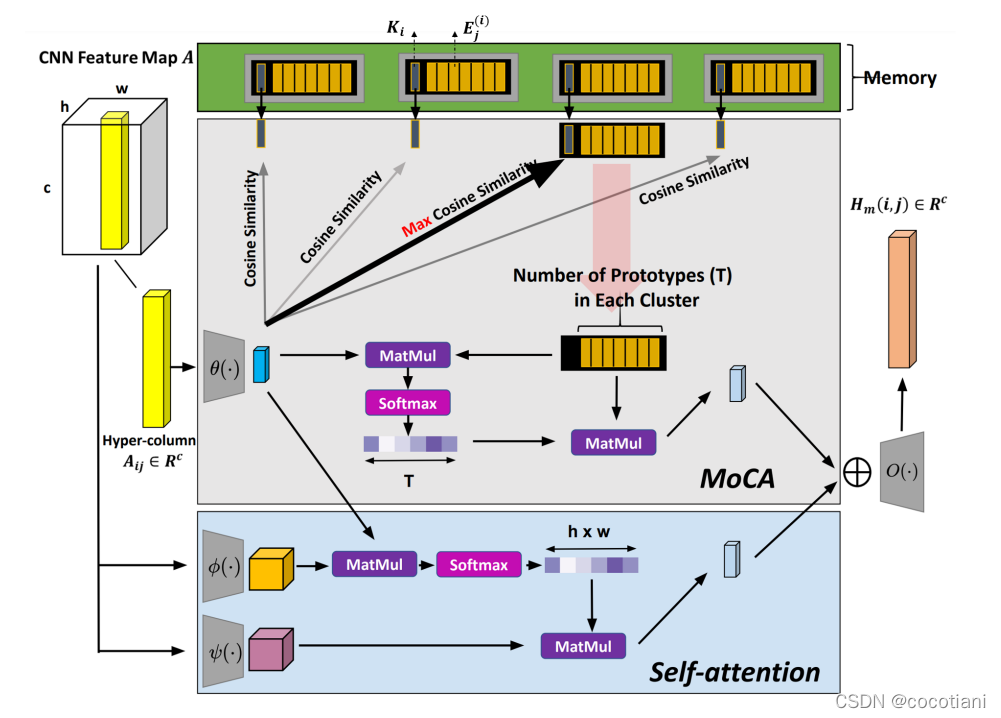
图1:在MoCA中,激活向量A作为输入,首先通过1x1卷积降至低维空间,用来选择最接近的予以单元。选出的单元会将在他的聚类中的原型记忆力单元加入到MoCA中,生成一种调节机制,通过一种1x1网络O从内置空间映射回特征空间;在自注意力中,整张特征图A通过两个相关的1x1卷积核,转化成了键值对-->结合query向量-->映射回特征空间。最后,通过两种途径得到的输出整合到一起,形成了下一层的输入。
本文用MoCA层的输入表示一个特定层的激活A。输出提供了一个调节函数H,用来更新激活A。使用1x1卷积将A降维到低维空间,使得A可以更灵活的进行调节。
3.1 原型记忆力学习
本文的原型概念记忆力被分为语义单元和原型单元。如下图所示,每个语义单元是一个原型单元的聚类的均值。
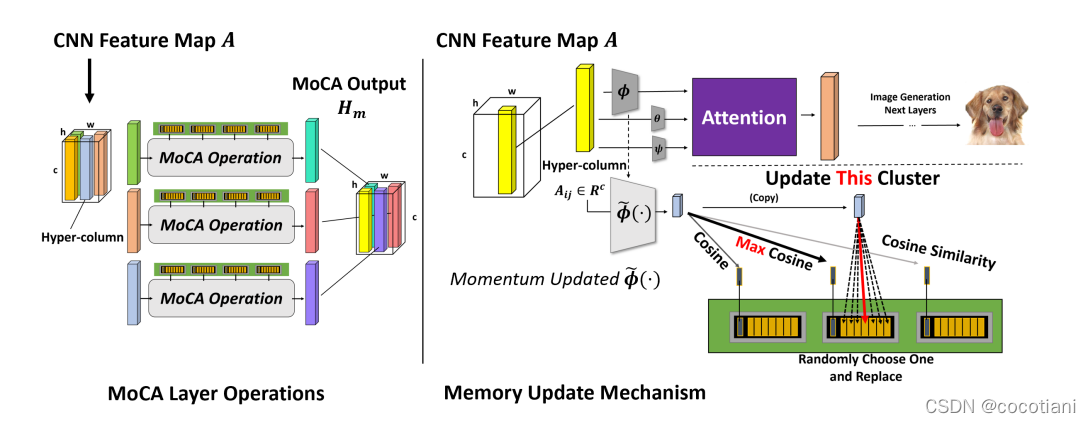
假设,记忆力P包含M个语义单元,对于每个语义单元Ki,有T个原型单元Eij,存储在记忆单元中,并与Ki关联,Ki是存储的原型单元的均值。这些原型单元来自之前迭代的特征图,这些特征图通过上下文编码器进行动态更新,在每次训练迭代结尾在记忆力中进行更新。
每个激活,在降维之后,在特征途中都被分配到距离最近的语义聚类中,取代了一个在该聚类的memory bank已有的原型单元。使用随机取代机制防止过拟合。
3.2 记忆力概念注意力机制
本文的记忆力是一种高速缓存,他能缓存在整个训练集和训练不同阶段产生的特征图中的超列激活模式。通过语义单元,可以规划更多信息到最终的激活中,但是还可以保留很多数据的有效性。
该过程是,一个激活向量a选出最近的语义单元Ki,回退到记忆力中找出相关的原型单元矩阵Ei。Ei中的每一列j都是一个原型单元Eij。第二步,用Ei注意a。先计算a和Ei的相似指数s;对s进行非线性softmax归一化,获得归一化注意力权重β。
利用权重β,从记忆力hm中为激活a建立回退的信息。对于每个batch中的每个图像的每个空间位置都进行同样的对a的操作,获得矩阵Hm。
3.3 空间上下文注意力
记忆力先验很重要,但是空间上下文信息对于激活调节来说也很重要。本文还使用了非本地的网络对相同的层使用了空间上下文调节。特别的,作者首先计算了降维后的两个A之间的相近关系映射图,记作S。S的每一行都通过softmax进行归一化,一边计算稀疏注意力权重。最后获得空间上下文调节张量Hs。
3.4 两种调节的结合
Hm和Hs元素对应相加,获得H。通过1x1卷积,转化回到原始特征空间。可学习参数γ作为H的权重相乘,和输入的激活A相加,用来更新A,成为下一层生成器的输入。
4 实验
本文是GAN图像生成,略


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









