






-
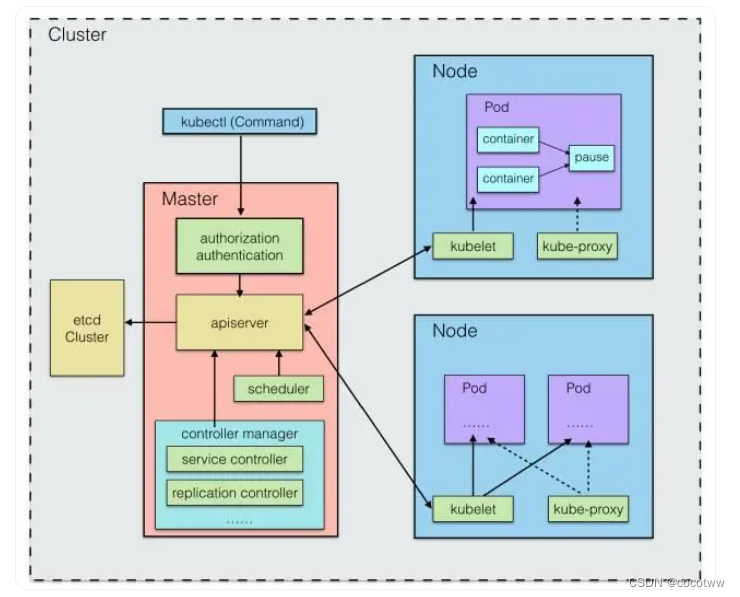
Node 节点(物理主机或虚拟机),它们共同组成一个分布式集群,并且这些节点中会有一个 Master 节点,由它来统一管理 Node 节点。
-
Pod ,在 K8S 中,Pod 是最基本的操作单元,它与 docker 的容器有略微的不同,因为 Pod 可能包含一个或多个容器(可以是 docker 容器),这些内部的容器是共享网络资源的,即可以通过 localhost 进行相互访问。
-
Volume,Volume表示存储卷,Pod访问文件系统的抽象层,具体的后端存储可以是本地存储、NFS网络存储、云存储以及分布式存储等。
- 声明在Pod中容器可以访问的文件系统;
- 可以被挂载在Pod中一个或多个容器的指定路径下;
- 支持多种后端储存。
-
namespace ,命名空间是一种虚拟的集群划分,允许在同一集群内部创建多个虚拟集群。不同命名空间中的资源可以具有相同的名称,因为它们在不同的命名空间中是唯一的。
-
Deployment(部署),Deployment是一种Kubernetes资源,用于定义和管理Pod的副本数以及更新策略。Deployment确保指定数量的Pod副本在集群中运行,并可以进行滚动更新等操作。
-
Service(服务),Service是用于公开一个或多个Pod的网络终结点的抽象。它提供了一个稳定的网络地址,以便其他服务可以通过该地址与Pod通信。Service通过标签选择器与特定的Pod关联,从而将流量引导到这些Pod。
Namespace包含多个Deployment。每个Deployment创建一个或多个Pod,而Service通过标签选择器与这些Pod关联,使外部或其他服务可以通过Service的稳定网络地址访问相关Pod。这样,Deployment负责管理Pod的生命周期,而Service负责提供稳定的网络入口。
-
kube-apiserver 进程,它提供了集群管理的 API 接口,是集群内各个功能模块之间数据交互和通信的中心枢纽,并且它页提供了完备的集群安全机制。
-
kubelet 组件,在 Node 节点上,使用 K8S 中的 kubelet 组件,在每个 Node 节点上都会运行一个 kubelet 进程,它负责向 Master 汇报自身节点的运行情况,如 Node 节点的注册、终止、定时上报健康状况等,以及接收 Master 发出的命令,创建相应 Pod。
-
pause 容器,关于 Pod 内是如何做到网络共享的,每个 Pod 启动,内部都会启动一个 pause 容器(google的一个镜像),它使用默认的网络模式,而其他容器的网络都设置给它,以此来完成网络的共享问题。
-
kube-scheduler ,整个调度过程通过执行一些列复杂的算法最终为每个 Pod 计算出一个最佳的目标 Node,该过程由 kube-scheduler 进程自动完成。常见的有轮询调度(RR)。当然也有可能,我们需要将 Pod 调度到一个指定的 Node 上,我们可以通过节点的标签(Label)和 Pod 的 nodeSelector 属性的相互匹配,来达到指定的效果。
-
etcd,从上面的 Pod 调度的角度看,我们得有一个存储中心,用来存储各节点资源使用情况、健康状态、以及各 Pod 的基本信息等,这样 Pod 的调度来能正常进行。
在 K8S 中,采用 etcd 组件 作为一个高可用强一致性的存储仓库,该组件可以内置在 K8S 中,也可以外部搭建供 K8S 使用。
集群上的所有配置信息都存储在了 etcd,为了考虑各个组件的相对独立,以及整体的维护性,对于这些存储数据的增、删、改、查,统一由 kube-apiserver 来进行调用,apiserver 也提供了 REST 的支持,不仅对各个内部组件提供服务外,还对集群外部用户暴露服务。 -
kubectl 命令行工具,外部用户可以通过 REST 接口,或者 kubectl 命令行工具进行集群管理,其内在都是与 apiserver 进行通信。
-
Deployment,在kubernetes中,Pod是最小的控制单元,但是kubernetes很少直接控制Pod,一般都是通过Pod控制器来完成的。Pod控制器用于pod的管理,确保pod资源符合预期的状态,当pod的资源出现故障时,会尝试进行重启或重建pod。
-
kube-proxy,每个节点上会启动一个 kube-proxy 进程,由它来负责服务地址到 Pod 地址的代理以及负载均衡等工作。
-
Replication Controller ,既然知道了服务是由 Pod 组成的,那么服务的扩容也就意味着 Pod 的扩容。通俗点讲,就是在需要时将 Pod 复制多份,在不需要后,将 Pod 缩减至指定份数。K8S 中通过 Replication Controller 来进行管理,为每个 Pod 设置一个期望的副本数,当实际副本数与期望不符时,就动态的进行数量调整,以达到期望值。期望数值可以由我们手动更新,或自动扩容代理来完成。
-
kube-controller-manager,我们知道了 ectd 是作为集群数据的存储中心, apiserver 是管理数据中心,作为其他进程与数据中心通信的桥梁。
而 Service Controller、Replication Controller 这些统一交由 kube-controller-manager 来管理,kube-controller-manager 作为一个守护进程,每个 Controller 都是一个控制循环,通过 apiserver 监视集群的共享状态,并尝试将实际状态与期望不符的进行改变。
关于 Controller,manager 中还包含了 Node 节点控制器(Node Controller)、资源配额管控制器(ResourceQuota Controller)、命名空间控制器(Namespace Controller)等。















 1715
1715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









